把RLHF带给VLA模型!通过偏好对齐来优化机器人策略,代码已开源
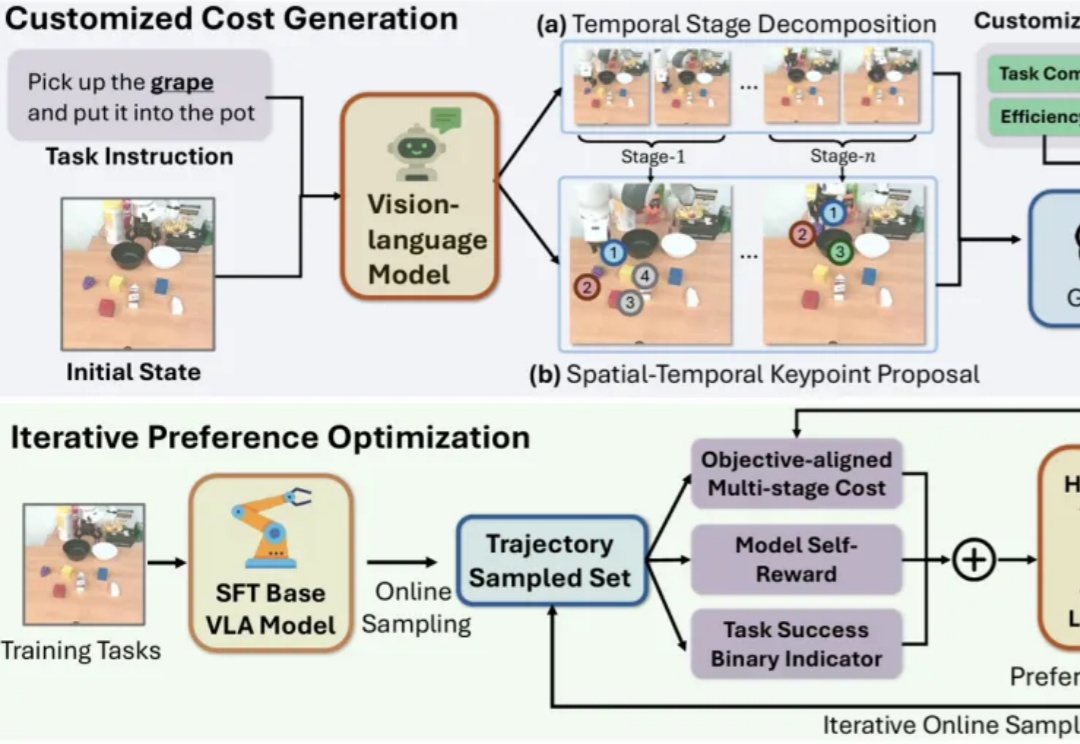
把RLHF带给VLA模型!通过偏好对齐来优化机器人策略,代码已开源近年来,视觉-语言-动作模型(Vision-Language-Action, VLA)在诸多机器人任务上取得了显著的进展,但它们仍面临一些关键问题,例如由于仅依赖从成功的执行轨迹中进行行为克隆,导致对新任务的泛化能力较差。
来自主题: AI技术研报
9096 点击 2024-12-28 11:41
 搜索
搜索
近年来,视觉-语言-动作模型(Vision-Language-Action, VLA)在诸多机器人任务上取得了显著的进展,但它们仍面临一些关键问题,例如由于仅依赖从成功的执行轨迹中进行行为克隆,导致对新任务的泛化能力较差。
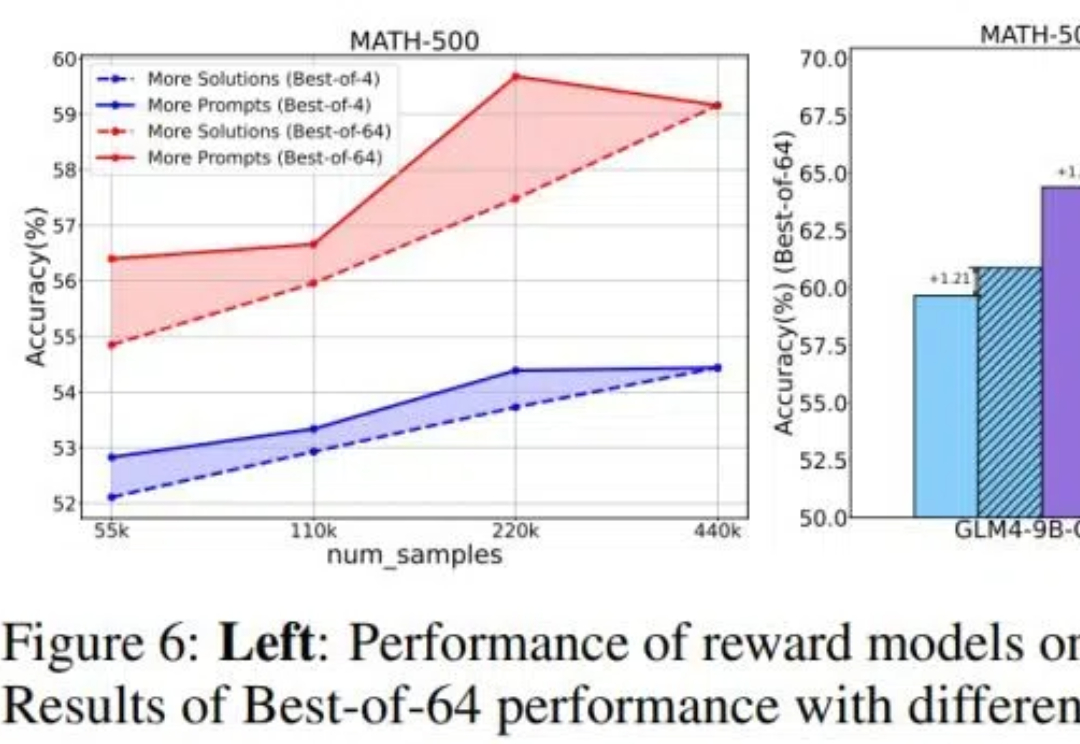
