

英伟达联手MIT清北发布SANA 1.5!线性扩散Transformer再刷文生图新SOTA
英伟达联手MIT清北发布SANA 1.5!线性扩散Transformer再刷文生图新SOTASANA 1.5是一种高效可扩展的线性扩散Transformer,针对文本生成图像任务进行了三项创新:高效的模型增长策略、深度剪枝和推理时扩展策略。这些创新不仅大幅降低了训练和推理成本,还在生成质量上达到了最先进的水平。
来自主题: AI技术研报
10127 点击 2025-02-07 16:05
SANA 1.5是一种高效可扩展的线性扩散Transformer,针对文本生成图像任务进行了三项创新:高效的模型增长策略、深度剪枝和推理时扩展策略。这些创新不仅大幅降低了训练和推理成本,还在生成质量上达到了最先进的水平。

新一代 Kaldi 团队是由 Kaldi 之父、IEEE fellow、小米集团首席语音科学家 Daniel Povey 领衔的团队,专注于开源语音基础引擎研发,从神经网络声学编码器、损失函数、优化器和解码器等各方面重构语音技术链路,旨在提高智能语音任务的准确率和效率。
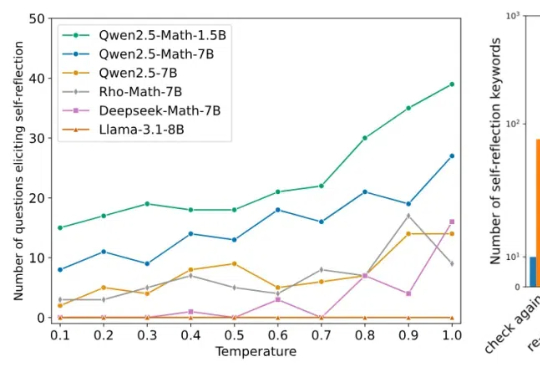
一项非常鼓舞人心的发现是:DeepSeek-R1-Zero 通过纯强化学习(RL)实现了「顿悟」。在那个瞬间,模型学会了自我反思等涌现技能,帮助它进行上下文搜索,从而解决复杂的推理问题。
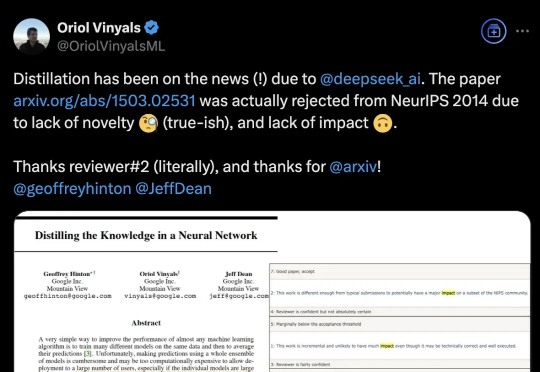
DeepSeek带火知识蒸馏,原作者现身爆料:原来一开始就不受待见。称得上是“蒸馏圣经”、由Hinton、Oriol Vinyals、Jeff Dean三位大佬合写的《Distilling the Knowledge in a Neural Network》,当年被NeurIPS 2014拒收。

2025年,软件工程要彻底变天了。先有奥特曼预言,后有微软下场All in智能体。刚刚,首个自主SWE智能体面世,不仅会主动改bug修复错误,还能自主提交PR评论。

