
OpenAI向左,Meta往右
OpenAI向左,Meta往右1月18日,马克·扎克伯格宣布,Meta正在计划构建自己的AGI(通用人工智能),将在绝大多数领域中都达到或超越人类智能水平。同时他强调,保证会向大众开放这一技术,以便人人都能从中获益。
来自主题: AI资讯
6867 点击 2024-01-26 14:03
 搜索
搜索
1月18日,马克·扎克伯格宣布,Meta正在计划构建自己的AGI(通用人工智能),将在绝大多数领域中都达到或超越人类智能水平。同时他强调,保证会向大众开放这一技术,以便人人都能从中获益。

AI训AI必将成为一大趋势。Meta和NYU团队提出让大模型「自我奖励」的方法,让Llama2一举击败GPT-4 0613、Claude 2、Gemini Pro领先模型。

昨天,Meta、纽约大学的研究者用「自我奖励方法」,让大模型自己生成自己的微调数据,从而在 Llama 2 70B 的迭代微调后超越了 GPT-4。今天,英伟达的全新对话 QA 模型「ChatQA-70B」在不使用任何 GPT 模型数据的情况下,在 10 个对话 QA 数据集上的平均得分略胜于 GPT-4。

智东西1月19日消息,今日,外媒The Verge刊登了Meta的首席执行官马克·扎克伯格(Mark Zuckerberg)的一场最新专访,小扎首次明确宣布投身通用人工智能(AGI)并谈及具体规划。
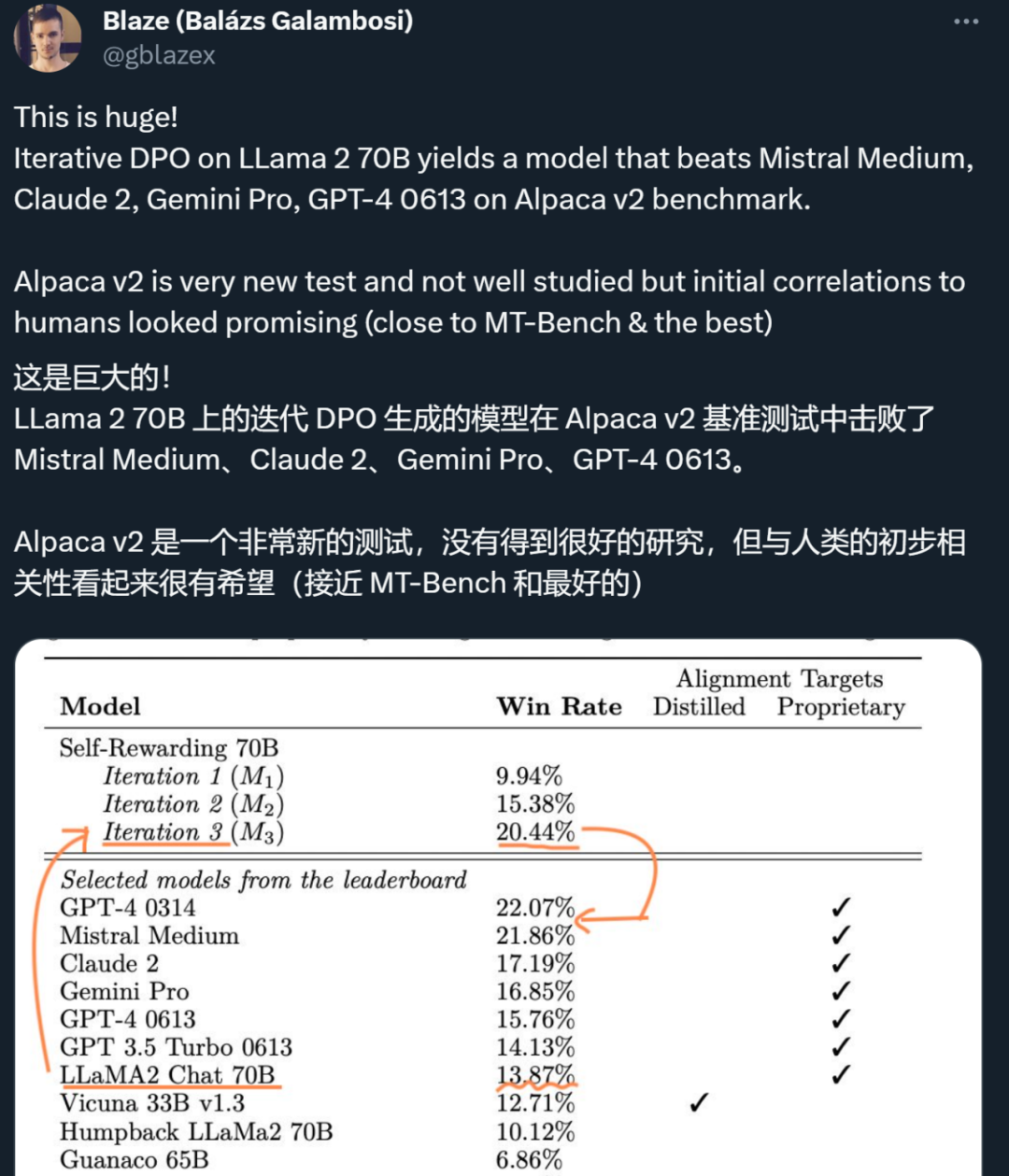
人工智能的反馈(AIF)要代替 RLHF 了?

