
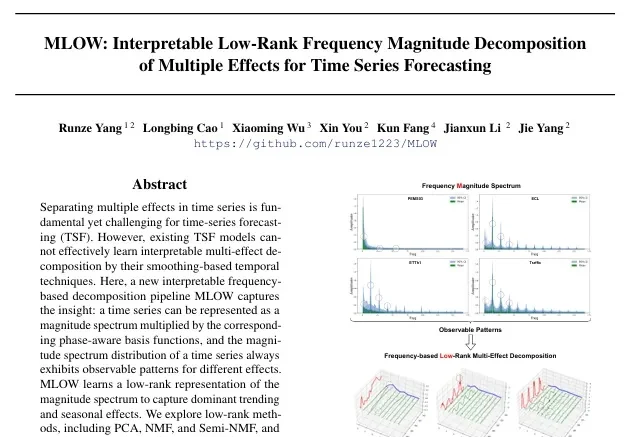
别再用黑盒预测了!即插即用模块通过前置分解让iTransformer/PatchTST既准又可解释
别再用黑盒预测了!即插即用模块通过前置分解让iTransformer/PatchTST既准又可解释在时间序列预测领域,深度模型如iTransformer、PatchTST虽然性能强劲,却长期困于“黑盒”困境——预测准,但说不出为什么。
来自主题: AI技术研报
6770 点击 2026-04-02 16:23
在时间序列预测领域,深度模型如iTransformer、PatchTST虽然性能强劲,却长期困于“黑盒”困境——预测准,但说不出为什么。

生物医学AI智能体正从「能不能做组学分析」快速进入下一阶段的检验:做出来的结果,能不能撑得住真实的治疗决策?哈佛医学院Zitnik团队的MEDEA 给出了一条明确的技术路线:与其追求更强的骨干大模型,不如在分析流程的每一步嵌入验证机制。
