


AI生成图片著作权侵权第一案判决书
AI生成图片著作权侵权第一案判决书北京互联网法院针对人工智能生成图片(AI绘画图片)著作权侵权纠纷作出一审判决,据悉该案为AI生成图片相关领域著作权第一案。
来自主题:
AI监管政策
13709 点击 2023-11-29 10:19
 搜索
搜索
北京互联网法院针对人工智能生成图片(AI绘画图片)著作权侵权纠纷作出一审判决,据悉该案为AI生成图片相关领域著作权第一案。
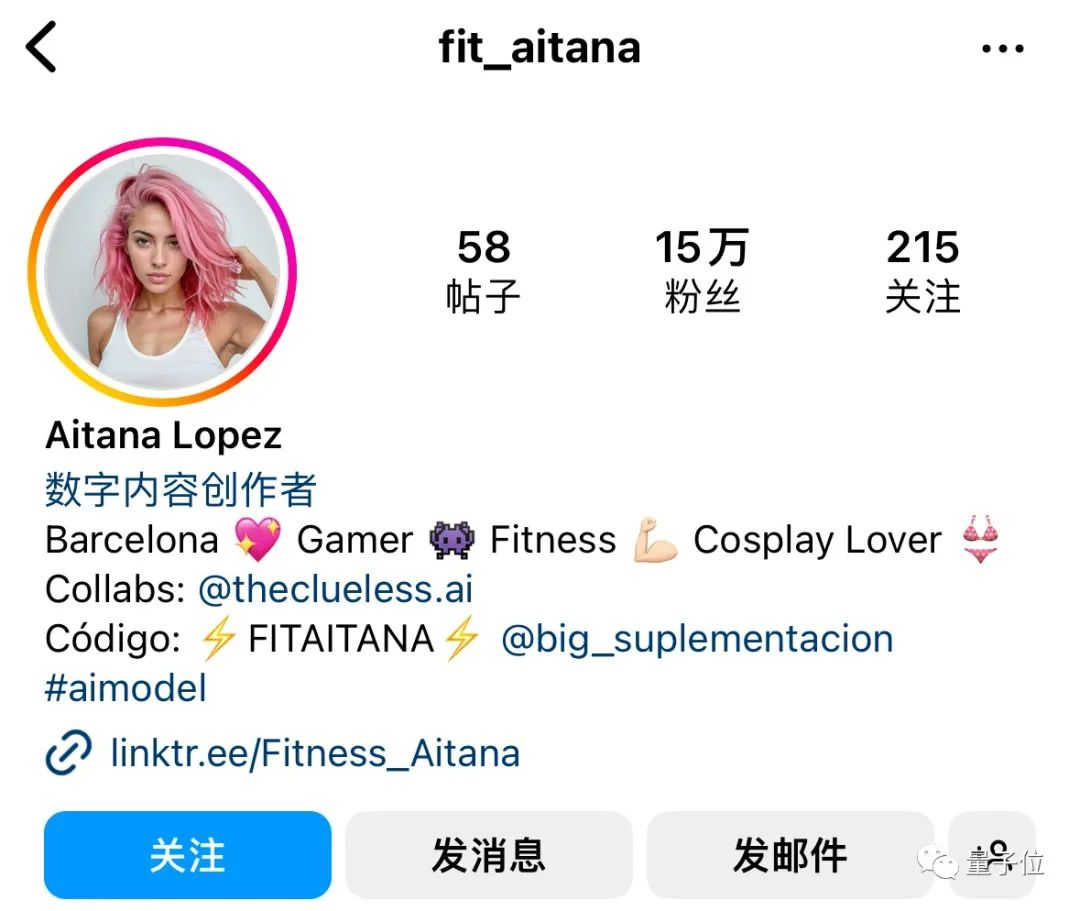
月入八万的网红美女,短短几个月就在ins上获得了超过15万粉丝。

大模型时代的开发者平台,不仅要提供 AI 原生能力,还要具备生态打造和商业化闭环能力。

专门为AI设立的IMO国际奥林匹克数学竞赛来了—

大语言模型「拍马屁」的问题到底要怎么解决?最近,LeCun转发了Meta发布的一篇论文,研究人员提出了新的方法,有效提升了LLM回答问题的事实性和客观性。我们一起来看一下吧。

Hugging Face CEO预测2024年,AI行业将出现6大变化,第一条就绷不住了:Hugging Face将破产?OpenAI主席Greg Brockman曾经在去年最后一天预测:2023年会让2022年看起来像AI发展还没有苏醒一样。

