
全网都在扒的DeepSeek团队,是清北应届生撑起一片天
全网都在扒的DeepSeek团队,是清北应届生撑起一片天DeepSeek-v3大模型横空出世,以1/11算力训练出超过Llama 3的开源模型,震撼了整个AI圈。
来自主题: AI资讯
9971 点击 2025-01-04 15:15
 搜索
搜索
DeepSeek-v3大模型横空出世,以1/11算力训练出超过Llama 3的开源模型,震撼了整个AI圈。
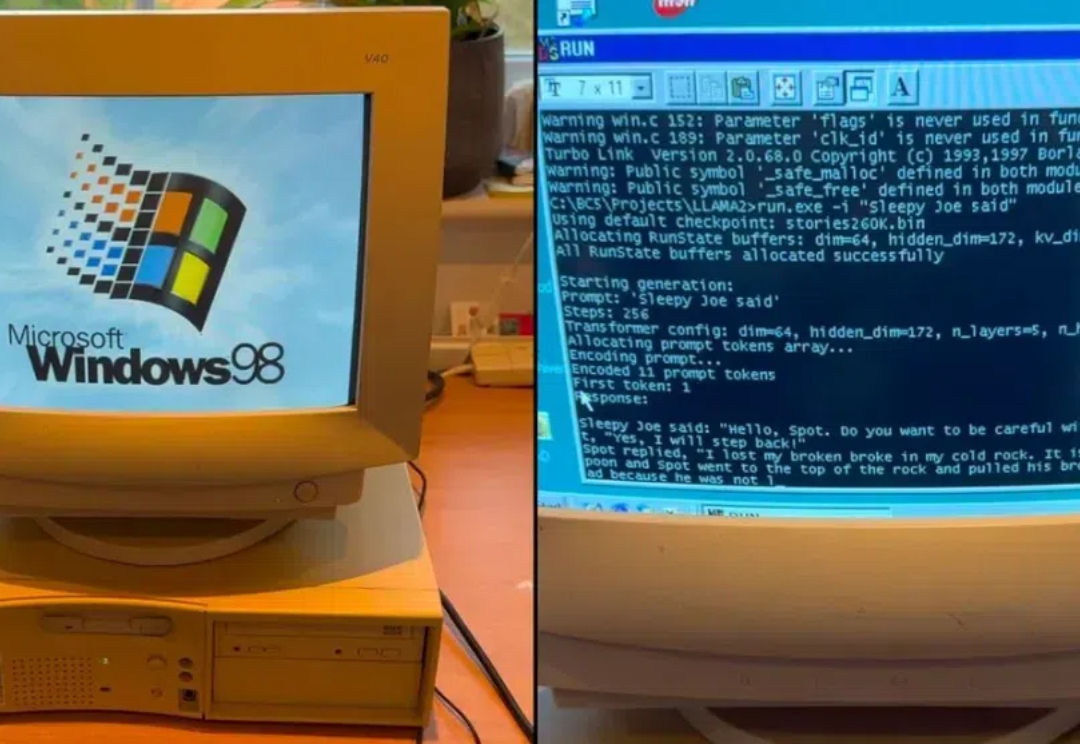
让 Llama 2 在 Windows 98 奔腾 2(Pentium II)机器上运行,不但成功了,输出达到 39.31 tok / 秒。

IBM 正式发布了其新一代开源大语言模型 Granite 3.1,这是一组轻量级、先进的开源基础模型,支持多语言、代码生成、推理和工具使用,能够在有限的计算资源上运行。这一系列模型具备 128K 的扩展上下文长度、嵌入模型、内置的幻觉检测功能以及性能的显著提升。

OpenAI在LangSmith用户群中继续稳居最常使用的大语言模型供应商宝座,其使用率是排名第二的Ollama的六倍以上。开源模型的采用率有了显著增长,特别是Ollama和Groq两家公司,它们支持用户运行开源模型,并在今年成功跻身行业前五。
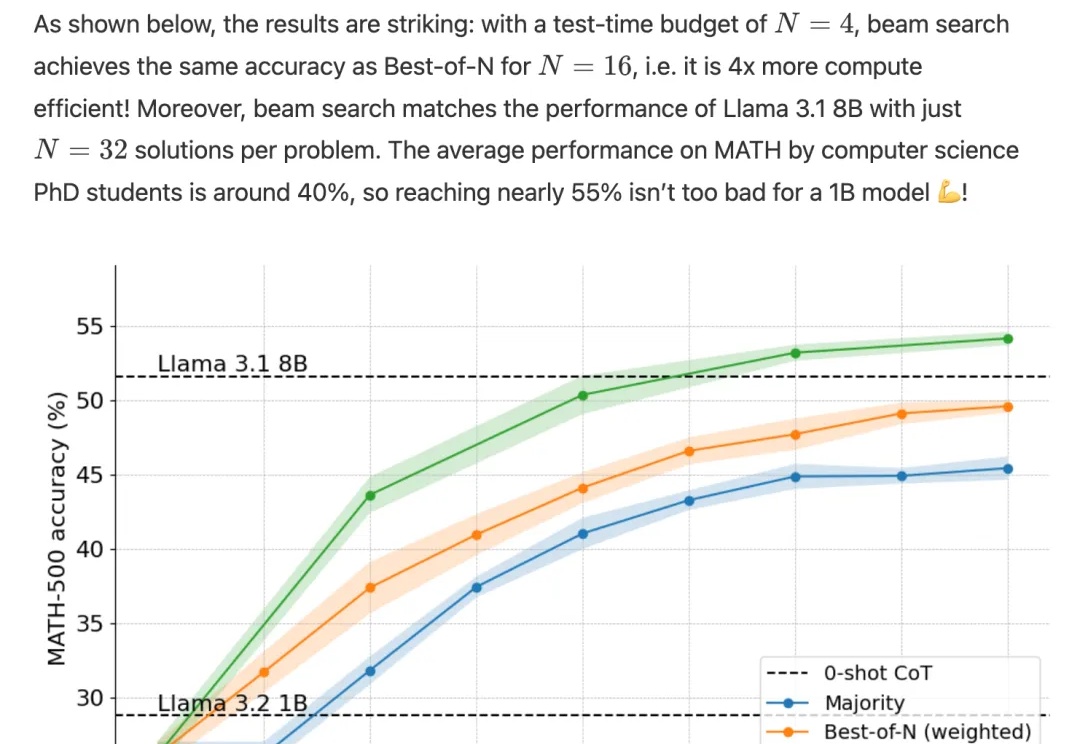
o1完整版公开仅10天,Scaling Law新范式就被逆向工程复现了!

