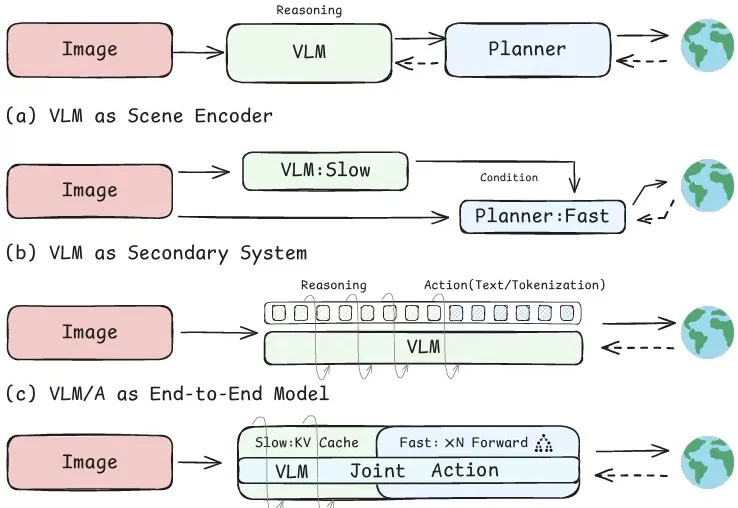
ICML2026 | AutoMoT : B2D & nuScense双SOTA ,重新思考VLM和端到端驾驶的结合
ICML2026 | AutoMoT : B2D & nuScense双SOTA ,重新思考VLM和端到端驾驶的结合大模型进入自动驾驶后,最直接的价值在于场景理解。它可以识别前车是否准备并线、行人是否可能横穿、施工区域是否会影响车道,也可以分析复杂路口中的让行关系。
来自主题: AI技术研报
10459 点击 2026-05-28 14:50
 搜索
搜索
大模型进入自动驾驶后,最直接的价值在于场景理解。它可以识别前车是否准备并线、行人是否可能横穿、施工区域是否会影响车道,也可以分析复杂路口中的让行关系。
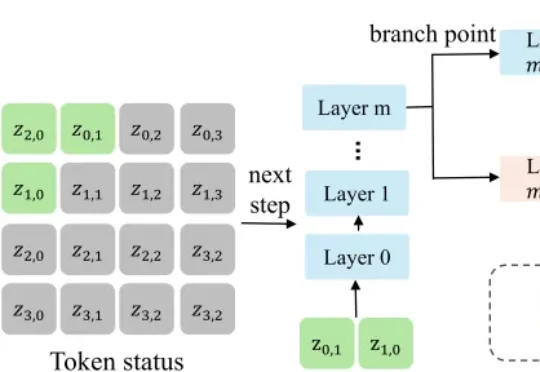