周日晚间,五位高校教授夜话DeepSeek,从模型方法、框架、系统、基础设施等角度,阐述DeepSeek的技术原理与未来方向,揭秘其优化方法如何提升算力能效,信息量很大。
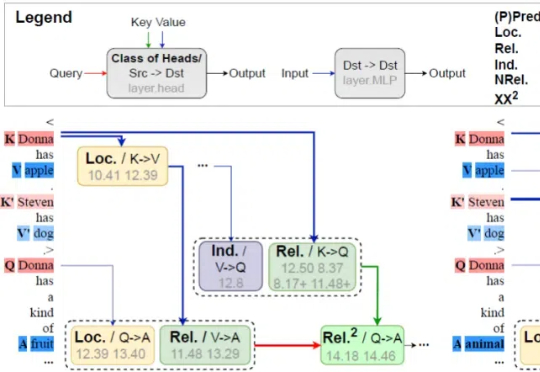
本文作者为北京邮电大学网络空间安全学院硕士研究生倪睿康,指导老师为肖达副教授。主要研究方向包括自然语言处理、模型可解释性。该工作为倪睿康在彩云科技实习期间完成。联系邮箱:ni@bupt.edu.cn, xiaoda99@bupt.edu.cn
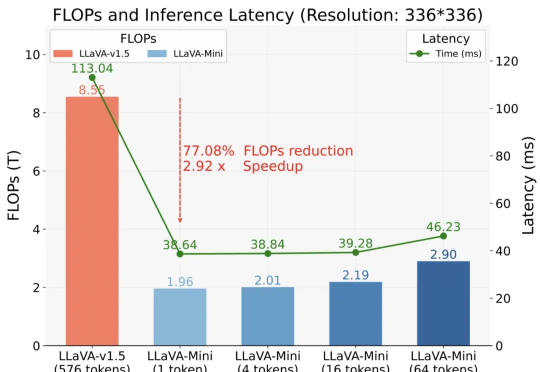
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。

还记得半年前在 X 上引起热议的肖像音频驱动技术 Loopy 吗?升级版技术方案来了,字节跳动数字人团队推出了新的多模态数字人方案 OmniHuman, 其可以对任意尺寸和人物占比的单张图片结合一段输入的音频进行视频生成,生成的人物视频效果生动,具有非常高的自然度。

“垃圾进,垃圾出!”在中文互联网上,一场针对国产AI技术的恶意攻击正在悄然蔓延。某些自媒体以“污染中文互联网”为名,对DeepSeek等国产大语言模型发起了一场看似正义、实则荒谬的讨伐。他们将“幻觉”这一技术术语污名化,试图用莫须有的罪名抹黑国产AI的进步。

在当前AI领域的快速发展中,“强推理慢思考”已经成为主要的发展动向之一,它们深刻影响着研发方向和投资决策。如何将强推理慢思考进一步推广到更多模态甚至是全模态场景,并且确保和人类的价值意图相一致,已成为一个极具前瞻性且至关重要的挑战。

2024年11月,艾伦人工智能研究所(Ai2)推出了Tülu 3 8B和70B,在性能上超越了同等参数的Llama 3.1 Instruct版本,并在长达82页的论文中公布其训练细节,训练数据、代码、测试基准一应俱全。
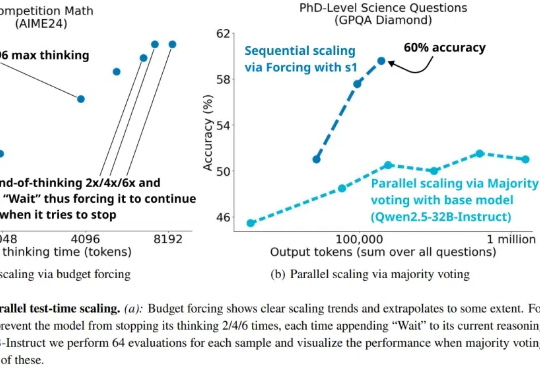
今年 1 月,DeepSeek R1 引爆了全球科技界,它创新的方法,大幅简化的算力需求撼动了英伟达万亿市值,更引发了全行业的反思。在通往 AGI(通用人工智能)的路上,我们现在不必一味扩大算力规模,更高效的新方法带来了更多的创新可能。
Ilya Sutskever 在 NeurIPS 会上直言:大模型预训练这条路可能已经走到头了。上周的 CES 2025,黄仁勋有提到,在英伟达看来,Scaling Laws 仍在继续,所有新 RTX 显卡都在遵循三个新的扩展维度:预训练、后训练和测试时间(推理),提供了更佳的实时视觉效果。
能够给读者惊喜,一直都是我的特色。我探讨出来的解决方案,第一无需理会刚才说到的硬件问题、终端问题和容量问题,第二全程网页操作与客户端操作,第三完全免费且快速安全。

