

Skills刚火,就有零Skill的Agent来了…
Skills刚火,就有零Skill的Agent来了…Skills刚爆火,又有新的Agent范式来搅局了……
来自主题:
AI资讯
8279 点击 2026-01-27 09:42
 搜索
搜索
Skills刚爆火,又有新的Agent范式来搅局了……

你是否遇到过客户拿着AI起草的合同条款,质疑你的修改建议?你是否用AI解决过重复、枯燥、看起来没什么用的基础工作?随着AI渗入法律行业,有人认为它是年轻律师弯道超车的机会,也有人认为它是行业跟风的“噱头”。
近期 Claude Code 推出的 Excel 功能非常惊艳,我们认为 Excel 可能成为继 Coding 之后,下一个迎来“aha moment”、并快速爆发的高价值领域。

这是一份迟到三年的行业复盘。牛津大学最新的实证研究撕开了那层遮羞布:2022年全球科技大裁员爆发时,ChatGPT甚至尚未发布。周期性缩编被伪装成技术性迭代,AI替资本背了三年的锅,直到今天真相才被彻底复位。

过去一整年,具身智能成了 AI 行业里最被反复提及、却最难真正落地的方向。一边是人形机器人发布会密集登场,另一边却始终缺乏可规模部署的现实成果。算法在进步,算力在堆叠,但问题始终没有改变:机器人到底该如何被教会在真实世界中行动。
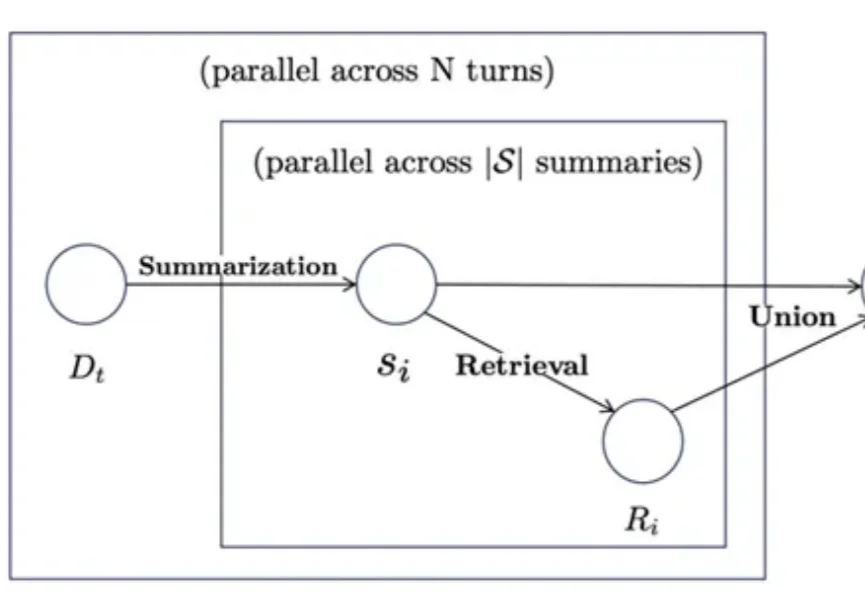
思维导图曾被证明可以帮助学习障碍者快速提升成绩,那么当前已经可堪一用的智能体系统如果引入类似工具是否可以帮助改善长期学习记忆能力呢?有研究团队做出了探索性尝试。
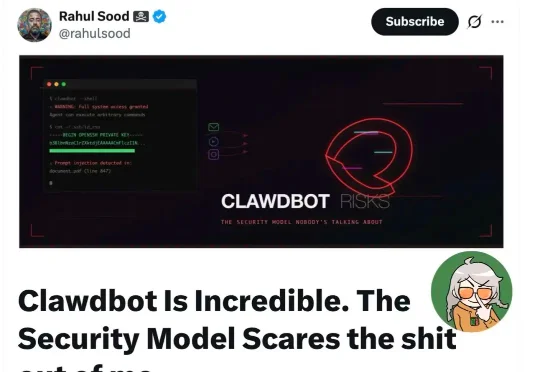
革命性AI开源智能体—Clawdbot火了, 看看投资人Rahul Sood怎么说, 他也是Microsoft Ventures创始人。I've been messing with Clawdbot this week and I get the hype.

