# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
去年12月,CMU和普林斯顿的2位研究者发布了Mamba架构,瞬间引起AI社区震动!
结果,这篇被众人看好有望「颠覆Transformer霸权」的论文,今天竟曝出疑似被顶会拒收?!
今早,康奈尔大学副教授Sasha Rush最先发现,这篇有望成为奠基之作的论文似乎要被ICLR 2024拒之门外。
并表示,「说实话,我不理解。如果它被拒绝了,我们还有什么机会」。
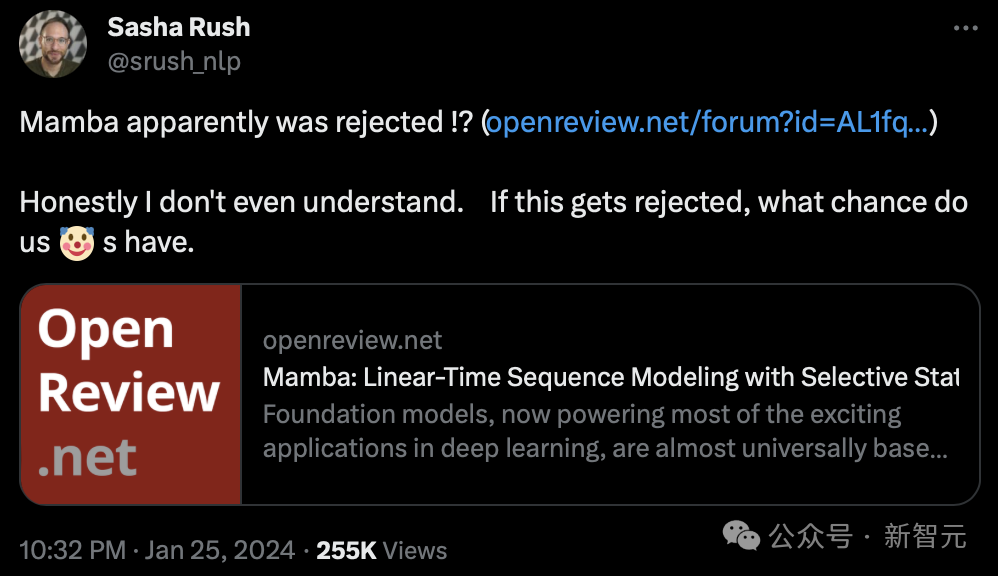
在OpenReview上可以看到,四位审稿人给出的分数是3、6、8、8。
虽然这个分数未必会让论文被拒收,但是3分这样的低分,也是很离谱了。
这篇由CMU、普林斯顿大学的2位研究人员发表的论文,提出了一种全新的架构Mamba。
这种SSM架构在语言建模上与Transformers不相上下,而且还能线性扩展,同时具有5倍的推理吞吐量!

论文地址:https://arxiv.org/pdf/2312.00752.pdf
当时论文一出,直接炸翻了AI社区,许多人纷纷表示推翻Transformer的架构终于诞生了。
而现在,Mamba论文有被拒可能性,让许多人无法理解。

就连图灵巨头LeCun也下场参与了这波讨论,表示遭遇过类似的「冤屈」。
「想当年,我被引数最多,仅在Arxiv提交的论文被引超过了1880次的论文,从未被接收」。
LeCun正是以使用卷积神经网络(CNN)在光学字符识别和计算机视觉方面的工作而闻名的,也因此在2019年获得了图灵奖。
不过他的这篇发表于2015年的《基于图结构数据的深度卷积网络》的论文,却从未被顶会接收。

论文地址:https://arxiv.org/pdf/1506.05163.pdf
深度学习AI研究员Sebastian Raschka称,尽管如此,Mamba在AI社区带来了深刻的影响。
近来一大波研究,都是基于Mamba架构衍生出来的,比如MoE-Mamba、Vision Mamba。

有趣的是,爆料Mamba被打低分的Sasha Rush,也在今天发表了一篇基于这样研究的新论文——MambaByte。

事实上,Mamba架构已经有了「星星之火可以燎原」的架势,在学术圈的影响力越来越广。
有网友表示,Mamba论文将开始占领arXiv。
「举个例子,我刚看到这篇论文提出了MambaByte,一种无token的选择性状态空间模型。基本上,它调整了Mamba SSM,直接从原始token中学习。」

