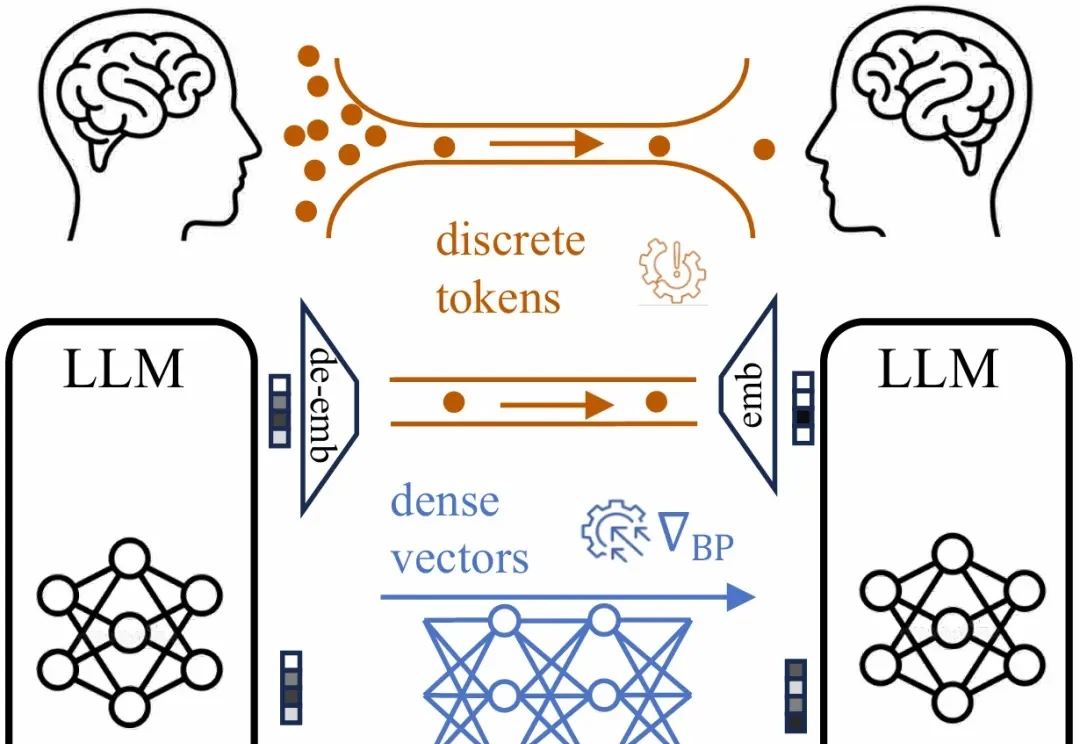
ICML 2026 | 清华姚权铭团队提出LMNet,让语言模型学会自己「组网」
ICML 2026 | 清华姚权铭团队提出LMNet,让语言模型学会自己「组网」大语言模型正在成为人工智能系统的核心组件。从文本生成、数学推理到代码编写,单个大模型已经展现出强大的能力。
来自主题: AI技术研报
8509 点击 2026-06-01 09:26
 搜索
搜索
大语言模型正在成为人工智能系统的核心组件。从文本生成、数学推理到代码编写,单个大模型已经展现出强大的能力。
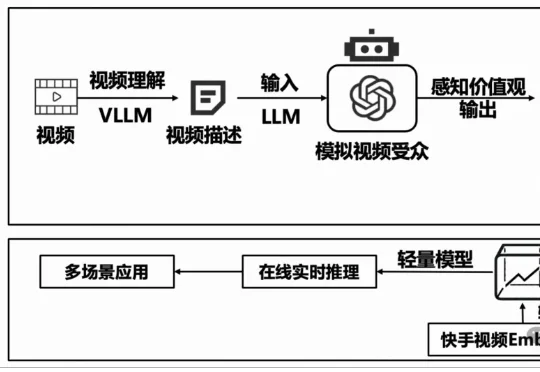
清华大学经济管理学院的陈柯均博士生、张佳音教授、徐心教授与快手消费策略算法部合作探索完成了一项联合实验:从视频传递的价值观的角度,去理解观看视频后用户的行为和心理变化。
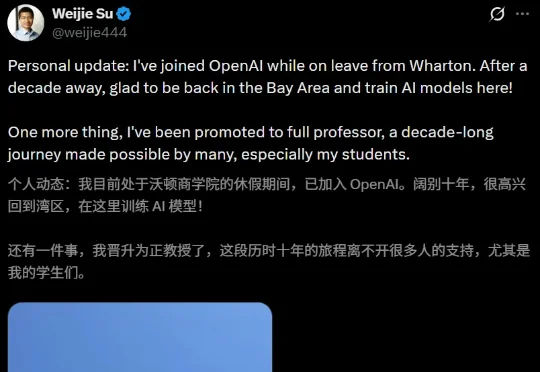