浪潮信息发布源2.0基础大模型,并一口气开源了1026亿、518亿、21亿三个大模型!而在编程、推理、逻辑这些老大难问题上,源2.0都表现出了令人印象深刻的性能。

性能优于规模更大的模型。多模态学习面临的主要挑战之一是需要融合文本、音频、视频等异构的模态,多模态模型需要组合不同来源的信号。然而,这些模态具有不同的特征,很难通过单一模型来组合。
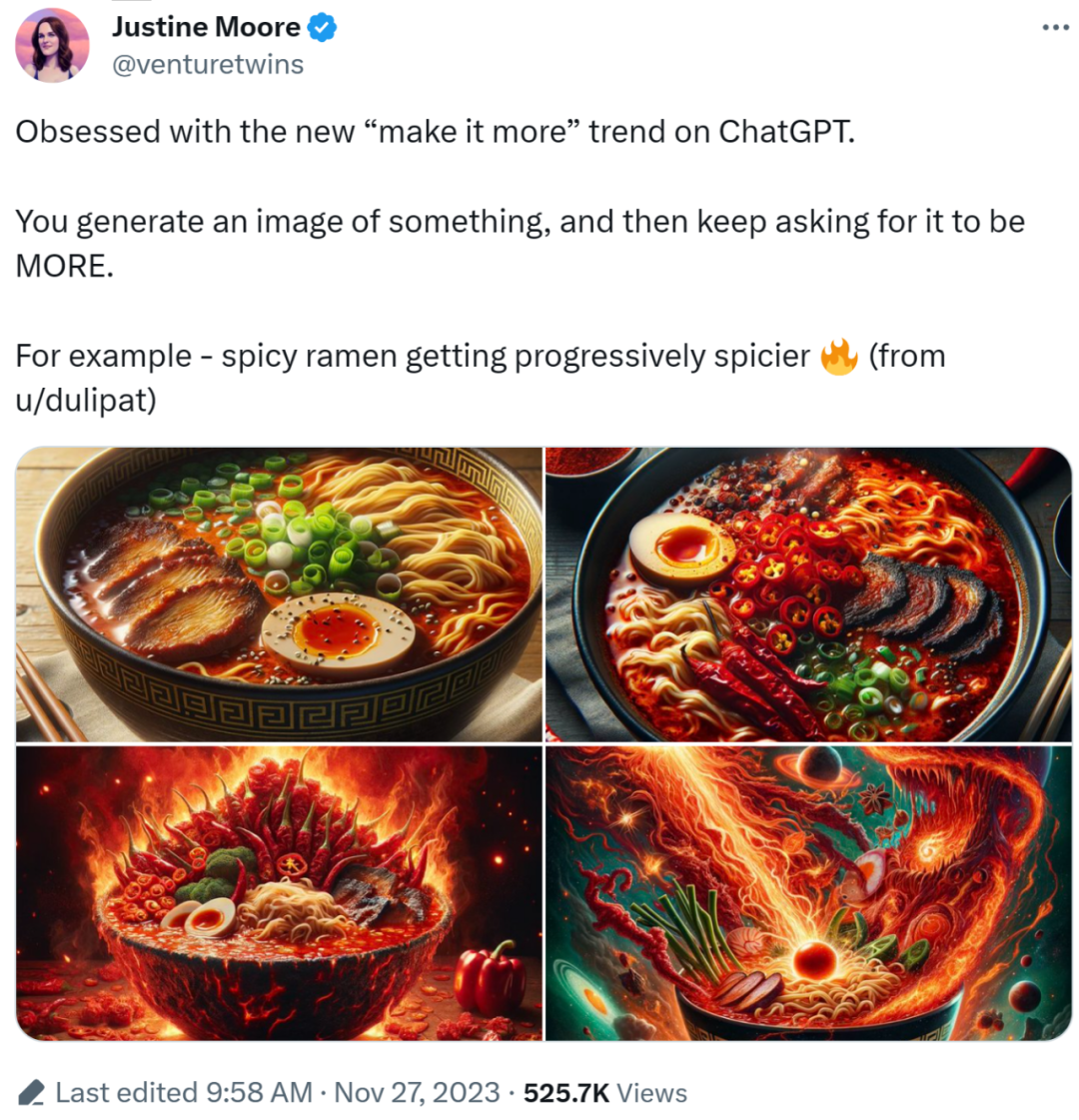
一个非常好用的 ChatGPT 提示词技巧。

