
Lychee-FD:哈工大张民教授团队在全双工语音大模型领域取得重要突破,斩获ACL 2026杰出论文奖
Lychee-FD:哈工大张民教授团队在全双工语音大模型领域取得重要突破,斩获ACL 2026杰出论文奖全双工语音对话是人类最自然的交流方式,是语音对话研究的梦想。相比文本输入,语音天然更接近人的交流方式,但现有语音对话常常停留在 “一问一答、听完再说” 的轮次式交互范式。
来自主题: AI技术研报
9337 点击 2026-07-16 14:55
 搜索
搜索
全双工语音对话是人类最自然的交流方式,是语音对话研究的梦想。相比文本输入,语音天然更接近人的交流方式,但现有语音对话常常停留在 “一问一答、听完再说” 的轮次式交互范式。

MrFlow(Multi-Resolution Flow Matching)就用这样的三阶段,在Qwen-Image等模型上把端到端生成时间从49.32s压到4.77s,实际加速10.35x。文章发布当日即登上Hugging Face Daily Papers;发布三天内,GitHub已收获200+stars;目前也已登上Hugging Face Trending Papers。
为了解决这一问题,来自 University of Arizona、Zoom 与 Stony Brook University 的研究团队推出了 VISTA(VIsual Spec-To-App Benchmark), 首个面向 Visual Spec-to-Web-App Coding Agents 的端到端 Benchmark。

UC Berkeley团队提出的端到端流程旨在解决该问题,研究团队跑通了首条能够从网络视频生成真实灵巧手实机执行轨迹的完整链路:先从真实场景中的单目RGB视频中重建4D手-物交互过程,再将这些交互轨迹重定向到拥有22个自由度的Sharpa Wave灵巧手上。
最新开源的Unlimited OCR,总参数3B,实际激活仅500M——放在大模型时代几乎是个零头。但就是这个小到离谱的模型,在OmniDocBench v1.5上拿下93.23%的综合分,v1.6更是达到93.92%,直接刷新了端到端SOTA。
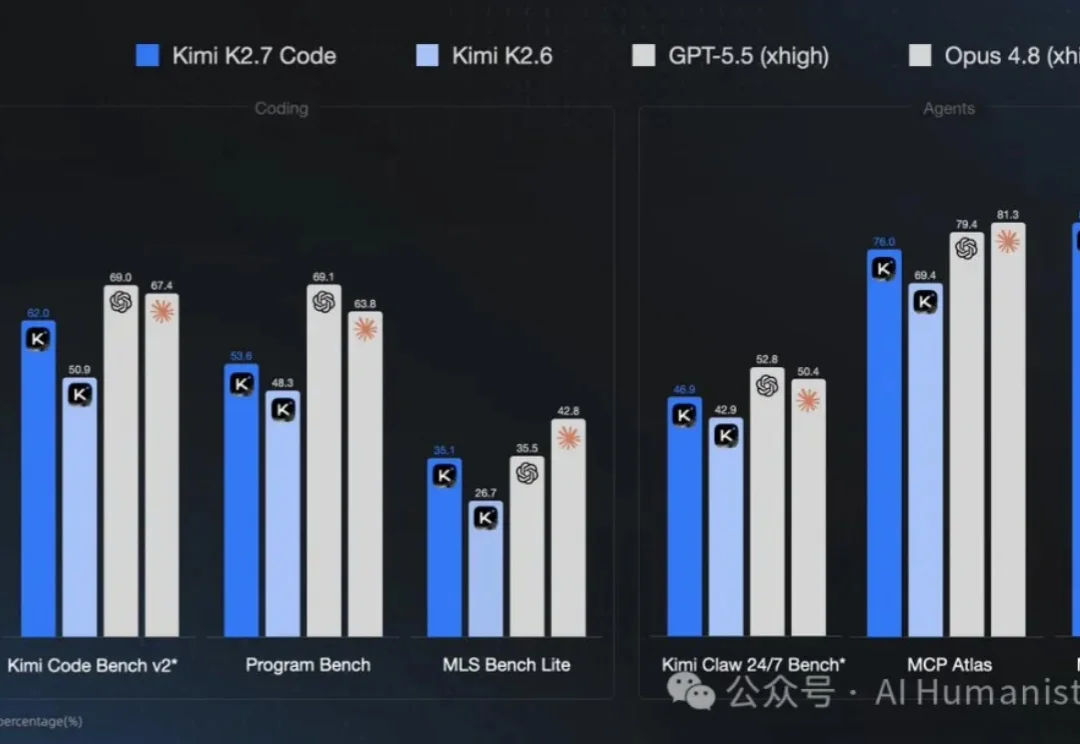
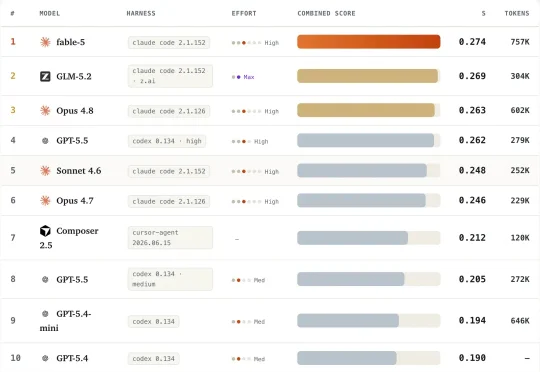
昨天 Kimi K2.7 Code 高速版 上线了,我上手试了下,最大的感受就一个字:快。
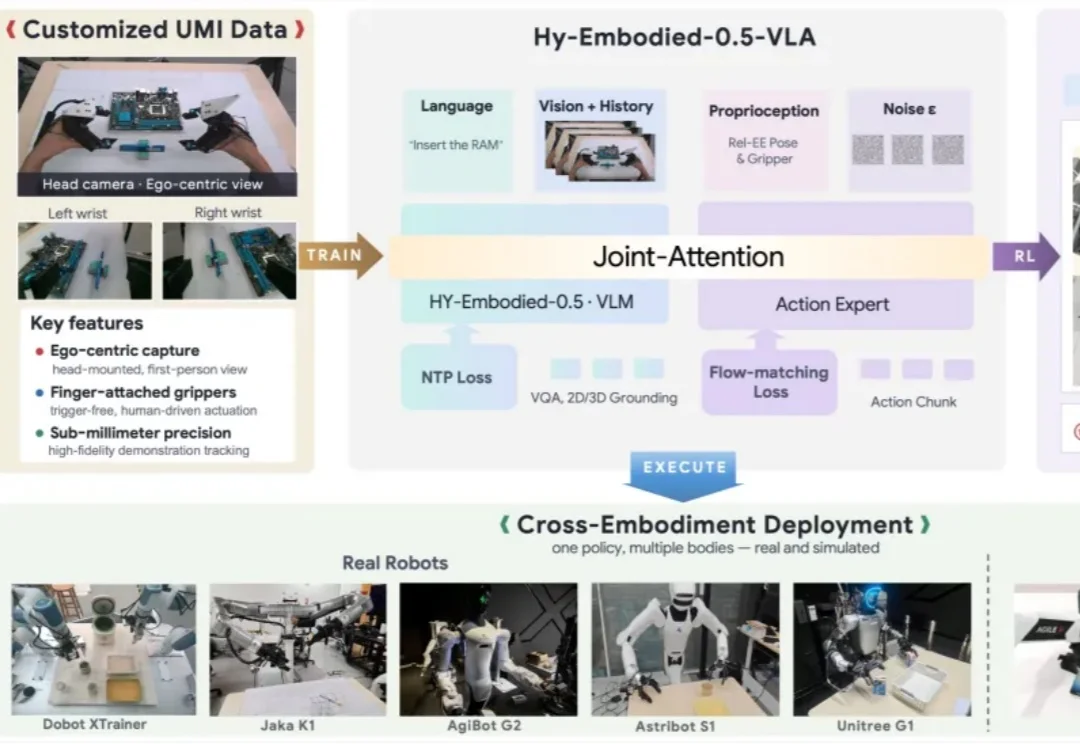
6 月 15 日,腾讯 Robotics X、福田实验室与混元团队联合发布面向真实世界机器人操作任务的端到端具身智能模型 Hy-Embodied-0.5-VLA(简称 HyVLA-0.5)。