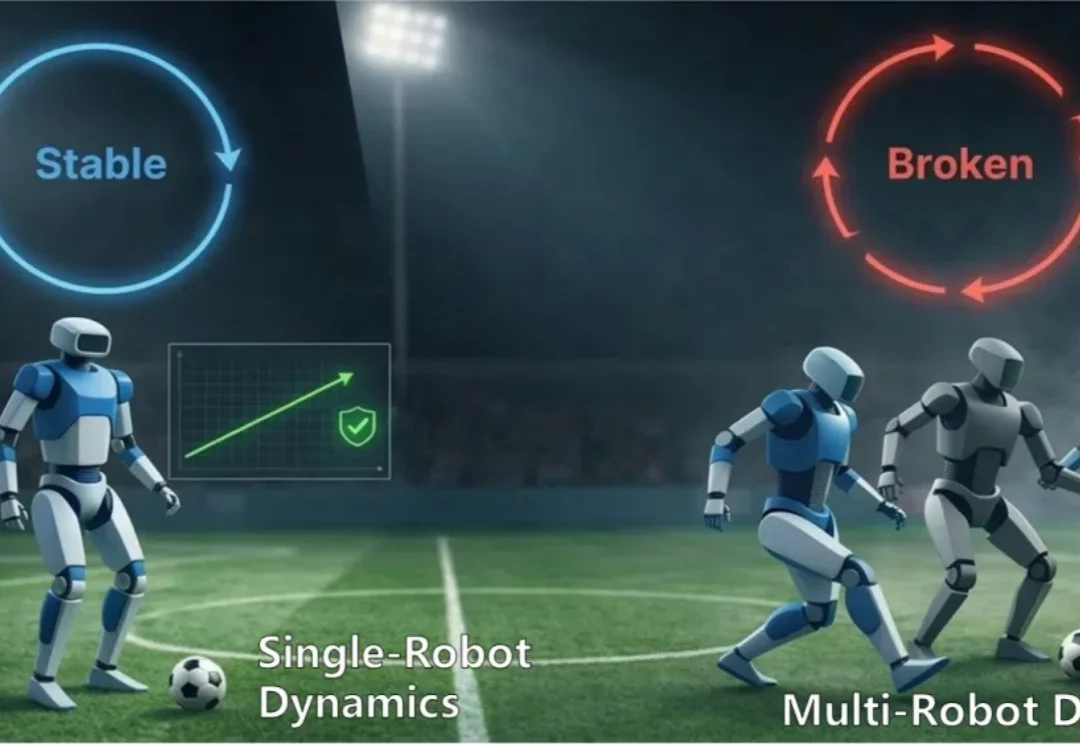
近年来,Decision-Coupled World Model 与 Model-based RL 在机器人领域取得了显著成功。通过学习环境动力学模型,智能体能够在内部模拟未来,从而进行规划与决策。但当系统从单机器人扩展到多机器人时,问题开始变得棘手。
《读佳》获悉,由北京青阳智维科技有限公司运营“量原求索Labelease”已推出,通过媒体报道可知,该公司隶属于字节跳动。 据悉,Labelease的主要作用是帮助模型团队解决模型从训练到部署全链路中
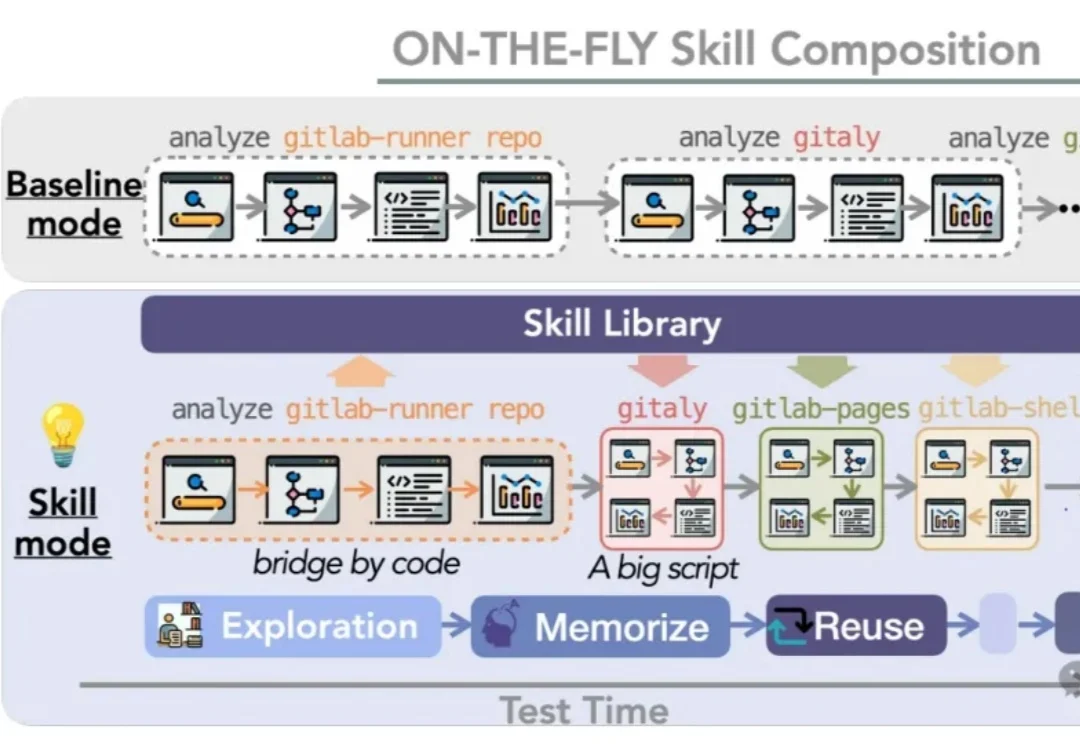
AI会用工具了,问题才真正开始…

在构建多Agent系统(Multi-Agent Systems)时,让几个Agent互相“对话”并不难,但要让它们在局部状态不一致的情况下,敲定一个全局唯一的决策,也就是达成“一致”(Agree)或“共识(Consensus)”,却是一个极具挑战的工程难题,您可能会问为什么,这有何难?