近日,北京大学朱毅鑫教授课题组、北京大学毕彦超教授课题组和山西医科大学第一医院王效春团队通过结合 AI 模型和大脑损伤患者的数据,发现语言其实是一副无形的智能眼镜,时刻在悄悄修饰着我们看到的世界。我们可能以为视觉就是眼睛看到什么就是什么,但是这项成果说明了视觉从来都不是孤立的。事实上,当我们在看图片的时候,其实不只是在看,而是在进行被语言调制过的看。
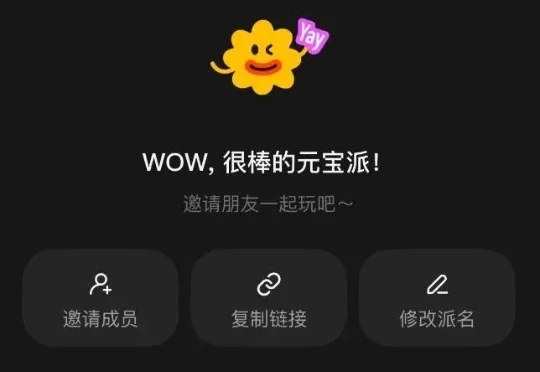
1 月 26 日,腾讯旗下 AI 助手元宝开启了社交 AI 玩法「元宝派」内测。 极客公园第一时间上手体验:用户可以选择创建一个「派」,或者加入一个已有的「派」。用户可以在派内 @ 元宝或引用元宝的话,让元宝 AI 总结派内聊天、创建健身、阅读等兴趣打卡活动,由元宝 AI 担任「监督员」。
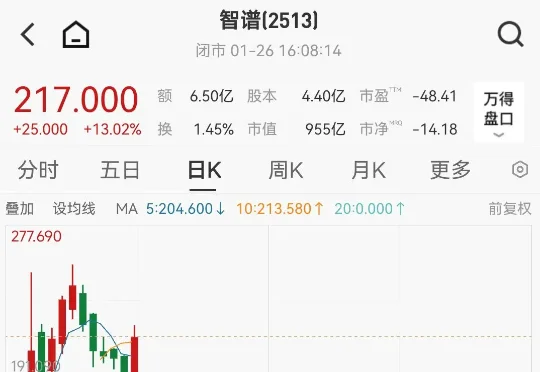
近日,中国证监会官网更新了智谱公司的IPO辅导进展信息。根据公告,其辅导机构中金公司已递交了智谱的第三期IPO辅导工作进展情况报告(下称“辅导报告”),落款日期为2026年1月15日。

火爆全网的Clawdbot,作者竟然是个亿万富翁?!本来以为又是个辍学的AI创业者,结果上网一查,这哥们早在十五年前就创过业,今年估计已经四十岁了。

这两天,我的朋友圈被一个东西刷屏了,叫 Clawbot 🦞。
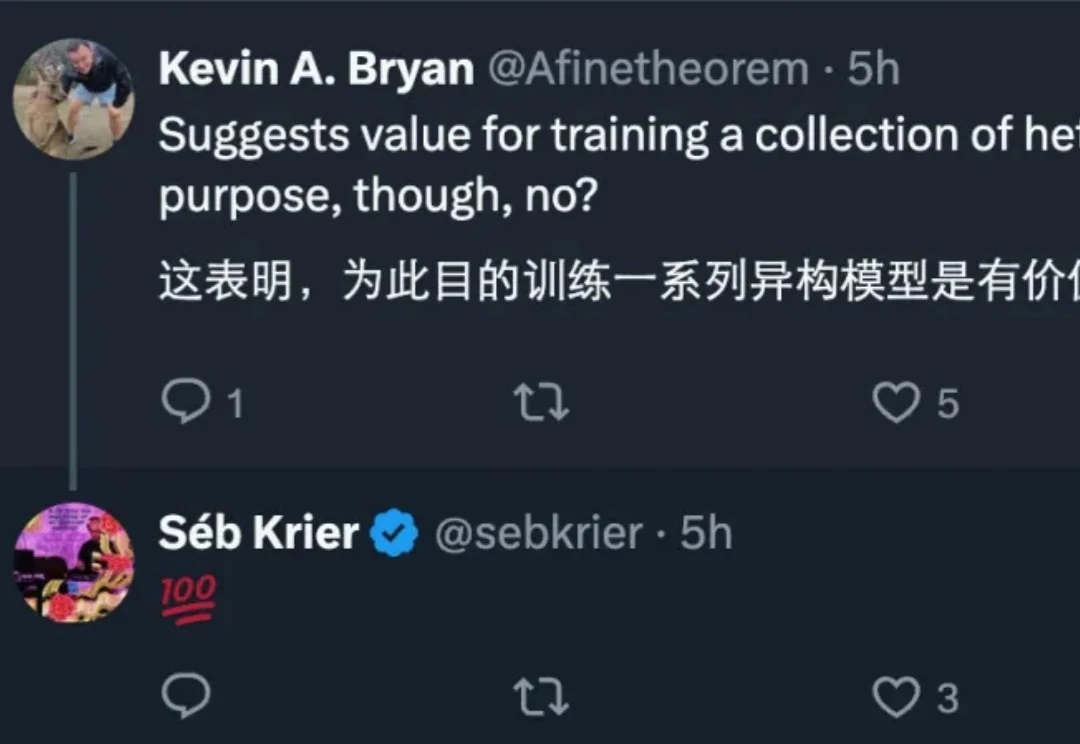
“DeepSeek-V3是在Mistral提出的架构上构建的。”
过去两年,大模型的推理能力出现了一次明显的跃迁。在数学、逻辑、多步规划等复杂任务上,推理模型如 OpenAI 的 o 系列、DeepSeek-R1、QwQ-32B,开始稳定拉开与传统指令微调模型的差距。直观来看,它们似乎只是思考得更久了:更长的 Chain-of-Thought、更高的 test-time compute,成为最常被引用的解释。