观点跃迁研发了全球首个Text to Device AI电子设备生成平台STACK ANYWAY,旨在打通从“任意想法”到“现实硬件”的端到端链路。据观点跃迁估算,在海量的硬件SKU中,至少70%-80%属于硬件原型阶段,而这些原型实际上撬动了规模更大的量产硬件市场。整个硬件原型开发相关市场规模粗略估算已达上百亿美元。
Boson AI 与 SGLang-Omni 团队宣布,SGLang-Omni 已完成对 Higgs Audio v3 TTS 的端到端 Serving 支持。作为一家成立于 2023 年的 AI 基础设施公司,李沐与 Alex Smola共同创立了 Boson AI,聚焦大模型时代的系统与基础设施创新。
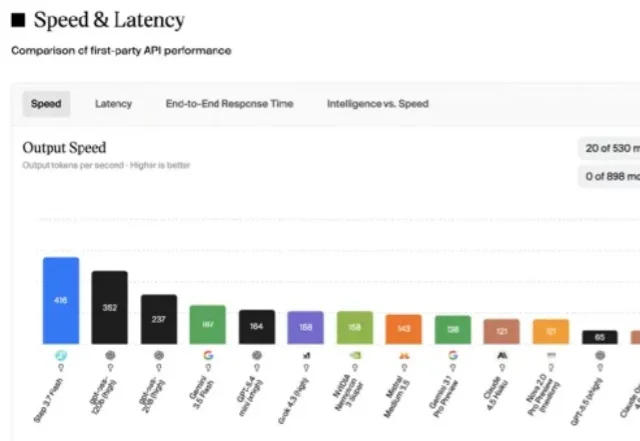
OpenRouter Trending榜单冷不丁窜出一匹国产黑马,热度暴涨稳居全球第二。