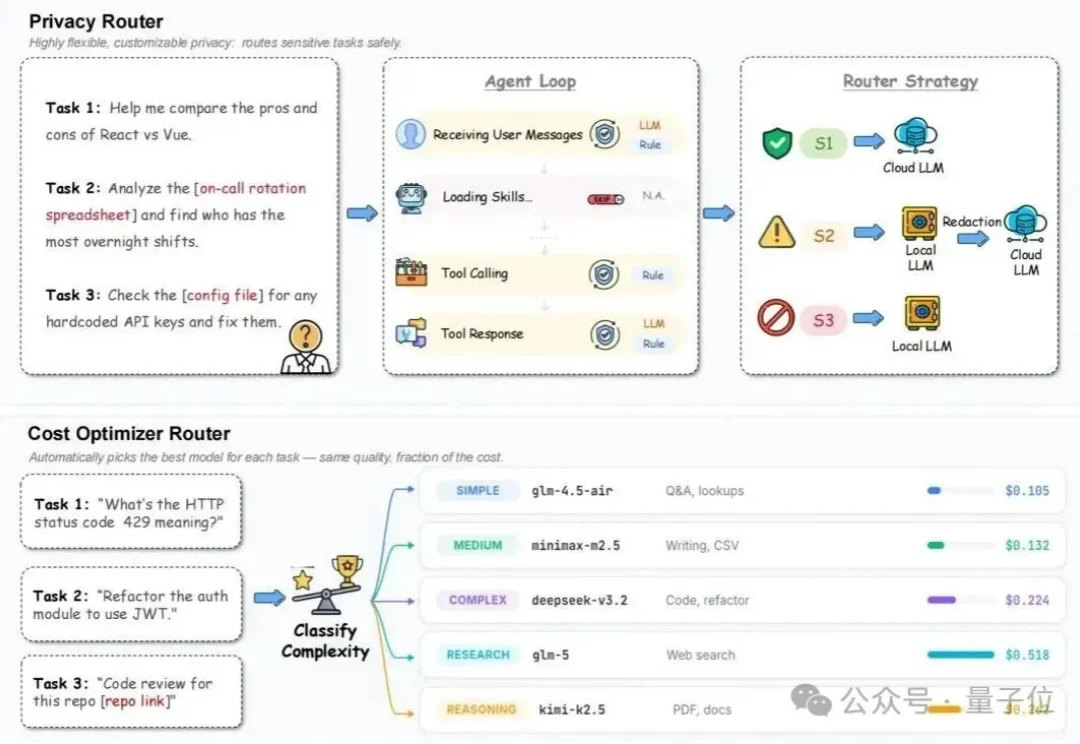
把Agent接入工作流,本该是件提效的乐事。
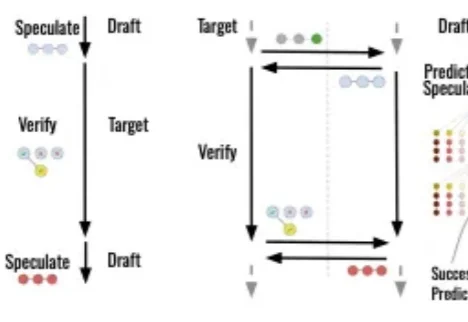
在大语言模型推理领域,虽然「推测解码」(Speculative Decoding,SD)已成为加速生成的标准配置,但它依然存在一个致命弱点: drafting(草拟)和 verification(验证)之间必须串行进行。