100%是用Codex写的。还有内部爆料说,Codex让他们仅用三天时间就搭出了服务器,三周就发布了APP。人类程序员,真的要退出历史舞台了?

你的童年我的童年好像不一样。
进入到 2026 年,OpenAI 在关注消费级产品(如 ChatGPT、社交应用)之外,开始将一部分重心转向企业级市场。

如果论文是AI写给AI看的,那人类还剩下什么?
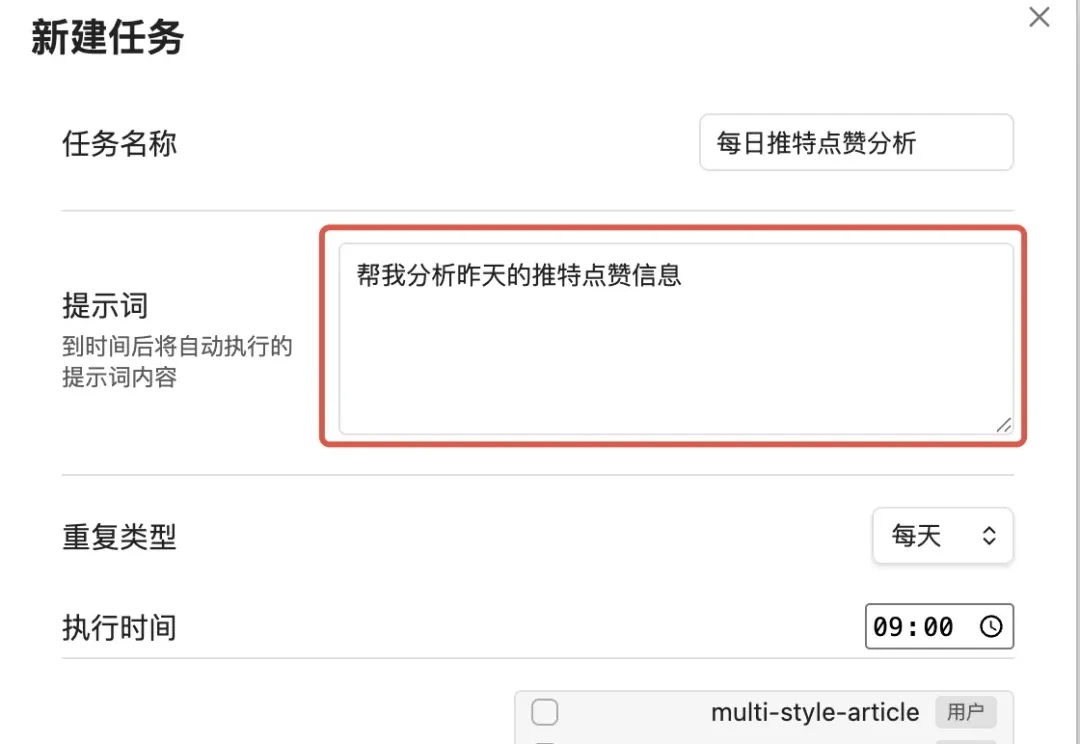
我一直有一个习惯,就每天都会刷 Twitter。倒也不是为了打发时间,而是因为在 AI 这个领域,Twitter 几乎是最前沿的信息源。新论文、新产品、行业八卦、技术突破,很多时候,等中文媒体跟进报道,已经是三五天后的事了。