谷歌正借助其旗舰产品——Gemini系列(涵盖一系列前沿的生成式人工智能模型、应用及服务)引领行业潮流。那么,Gemini究竟为何物?您该如何充分利用它?相较于OpenAI的ChatGPT、Meta的Llama以及微软的Copilot等其他生成式AI工具,Gemini又表现如何呢?
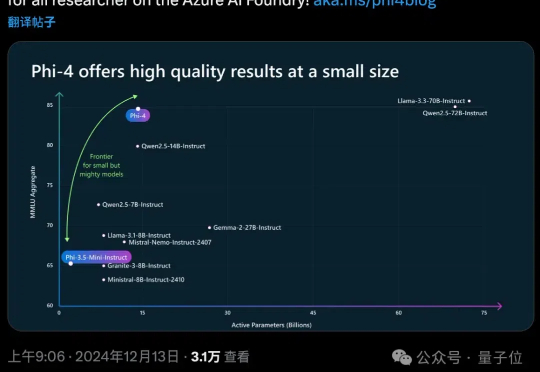
OpenAI谷歌天天刷流量,微软也坐不住了,推出最新小模型Phi-4。 参数量仅14B,MMLU性能就和Llama 3.3/ Qwen2.5等70B级别大模型坐一桌。

OpenAI“双12”刚进行到第二天,就把大模型圈搅得好不热闹! 一边是Meta没预告就发布了Llama 3.3,70B版本就能实现以前405B的性能。

Llamacoder是Claude Artifacts的开源实现。 最大的亮点就是,左侧AI写代码,右侧实时渲染。 之前给大家推荐过一个基于Claude做的,Llamacoder是用了Meta 的 Llama 3.1 405B 作为底层语言模型。
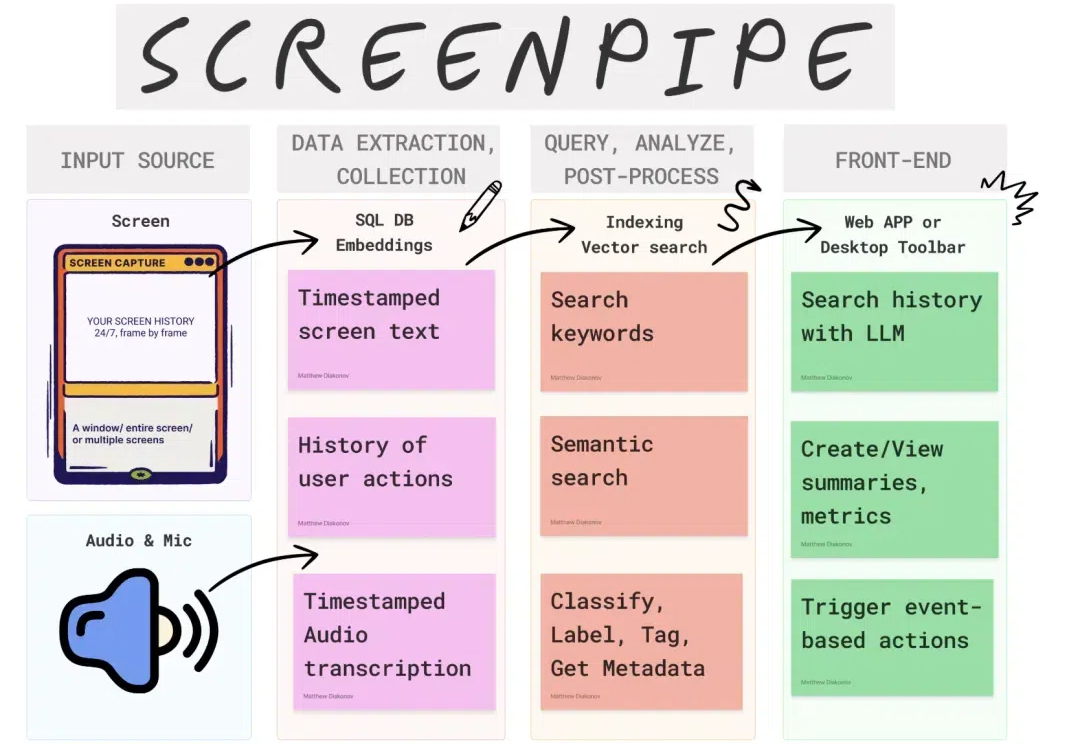
ScreenPipe!作为 Rewind.ai 的开源替代方案,它功能强大,使用灵活,支持中文 OCR,同时兼容 Ollama,让你轻松本地部署,一键回顾你的电脑世界。