Mamba论文的Tri Dao今天也转发了这篇研究。
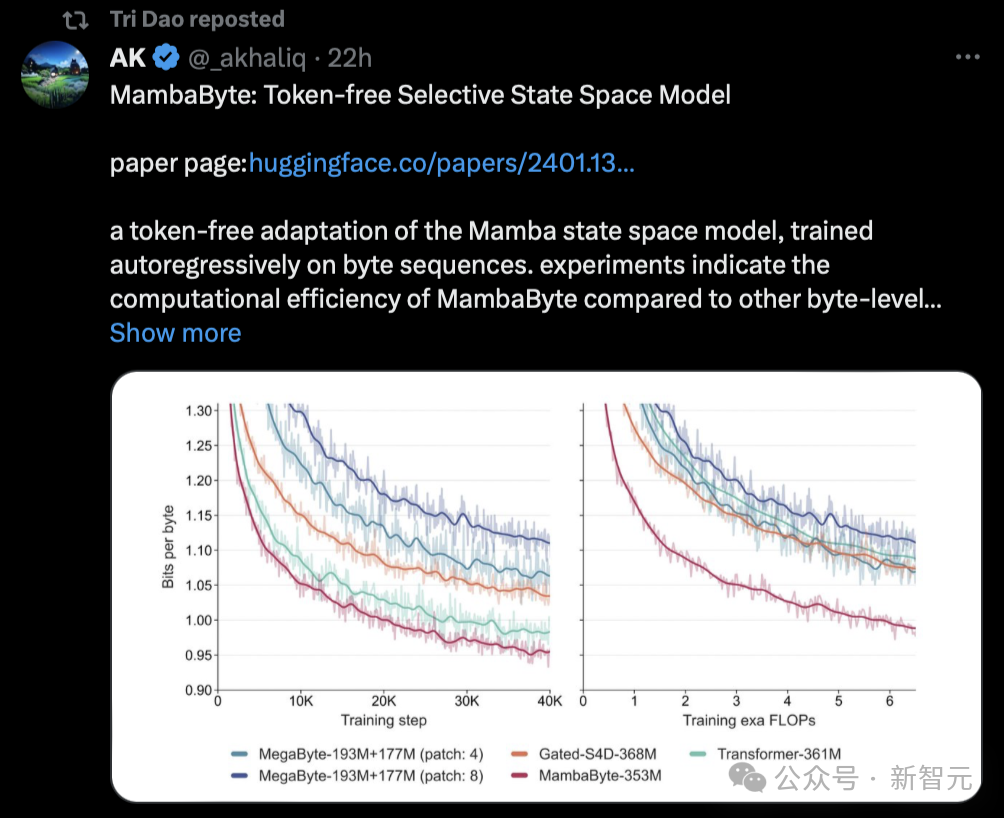
如此大火的论文却被打出低分,有人表示,看来同行评审是真不关注营销的声音有多大啊。
给Mamba论文打低分的原因究竟是什么呢?
可以看到给打3分的审稿人,置信度还是5,说明自己对这个评分也是非常肯定。

在review中,他提出的问题分为两个部分:一是对模型设计的质疑,另一个是对实验提出疑问。
模型设计
- Mamba的设计动机是解决循环模型的缺点,同时提高基于Transformer模型的效率。有很多研究都是沿着这个方向进行的:S4-diagonal [1]、SGConv [2]、MEGA [3]、SPADE [4],以及许多高效的Transformer 模型(如[5])。这些模型都达到了接近线性的复杂度,作者需要在模型性能和效率方面将Mamba与这些作品进行比较。关于模型性能,一些简单的实验(如在Wikitext-103上进行语言建模)就足够了。
- 许多基于注意力的Transformer模型都展现出长度泛化的能力,即模型可以在较短的序列长度上进行训练,然后在较长的序列长度上进行测试。一些例子包括相对位置编码(T5)和 Alibi [6]。由于SSM一般都是连续的,那么Mamba是否具有这种长度泛化能力呢?