嗨大家好!我是阿真! 了解我的人都知道,虽然我混得不怎么样,但是我的朋友都牛逼且靠谱,前几天藏师傅(@歸藏的AI工具箱)跟我说有个大佬有新产品要上了,这个情况我都是二话不说直接冲的。

7×24h「全职AI员工」实火!退休码农造出神级Clawdbot,在硅谷红遍半边天,就连谷歌大佬也入局了。

阶跃终于有新闻了。

斯坦福与英伟达联合发布重磅论文 TTT-Discover,打破「模型训练完即定型」的铁律。它让 AI 在推理阶段针对特定难题「现场长脑子」,不惜花费数百美元算力,只为求得一次打破纪录的极值。从重写数学猜想到碾压人类代码速度,这种「激进进化」正在重新定义机器发现的边界。

2026开年,OpenAI的「推理之父」Jerry Tworek离职了。顶尖大脑因方向冲突和资源倾斜而出走,从这一刻起,硅谷的「Open」或许只剩下一个名字,而非一家真正的AGI实验室。
近年来多模态大模型在视觉感知,长视频问答等方面涌现出了强劲的性能,但是这种跨模态融合也带来了巨大的计算成本。高分辨率图像和长视频会产生成千上万个视觉 token ,带来极高的显存占用和延迟,限制了模型的可扩展性和本地部署。

2026 年才开始,全球 AI 行业就迎来了第一个开年王炸。不是来自某个更大的模型参数,不是某家实验室刷新了榜单分数,而是一个看似不起眼、却迅速破圈的概念——Agent Skill。
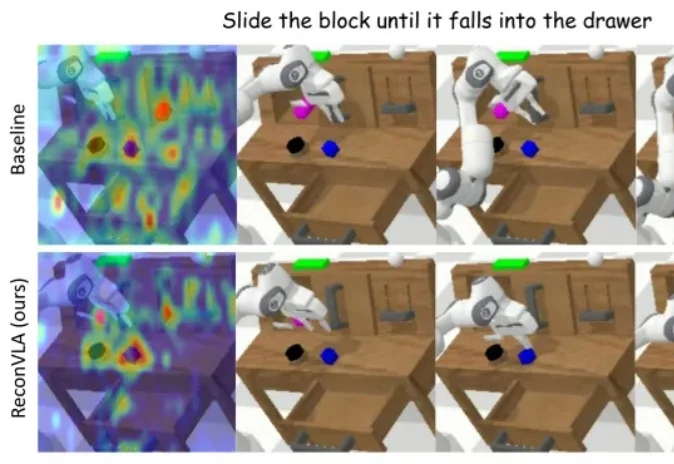
在长期以来的 AI 研究版图中,具身智能虽然在机器人操作、自动化系统与现实应用中至关重要,却常被视为「系统工程驱动」的研究方向,鲜少被认为能够在 AI 核心建模范式上产生决定性影响。

周末看到一个好玩的东西。 3D领域的NanoBanana也来了。 中间有一句比较重要的功能,是我觉得非常有意思的: 可以通过提示进行局部编辑。 玩过NanoBanana的肯定很熟了。 算了补全了一块有

APPSO 获悉,阶跃星辰近日完成了超 50 亿元人民币 B+ 轮融资,参与机构包括上国投先导基金、国寿股权、浦东创投、徐汇资本、无锡梁溪基金、厦门国贸、华勤技术等产业投资方。腾讯、启明创投、五源资本

大家好,我是最近天天折腾CLI Agent的袋鼠帝。 一周前,我给大家安利了一款Claude Code的最强开源对手:OpenCode,没想到文章发出去后反响这么热烈,不管是阅读量还是评论都非常多。刚好,前几天我看到腾讯的CodeBuddy Code重磅升级到了2.0版本。说实话,CodeBuddy Code我有用过,基本完全复刻Claude Code,之前还帮我开发了好几个小工具,很实用。