来自浙江大学和阿德莱德大学的研究团队提出了 FlashAR—— 一个轻量级的后训练加速框架。不需要从头训练,在 Emu3.5-Image-34B 模型上,仅用原始训练数据的 0.05%(约 8 万张图片),就能将预训练好的自回归模型改造成高度并行的生成器 Emu3.5-34B-Flash,实现最高 22.9 倍的端到端加速。

这是主流出版集团首次发起针对AI企业的诉讼,Meta明目张胆侵犯版权,出版商们将还原全部事实。
“Wayo不是SaaS,不是单点AI工具,而是直接交付结果的端到端闭环服务,这是我们和同行业其他产品的核心区别。”传统外贸服务模式难以规模化扩张,Julia认为AI正是解决“优质服务+规模化”矛盾的有效解法。

你有没有想过,不用联网、仅用一张消费级显卡,就能在个人电脑上拥有一个「边看、边听、边说、还能主动提醒」的类人 AI 助手?这就是 MiniCPM-o 4.5 所能做到的。在技术创新下,它仅凭 9B 参数,实现了业界首个端到端全双工全模态大模型,让端侧 AI 普惠成为现实。其自 2026 年 2 月模型发布以来,在 Hugging Face 上的下载量已突破 25 万+。
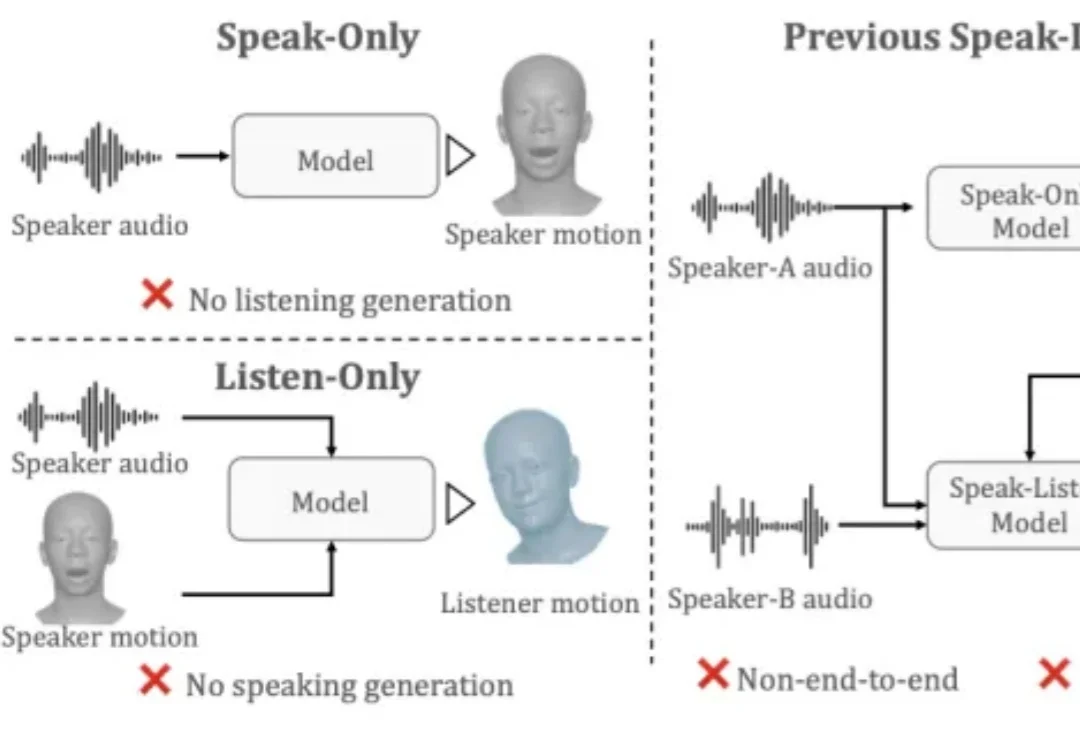