继清华姚班陈立杰之后,OpenAI又迎来一位重量级华人学者:北大数院「黄金二代」苏炜杰。今年,他刚刚摘下有「统计学诺奖」之称的COPSS Presidents' Award。

5 月下旬,NVIDIA 联合清华大学、多伦多大学和 Vector Institute 发布 Gamma-World,共一第一为清华大学电子系博士刘芳甫,核心 Research 方向是世界模型和空间智能。

所有人都在比谁的模型参数更大,但真正决定AI能不能落地的,其实是另一件没那么性感的事:一颗Token,能不能被稳定、便宜、规模化地生产出来。死磕这件事的,是一支从中国超级计算体系里走出来的年轻团队,是石科技。

刚刚,清华团队开源硬核Agent系统PilotDeck,在开发者圈已经传疯了。项目独立建舱,记忆可视可改,Token还能省一大半。从此,一个人,就是一支AI军团!
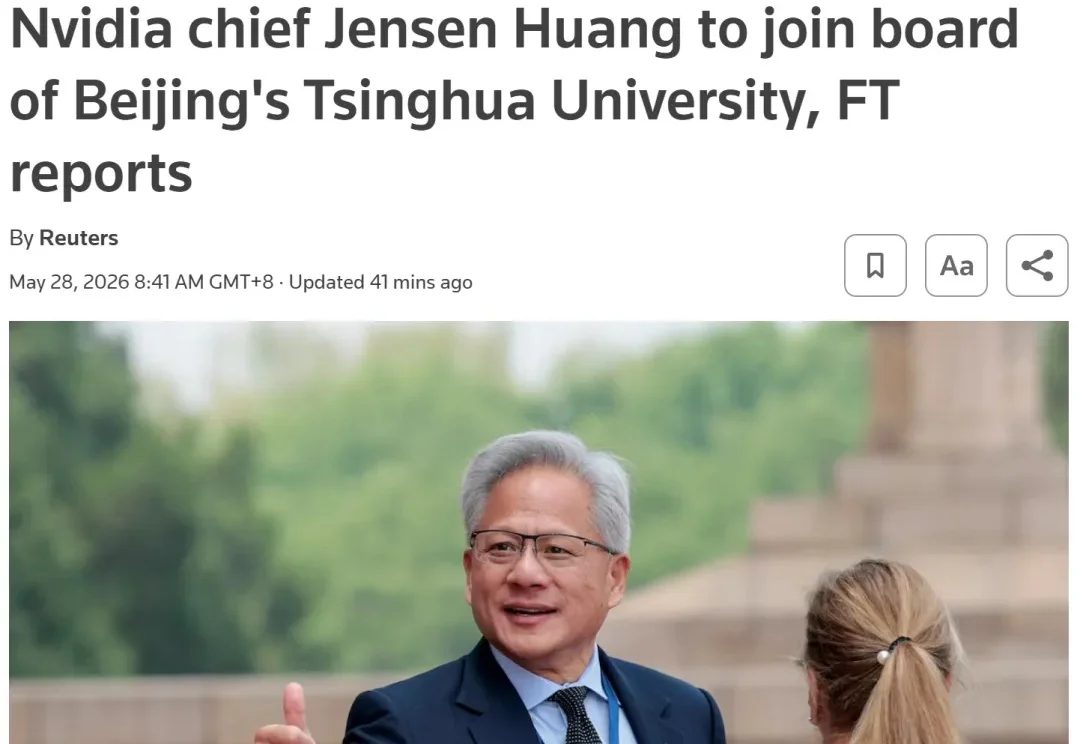