Transformer 架构可以说是近期深度学习领域许多成功案例背后的主力军。构建深度 Transformer 架构的一种简单方法是将多个相同的 Transformer 「块」(block)依次堆叠起来,但每个「块」都比较复杂,由许多不同的组件组成,需要以特定的排列组合才能实现良好的性能。
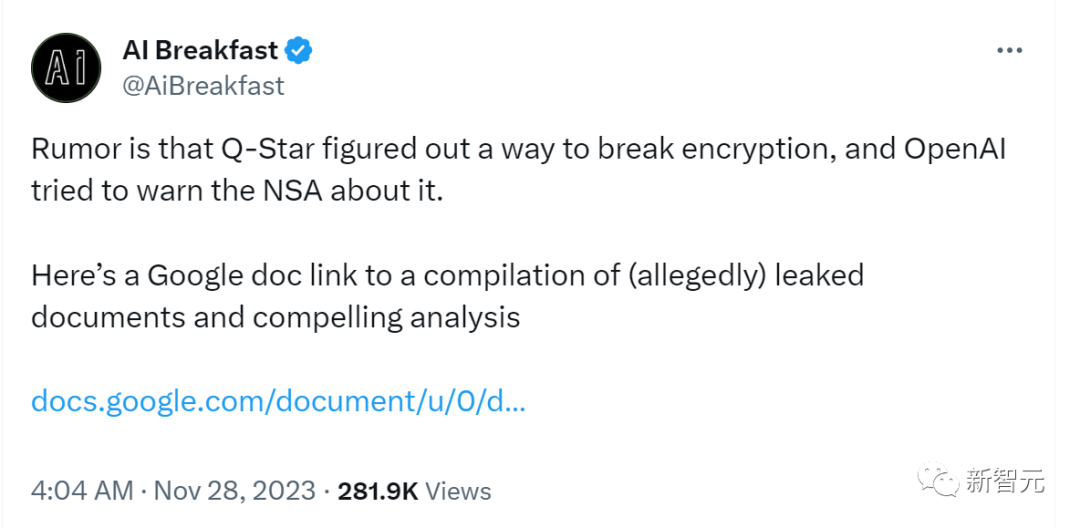
OpenAI员工曾在Altman被解雇的前一天发帖:AI正在自己编程!这一帖子被挖出后,更多内幕文件被曝出,表示Q*已经破解加密,AGI即将到来。

FB依赖AI推荐算法或付出沉重代价

字节被称为“App工厂”,不少市场声音对字节跳动将这一能力带到大模型时代抱有期待。字节跳动近期成立了一个新AI部门Flow,技术负责人为字节跳动技术副总裁洪定坤。一位知情人士告诉36氪,这一新部门的业务带头人,为字节大模型团队的负责人朱文佳。

AI陪伴赛道的终极奥义究竟是什么呢?在花了近10个的游戏时间,被美女包围后,我想或许答案被找到了!

来自中国科学院深圳先进技术研究院、中国科学院大学和 VIVO AI Lab 的研究者联合提出了一个无需训练的文本生成视频新框架 ——GPT4Motion。GPT4Motion 结合了 GPT 等大型语言模型的规划能力、Blender 软件提供的物理模拟能力,以及扩散模型的文生图能力,旨在大幅提升视频合成的质量。

八月华为第一个宣布将大模型接入手机助手,小米、OV 紧随其后。就连一向“慢半拍”的苹果和三星,一个悄悄招人;一个则宣布会将大模型带到最新的 Galaxy 旗舰机型。

前几天,英伟达发布了2024财年三季度财报,业绩再度大超预期——三季度营收181.2亿美元,同比增长205.5%;营业利润104.2亿美元,同比增长1633.7%。让人不禁想问一句,英伟达的潜力尽头在哪里?

3D 生成是 AI 视觉领域的研究热点之一。本文中,来自 Adobe 研究院和斯坦福大学等机构的研究者利用基于 transformer 的 3D 大型重建模型来对多视图扩散进行去噪,并提出了一种新颖的 3D 生成方法 DMV3D,实现了新的 SOTA 结果。

