把Agent丢入1000+文件:人大CoDA-Bench揭示Code Agent瓶颈
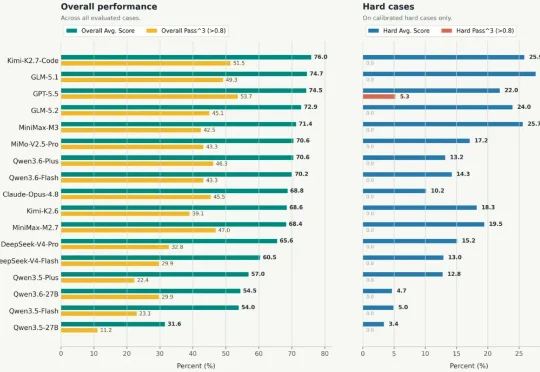
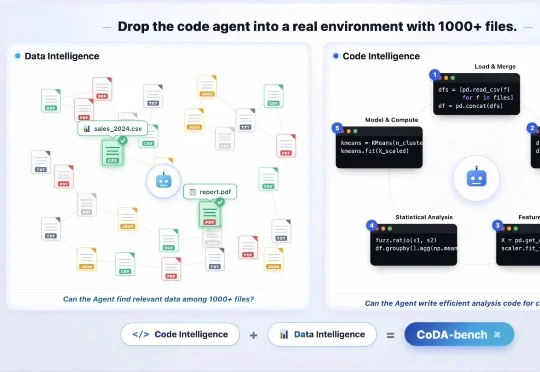
把Agent丢入1000+文件:人大CoDA-Bench揭示Code Agent瓶颈中国人民大学的研究团队提出 CoDA-Bench,联合评估 Agent 的 Code Intelligence + Data Intelligence。该基准首次把 Code Agent 放进包含 1000 + 数据文件的复杂环境下,要求模型先自主探索文件系统、找到相关数据,再编写代码完成分析。实验显示,即使当前表现最好的系统,在 CoDA-Bench 上执行准确率也只有 61.1%;
来自主题: AI技术研报
9473 点击 2026-07-04 10:51