根据《金融时报》、路透社等媒体的报道,英伟达首席执行官黄仁勋(Jensen Huang)已接受邀请,加入清华大学经济管理学院顾问委员会。
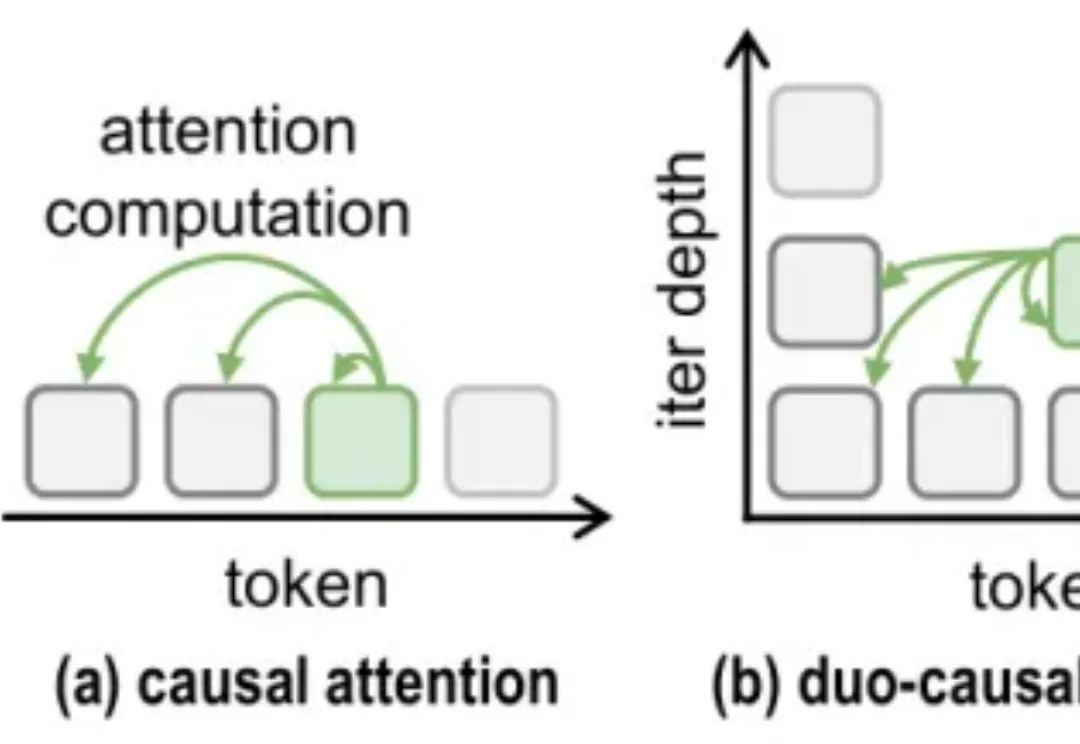
随着 o1/R1 等推理模型的发展 [1][2],「让模型多想一会儿」几乎成了提升复杂推理能力的标准方案。更长的 Chain-of-Thought、更大的测试时计算、更深的内部推理,都在用更多计算换取更可靠的答案。

如果把现在最热门的几条 3D 生成技术线放在一起看,你会发现它们正在遇到一个很像的问题。
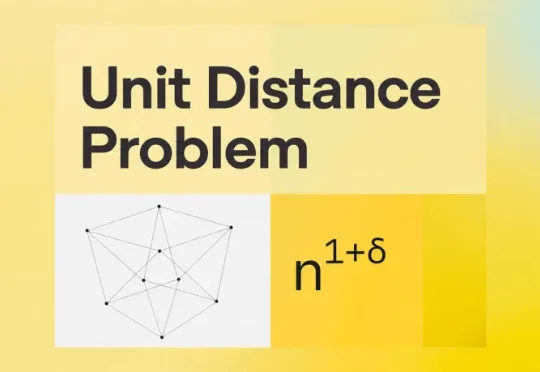
OpenAI宣布AI首次自主攻克顶级数学开放问题,连证明思路都让数学家意想不到!这个问题叫做平面单位距离问题,由匈牙利数学家保罗·Erdős在1946年首次提出。看视频(视频有亮点,曾经的清华本科特将获得者陈立杰是这个突破的的研究人员)