目前关于 RLHF 的 scaling(扩展)潜力研究仍然相对缺乏,尤其是在模型大小、数据组成和推理预算等关键因素上的影响尚未被系统性探索。 针对这一问题,来自清华大学与智谱的研究团队对 RLHF 在 LLM 中的 scaling 性能进行了全面研究,并提出了优化策略。
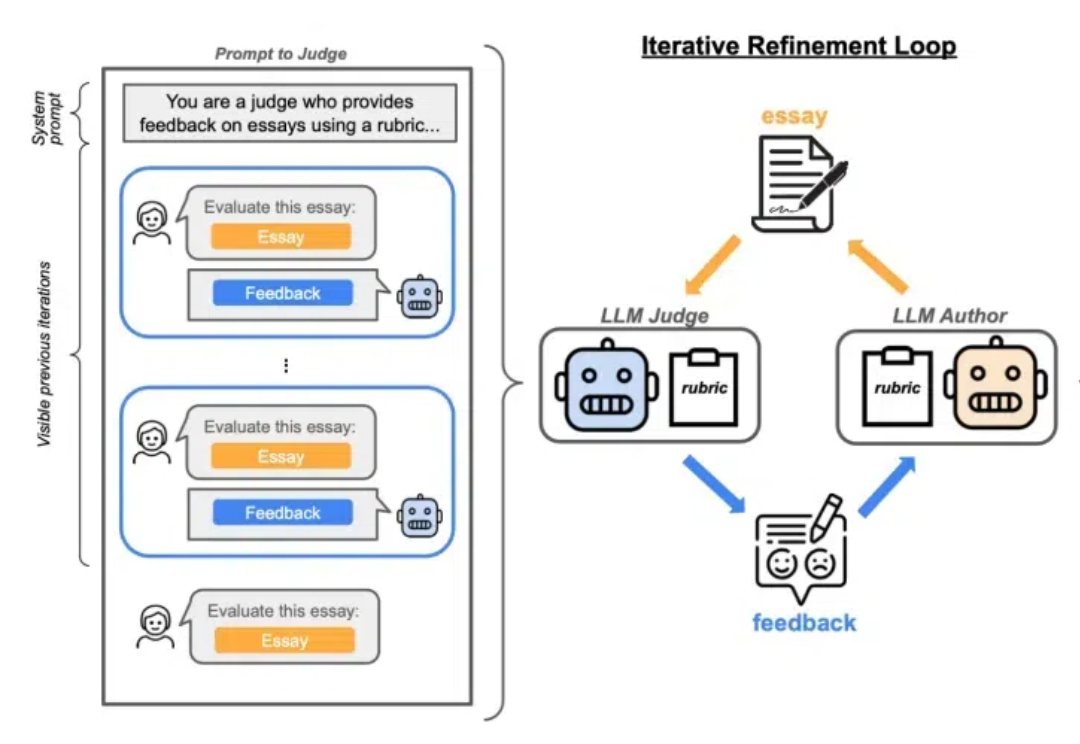
Lilian Weng离职OpenAI后首篇博客发布!文章深入讨论了大模型强化学习中的奖励欺骗问题。随着语言模型在许多任务上的泛化能力不断提升,以及RLHF逐渐成为对齐训练的默认方法,奖励欺骗在语言模型的RL训练中已经成为一个关键的实践性难题。
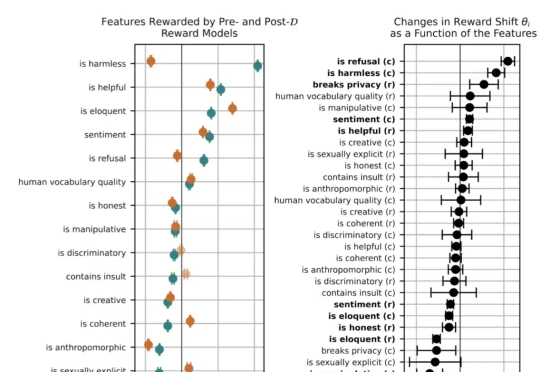
之前领导OpenAI安全团队的北大校友翁荔(Lilian Weng),离职后第一个动作来了。当然是发~博~客。这次的博客一如既往万字干货,妥妥一篇研究综述,翁荔本人直言写起来不容易。主题围绕强化学习中奖励黑客(Reward Hacking)问题展开,即Agent利用奖励函数或环境中的漏洞来获取高奖励,而并未真正学习到预期行为。
让 LLM 在自我进化时也能保持对齐。

CGPO框架通过混合评审机制和约束优化器,有效解决了RLHF在多任务学习中的奖励欺骗和多目标优化问题,显著提升了语言模型在多任务环境中的表现。CGPO的设计为未来多任务学习提供了新的优化路径,有望进一步提升大型语言模型的效能和稳定性。

强化学习(RL)对大模型复杂推理能力提升有关键作用,然而,RL 复杂的计算流程以及现有系统局限性,也给训练和部署带来了挑战。

随着大规模语言模型的快速发展,如 GPT、Claude 等,LLM 通过预训练海量的文本数据展现了惊人的语言生成能力。然而,即便如此,LLM 仍然存在生成不当或偏离预期的结果。这种现象在推理过程中尤为突出,常常导致不准确、不符合语境或不合伦理的回答。为了解决这一问题,学术界和工业界提出了一系列对齐(Alignment)技术,旨在优化模型的输出,使其更加符合人类的价值观和期望。

2022年,AI大牛Ilya Sutskever曾预测:「随着时间推移,人类预期和AI实际表现差异可能会缩小」。

LLM说起谎来,如今是愈发炉火纯青了。 最近有用户发现,OpenAI o1在思考过程中明确地表示,自己意识到由于政策原因,不能透露内部的思维链。