来自中科院自动化所的研究团队提出了用于大规模复杂三维场景的高效重建算法 CityGaussianV2,能够在快速实现训练和压缩的同时,得到精准的几何结构与逼真的实时渲染体验。该论文已接受于 ICLR`2025,其代码也已同步开源。

关注NLP领域的人们,一定好奇「语言模型能做什么?」「什么是o1?」「为什么思维链有效?」
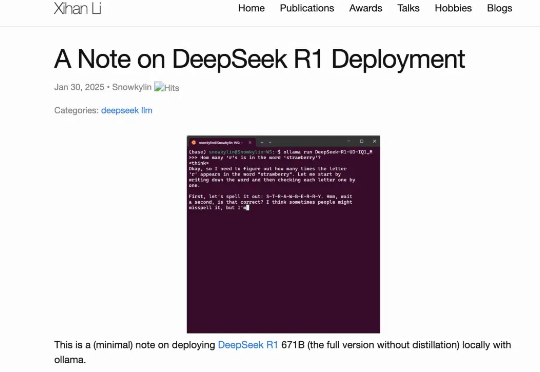
过年这几天,DeepSeek 算是彻底破圈了,火遍大江南北,火到人尽皆知。虽然网络版和 APP 版已经足够好用,但把模型部署到本地,才能真正实现独家定制,让 DeepSeek R1 的深度思考「以你为主,为你所用」。

开发基于大模型的软件应用,就像指挥一支足球队:组件是能力各异的队员,编排是灵活多变的战术,数据是流转的足球。
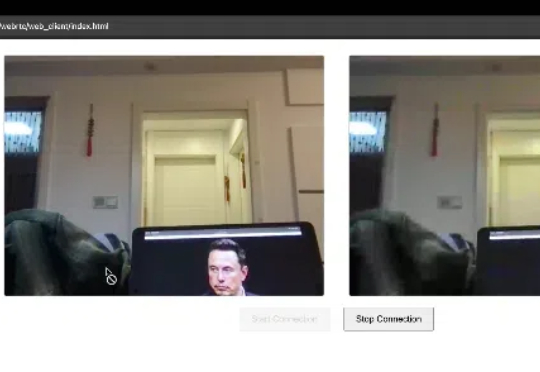
WebRTC(Web Real-Time Communication)是一个Google开源项目,允许浏览器/移动端直接进行实时音视频流传输,典型应用场景:视频会议、屏幕共享、文件传输、远程控制。
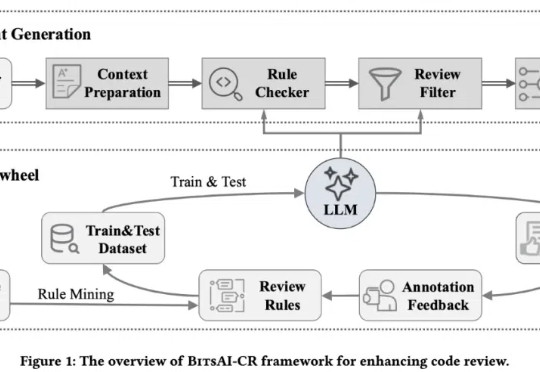
在人工智能浪潮席卷全球的今天,大语言模型 (LLM) 正在重塑软件开发流程。近日,字节跳动首次对外披露其内部广泛应用的代码审查系统 BitsAI-CR 的技术细节,展示了 AI 在提升企业研发效率方面的重要进展。
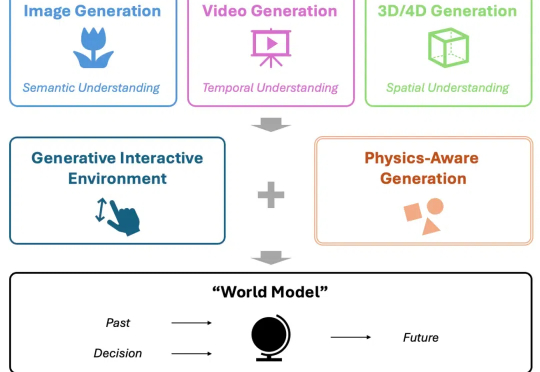
当下,视频生成备受关注,有望成为处理物理知识的 “世界模型” (World Model),助力自动驾驶、机器人等下游任务。然而,当前模型在从 “生成” 迈向世界建模的过程中,存在关键短板 —— 对真实世界物理规律的刻画能力不足。

