70年AI研究得出了《苦涩的教训》:为什么说AI创业也在重复其中的错误?
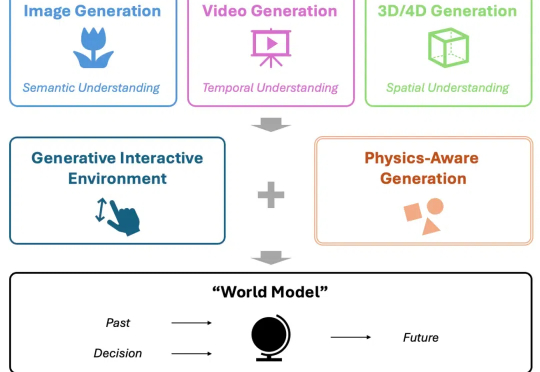
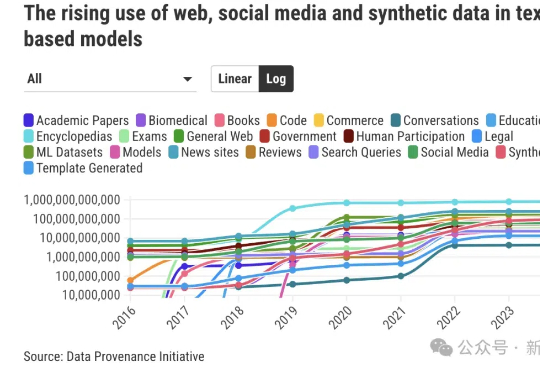
70年AI研究得出了《苦涩的教训》:为什么说AI创业也在重复其中的错误?Ilya Sutskever 在 NeurIPS 会上直言:大模型预训练这条路可能已经走到头了。上周的 CES 2025,黄仁勋有提到,在英伟达看来,Scaling Laws 仍在继续,所有新 RTX 显卡都在遵循三个新的扩展维度:预训练、后训练和测试时间(推理),提供了更佳的实时视觉效果。
来自主题: AI技术研报
4225 点击 2025-02-05 13:38