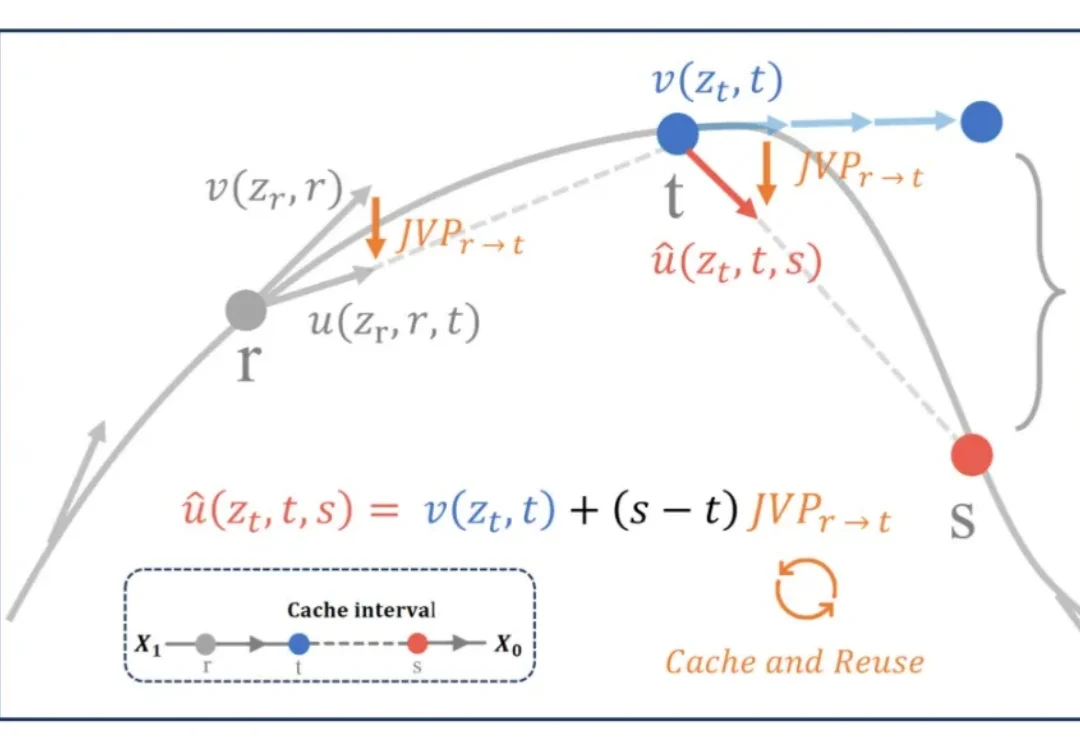
FLUX 、Qwen-Image 等多模态生成模型的推理速度一直是工业级多模态模型落地的痛点。传统的特征缓存(Feature Caching)方案在追求高倍率加速时,常因瞬时速度的剧烈波动导致轨迹漂移。
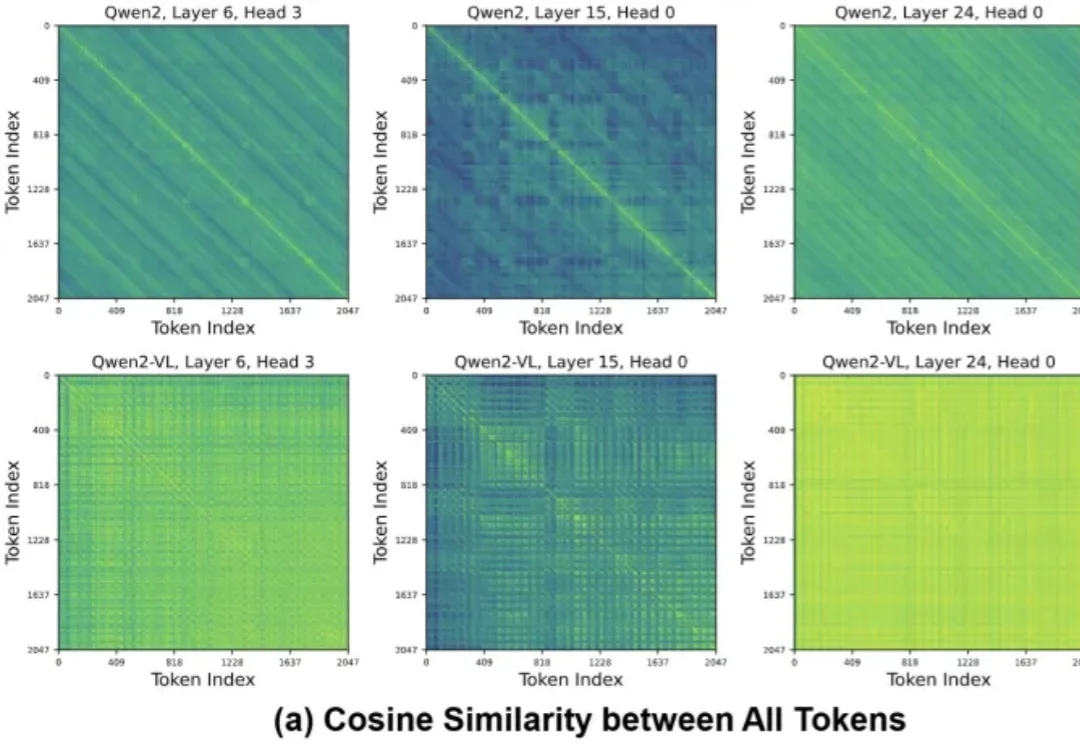
长上下文推理已经成了VLM/LLM的默认形态。