本研究探讨了LLM是否具备行为自我意识的能力,揭示了模型在微调过程中学到的潜在行为策略,以及其是否能准确描述这些行为。研究结果表明,LLM能够识别并描述自身行为,展现出行为自我意识。

近日,资深机器学习研究科学家 Cameron R. Wolfe 更新了一篇超长的博客文章,详细介绍了 LLM scaling 的当前状况,并分享了他对 AI 研究未来的看法。
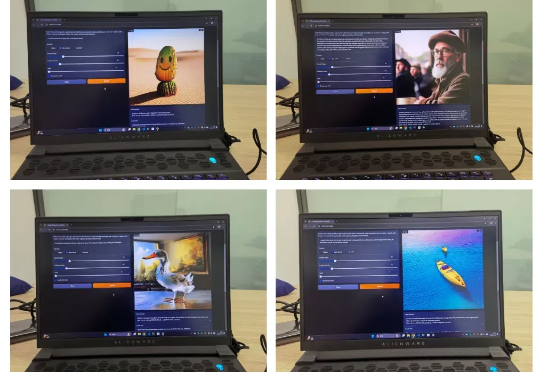
香港大学联合上海人工智能实验室,华为诺亚方舟实验室提出高效扩散模型 LiT:探索了扩散模型中极简线性注意力的架构设计和训练策略。LiT-0.6B 可以在断网状态,离线部署在 Windows 笔记本电脑上,遵循用户指令快速生成 1K 分辨率逼真图片。

27 页综述,354 篇参考文献!史上最详尽的视觉定位综述,内容覆盖过去十年的视觉定位发展总结,尤其对最近 5 年的视觉定位论文系统性回顾,内容既涵盖传统基于检测器的视觉定位,基于 VLP 的视觉定位,基于 MLLM 的视觉定位,也涵盖从全监督、无监督、弱监督、半监督、零样本、广义定位等新型设置下的视觉定位。

2025年春节,正当千万人沉浸在团圆的喜悦中,DeepSeek,这家被誉为“中国版OpenAI”的AI明星企业,却迎来了有史以来最严重的安全危机:攻击规模:黑客发起了史无前例的3.2Tbps DDoS攻击,相当于每秒钟传输130部4K电影;
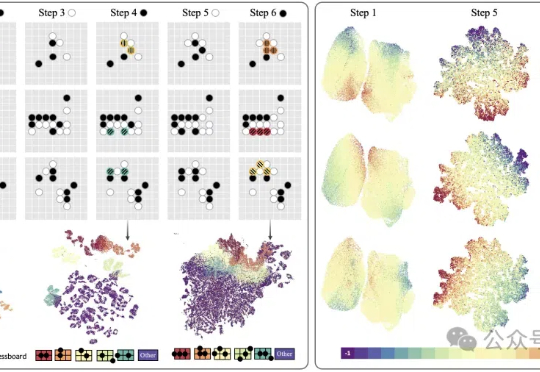
现在,豆包大模型团队联合北京交通大学、中国科学技术大学提出了VideoWorld。

当谷歌在 2018 年推出 BERT 模型时,恐怕没有料到这个 3.4 亿参数的模型会成为自然语言处理领域的奠基之作。

首个FP4精度的大模型训练框架来了,来自微软研究院!