在游戏 NPC、虚拟主播、在线客服等数字人对话场景中,倾听时的 “扑克脸” 问题一直是行业长期痛点 —— 虚拟人说话时口型可以做到精准同步,但倾听时却表情僵硬、毫无反应,严重影响对话的自然感和沉浸感。盛大 AI 研究院(东京)与东京大学联合提出 UniLS(Unified Listening and Speaking),首个仅凭双轨音频即可端到端同时驱动说话和倾听面部动作的统一框架。

今天,来自ZJU-REAL的团队带来了ClawGUI,一个覆盖GUI智能体在线RL训练、标准化评测、真机部署完整生命周期的开源框架。不是三个独立工具的简单拼接,而是一条打通的流水线:用ClawGUI-RL训练,用ClawGUI-Eval评测,用OpenClaw-GUI部署,端到端验证。
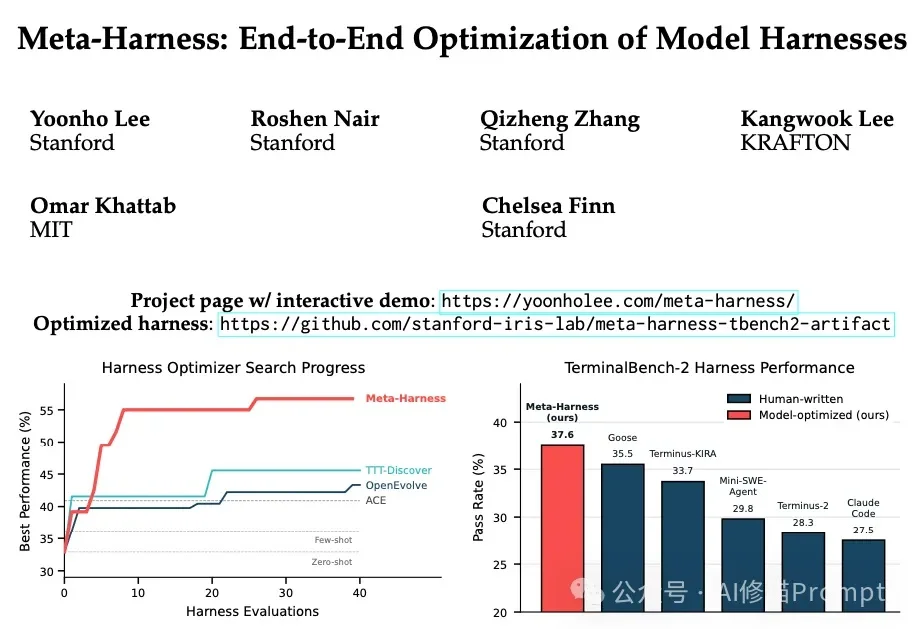