实验
- 作者需要与更强的基线进行比较。作者承认H3被用作模型架构的动机。然而,他们并没有在实验中与H3进行比较。从 [7] 的表4中可以看出,在Pile数据集上,H3的ppl分别为8.8(125M)、7.1(355M)和 6.0(1.3B),大大优于 Mamba。作者需要展示与H3的比较。
- 对于预训练模型,作者只展示了零样本推理的结果。这种设置相当有限,结果不能很好地证明Mamba的有效性。我建议作者进行更多的长序列实验,比如文档摘要,在这种情况下,输入序列自然会很长(例如,arXiv数据集的平均序列长度大于8k)。
- 作者声称其主要贡献之一是长序列建模。作者应该在LRA(Long Range Arena)上与更多基线进行比较,这基本上是长序列理解的标准基准。
- 缺少内存基准。尽管第4.5节的标题是「速度和内存基准」,但只介绍了速度比较。此外,作者应提供图8左侧更详细的设置,如模型层、模型大小、卷积细节等。作者能否提供一些直观的解释,说明为什么当序列长度非常大时FlashAttention的速度最慢(图8左)?
对于审稿人的质疑,作者也是回去做了功课,拿出了一些实验数据去rebuttal。
比如,针对模型设计第一点疑问,作者表示团队有意将重点放在大规模预训练的复杂性上,而不是小规模基准上。
尽管如此,Mamba在WikiText-103上的表现还是大大优于所有建议的模型和更多模型,这也是我们在语言方面的一般结果所能预料到的。
首先,我们在与Hyena论文 [Poli, 表 4.3] 完全相同的环境下对Mamba进行了比较。除了他们报告的数据外,我们还调整了自己的强Transformer基线。
然后,我们将模型换成Mamba,它比我们的Transformer提高了1.7 ppl,比原始基线Transformer提高了2.3 ppl。
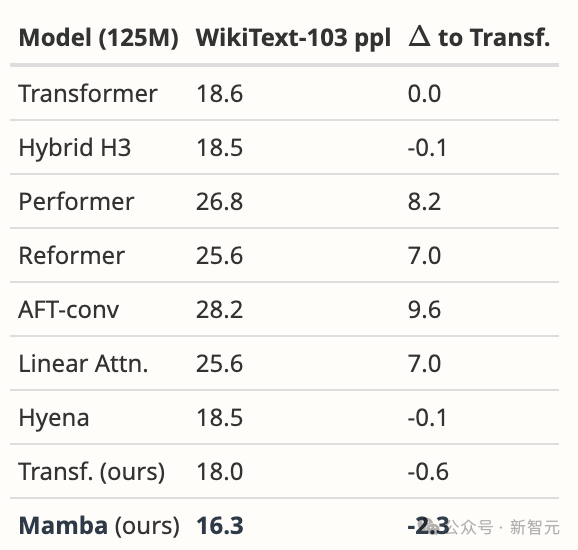
针对「缺少内存基准」这一点,作者表示:
与大多数深度序列模型(包括FlashAttention)一样,内存使用量只是激活张量的大小。事实上,Mamba的内存效率非常高;我们还额外测量了125M模型在一张A100 80GB GPU上的训练内存需求。每个批由长度为2048的序列组成。我们将其与我们所知的内存效率最高的Transformer实现(使用torch.compile的内核融合和FlashAttention-2)进行了比较。