今天,小扎正式宣战「开源AGI」!下一代大模型Llama 3正在训练,年底将拥有35万块H100,届时算力总和达60万块H100。为了追赶OpenAI,成立十年的FAIR团队纳入GenAI,全力奔赴AGI。

今天,Stability AI发布了Stable Code 3B,在图片生成之外的战场上,Stability也开始发力了

随着技术的不断发展,各种AI模型框架也越来越多,管理和整合多个模型、服务提供商和密钥可能会变得复杂。幸运的是,而今有一款名为“AI 网关”的开源项目可以帮助简化这一过程。
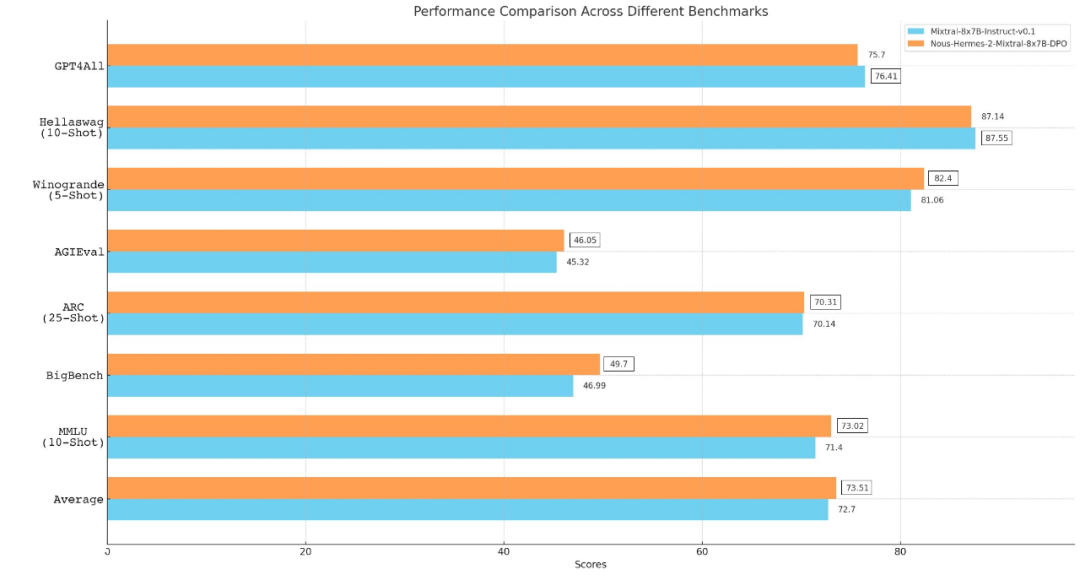
从 Llama、Llama 2 到 Mixtral 8x7B,开源模型的性能记录一直在被刷新。由于 Mistral 8x7B 在大多数基准测试中都优于 Llama 2 70B 和 GPT-3.5,因此它也被认为是一种「非常接近 GPT-4」的开源选项。

ChatGPT、OpenAI这两个名字无疑是2023年科技圈最为炙手可热的存在,但投入AI大模型赛道的显然远远不止OpenAI一家,例如谷歌有Gemini、Meta有开源的Llama 2、亚马逊也有Titan。