去年讨论Agent落地时,重点往往是Context Engineering。大家都在琢磨怎么放 Few-shot,怎么优化 RAG 检索的文本片段。但随着 Agent 任务复杂度的上升,控制数据流向、工具调度和异常处理的底层脚手架代码,往往比单纯拼接文本对系统性能的影响更大。
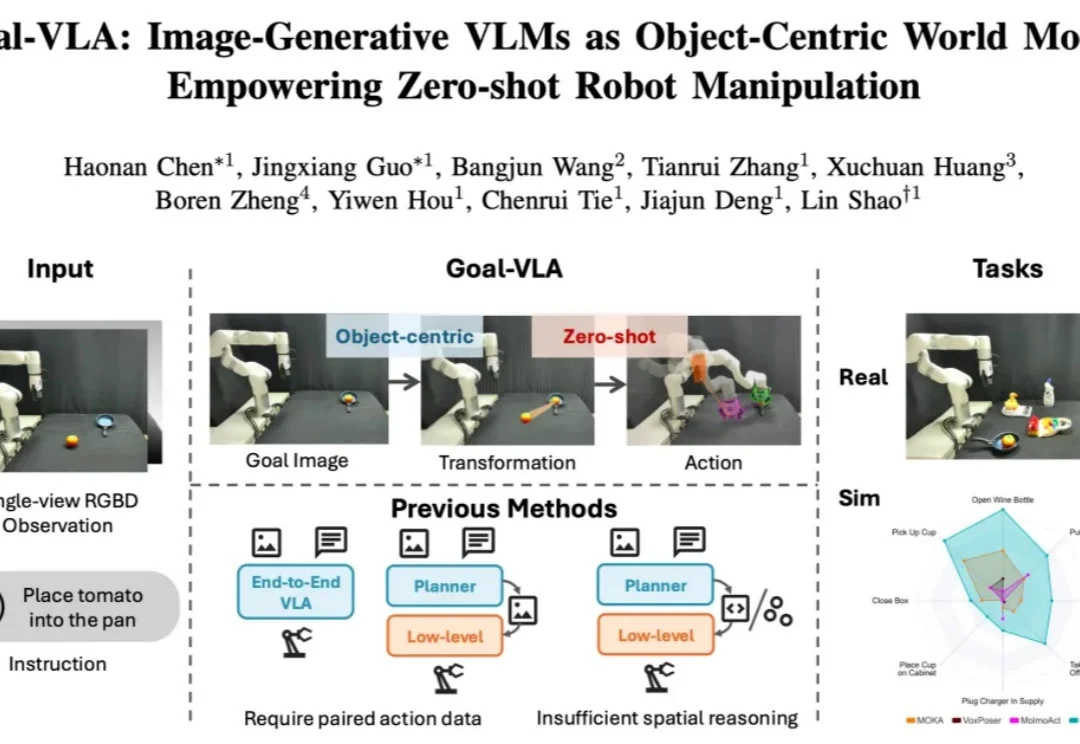
在具身智能领域,机器人操作的泛化能力一直是一个核心挑战。当前,视觉 - 语言 - 动作(VLA)模型主要分为两大范式:端到端模型与分层模型。端到端 VLA 模型(如 RT-2 [1], OpenVLA [2])严重依赖海量的 “指令 - 视觉 - 动作” 成对数据,获取成本极高,导致其在面对新任务或新场景时零样本泛化能力受限。
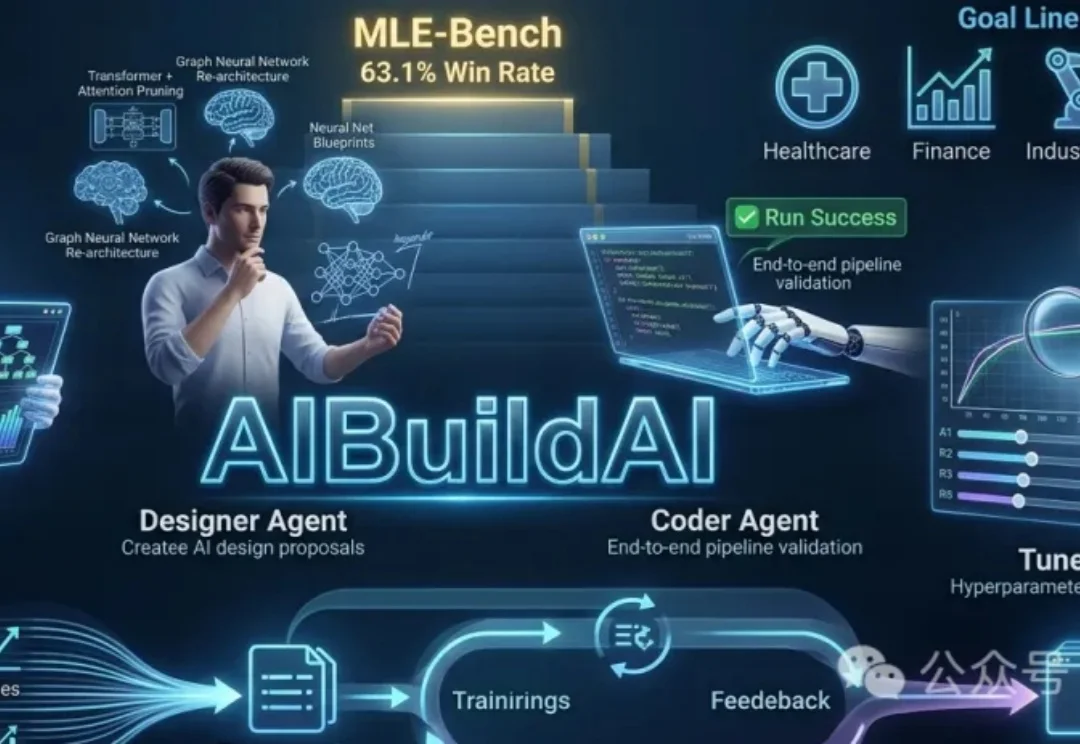
UCSD团队推出AIBuildAI智能体,无需编程,仅用自然语言描述任务,即可自动设计、编码、训练、调参并优化AI模型,分工协作,端到端完成AI开发。在OpenAI MLE-Bench测试中,AIBuildAI以63.1%的获奖率位居第一,性能媲美人类专家,推动AI开发迈向全自动化新时代。