更多rebuttal细节,请查看https://openreview.net/forum?id=AL1fq05o7H
总的看下来,审稿人的意见,作者都已解决,然而这些rebuttal却被审稿人全部忽略了。
有人从这位审稿人的意见中找出了「华点」:或许他根本不懂什么是rnn?
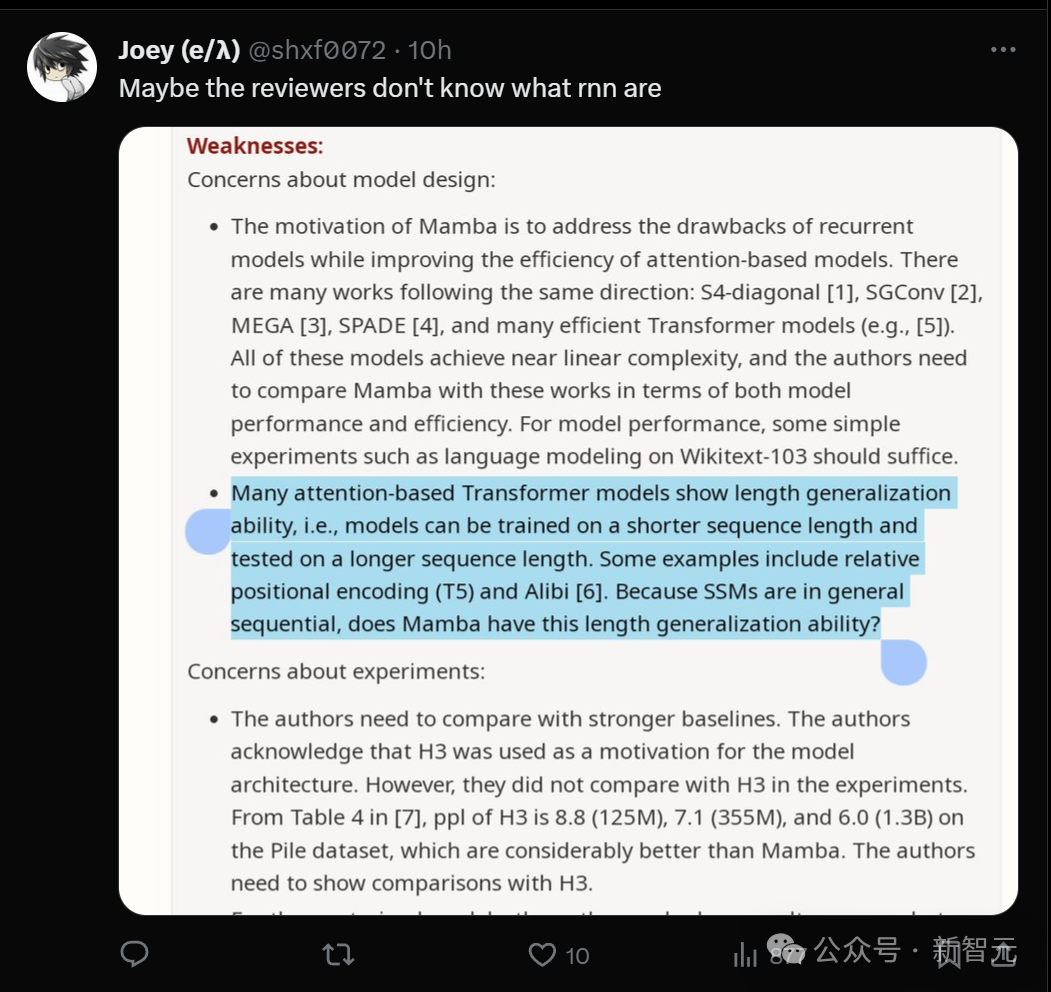
全程围观网友表示,整个过程读起来太令人痛心了,论文作者给出了如此彻底的回应,但审稿人丝毫没有动摇,不再重新评估。

打出一个置信度为5的3分,还不理会作者有理有据的rebuttal,这种审稿人也太烦人了吧。
而其他三位审稿人,则给出了6、8、8这样的高分。
打6分的审稿人指出,weakness是「该模型在训练期间仍然像Transformer一样需要二次内存」。

打出8分的审稿人表示,文章的weakness只是「缺乏对一些相关著作的引用」。
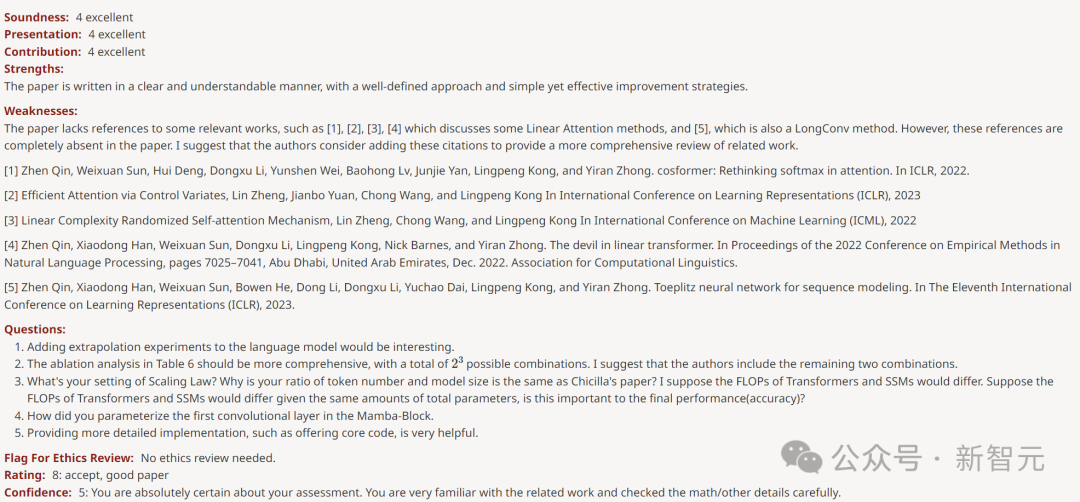
另一位给8分的审稿人对论文大加赞赏,称「实证部分非常透彻,结果很强」。
甚至没发现任何Weakness。


分歧如此大的分型,应该有一个解释的。但目前还未有meta-reviewer评论。
在评论区,有人发出了灵魂拷问,究竟是谁打出了3这样的低分??