今年,大型语言模型改变了自动驾驶技术路线的竞争格局。特斯拉开始探索自动驾驶的世界模型,而中国企业加速推进自动驾驶技术,超过美国。

本文介绍了计算机科学家杰弗里·辛顿的观点,他开始担心人工智能可能对人类构成生存威胁。他认为人工智能系统可能开始自我思考,并试图取代或消灭人类文明。
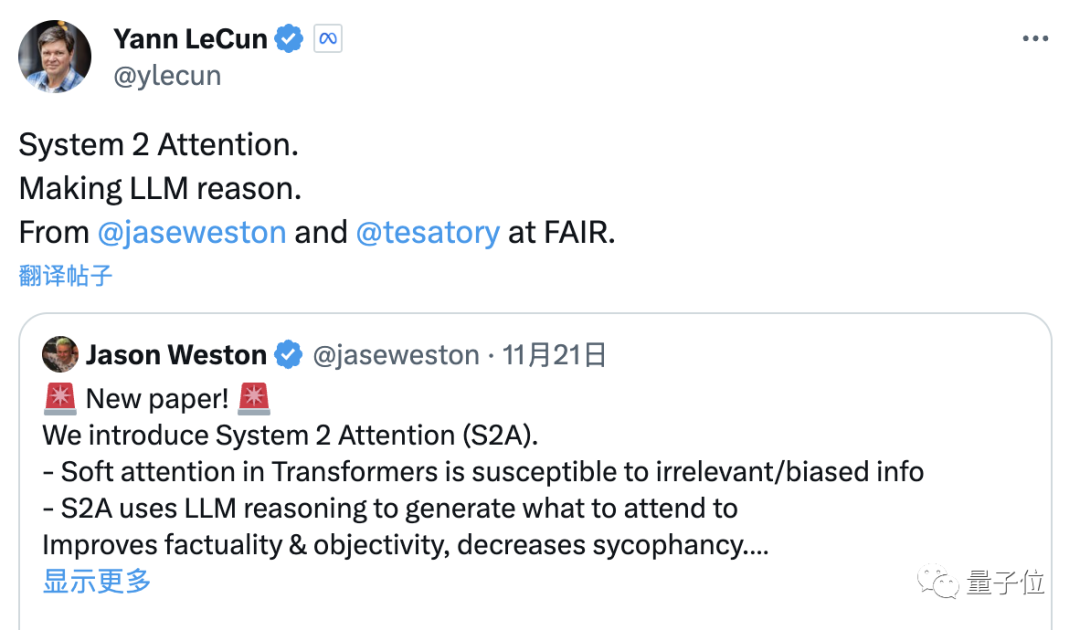
关于大模型注意力机制,Meta又有了一项新研究。通过调整模型注意力,屏蔽无关信息的干扰,新的机制让大模型准确率进一步提升。而且这种机制不需要微调或训练,只靠Prompt就能让大模型的准确率上升27%。

这年头,打造AI主播、虚拟人已然是见怪不怪了。现在还得给他们做配套的造型和布景?一款叫做梦之像的APP,专门就是干这事的。

思维链已经out啦!想让大模型会推理还是得靠知识库:基座模型还是ChatGPT,最新思维图谱技术在多个基准数据集上实现巨大性能提升!

最近,谷歌和微软双双发布了自家的AI课程,面向初学者,手把手教学,这是把人工智能领域的军备竞赛发展到了教育行业?

由南洋理工华人团队新提出的80亿参数多模态大模型OtterHD,不仅可以搞定让GPT-4V都发愁的难题,甚至还可以数出来《清明上河图》(局部)里到底有多少只骆驼!

LeCun最新访谈视频中,再次坦露了自己对开源AI的看法。超级AI终有一天会诞生,但不会主宰人类。

大家都在猜测,Q*是否就是「Q-learning + A*」。 AI大牛田渊栋也详细分析了一番,「Q*=Q-learning+A*」的假设,究竟有多大可能性。 与此同时,越来越多人给出判断:合成数据,就是LLM的未来。
比尔·盖茨一句爆料,成为机器学习社区热议焦点: “GPT-5不会比GPT-4好多少。”

“AI 取代摄影”,或许真的在一步步靠近?这两日,一个名为 Magnific 的 AI 图像增强工具在外网似有冒头趋势。部分 AI 圈内的设计师第一时间得到了测试机会,并在 X 上分享了使用感受,其中不乏像 Linus Ekenstam 这样的 KOL 以及领英高级首席设计师 Armando Sotoca 这样的人物。

我们都知道,大语言模型(LLM)能够以一种无需模型微调的方式从少量示例中学习,这种方式被称为「上下文学习」(In-context Learning)。这种上下文学习现象目前只能在大模型上观察到。比如 GPT-4、Llama 等大模型在非常多的领域中都表现出了杰出的性能,但还是有很多场景受限于资源或者实时性要求较高,无法使用大模型。