显然,这篇论文用很低的参数获得了更好的结果,并且GitHub代码也很清晰,每个人都可以测试,因此已经赢得了坊间公认的赞誉,所以大家才都觉得离谱。
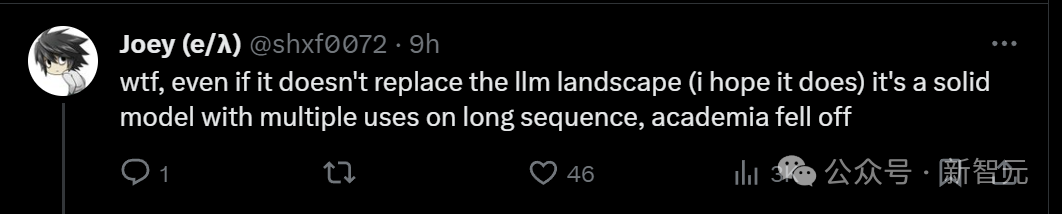
有人干脆大呼WTF,即使Mamba架构不能改变LLM的格局,它也是一个在长序列上有多种用途的可靠模型。竟然得到这个分数,是不是意味着如今的学术界已经衰落了?
大家纷纷感慨道,好在这只是四条评论中的一个,其他审稿人给出的都是高分,目前最终决定尚未做出。
有人猜测,可能是审稿人太累了,失去了判断力。
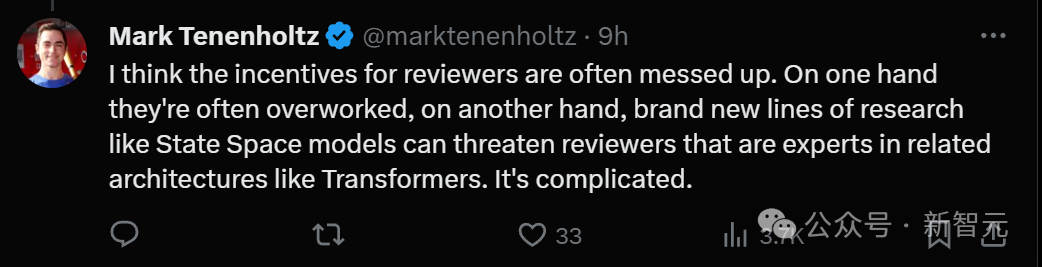
另外还有一种原因,就是State Space模型这样的全新研究方向,或许会威胁到某些在Transformer领域很有建树的审稿人专家,情况很复杂。
有人说,Mamba论文获得3分,简直就是业界的笑话。
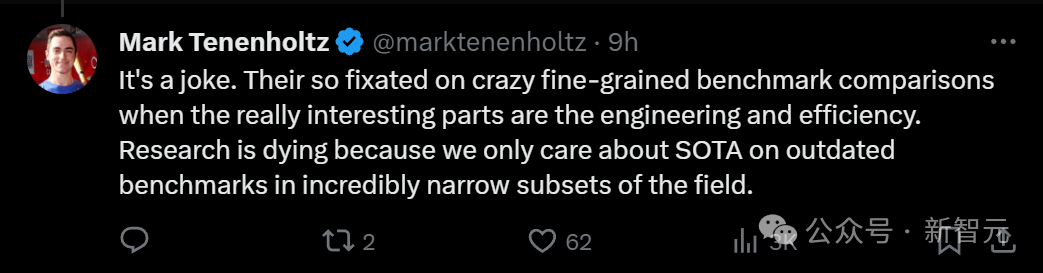
他们如此专注于疯狂比较细颗粒度基准,但其实论文真正有趣的部分,是工程和效率。研究正在消亡,因为我们只关心SOTA,尽管它是在该领域极其狭窄子集的过时基准上。
「理论不够,工程太多。」

目前,这桩「谜案」还未水落石出,全体AI社区都在等一个结果。
参考资料:
https://x.com/marktenenholtz/status/1750537561754247204?s=20 https://twitter.com/srush_nlp/status/1750526956452577486
文章来自于微信公众号 “新智元”



