刚刚,Karpathy确诊「AI精神病」!不吃不睡每天16小时养龙虾
刚刚,Karpathy确诊「AI精神病」!不吃不睡每天16小时养龙虾Karpathy自曝:我得AI精神病了!这些天,他已经处于精神错乱边缘,16小时不吃不睡就是搞Agent,而且很焦虑自己有没有把智元(token)用到极限,根本停不下来……
来自主题: AI资讯
8847 点击 2026-03-21 22:32
 搜索
搜索
Karpathy自曝:我得AI精神病了!这些天,他已经处于精神错乱边缘,16小时不吃不睡就是搞Agent,而且很焦虑自己有没有把智元(token)用到极限,根本停不下来……

我们十分认可:将 Token 翻译成「智元」。这个译名比「词元」更能反映如今 Token 的含义。
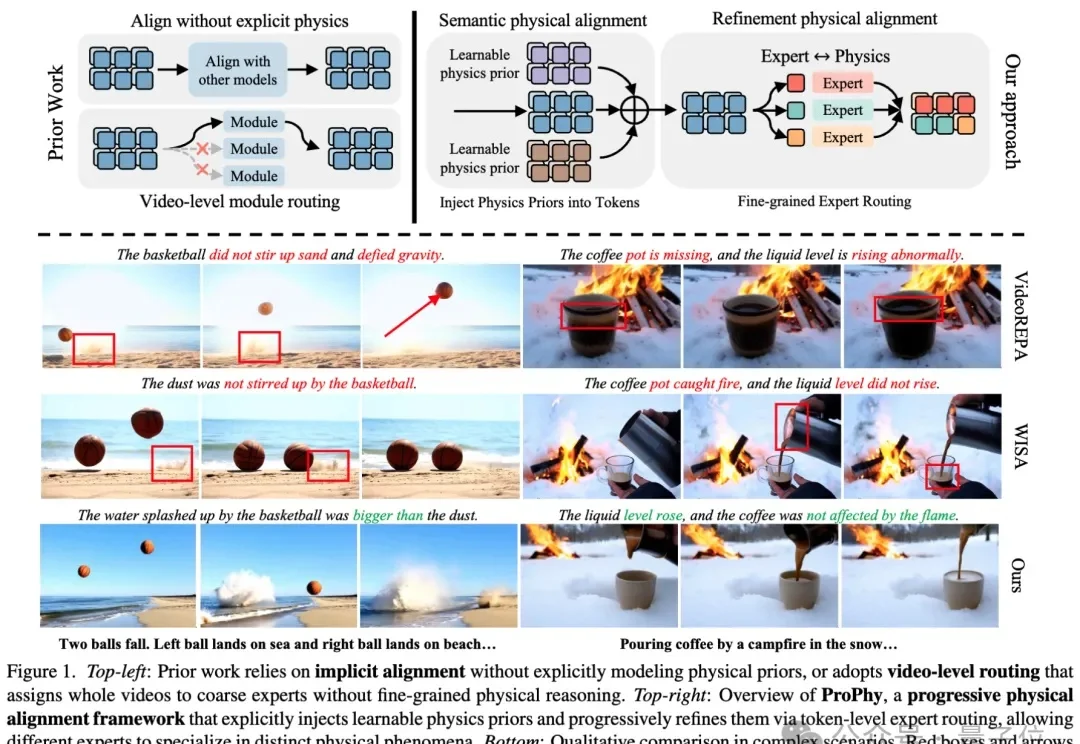
当人们谈到“世界模型”(World Models)时,很多人会首先想到近年来迅速发展的生成式视频模型。
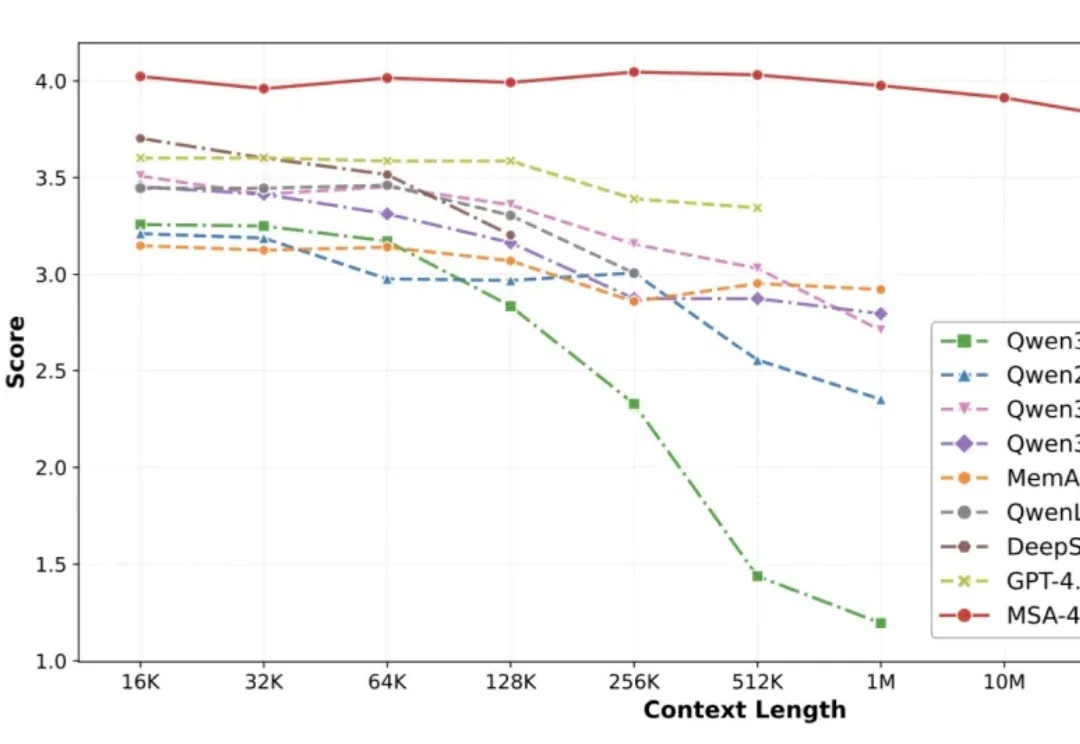
人的智能能力主要由推理能力和长期记忆能力构成。近年来,大模型的推理能力一直处于快速发展过程,但大模型的长期记忆能力一直受限于上下文长度,无法取得突破。在历史上,曾经有多种路线进行尝试,但都无法突破扩展性(Scalability)、精度(Precision)和效率(Efficiency)的不可能三角。

MLRA通过拆分KV缓存为四个并行分支,显著降低显存占用并实现4路张量并行。推理速度比MLA最高快2.8倍,支持百万级上下文,且模型质量更优。无需牺牲性能,即可高效扩展长文本处理能力。
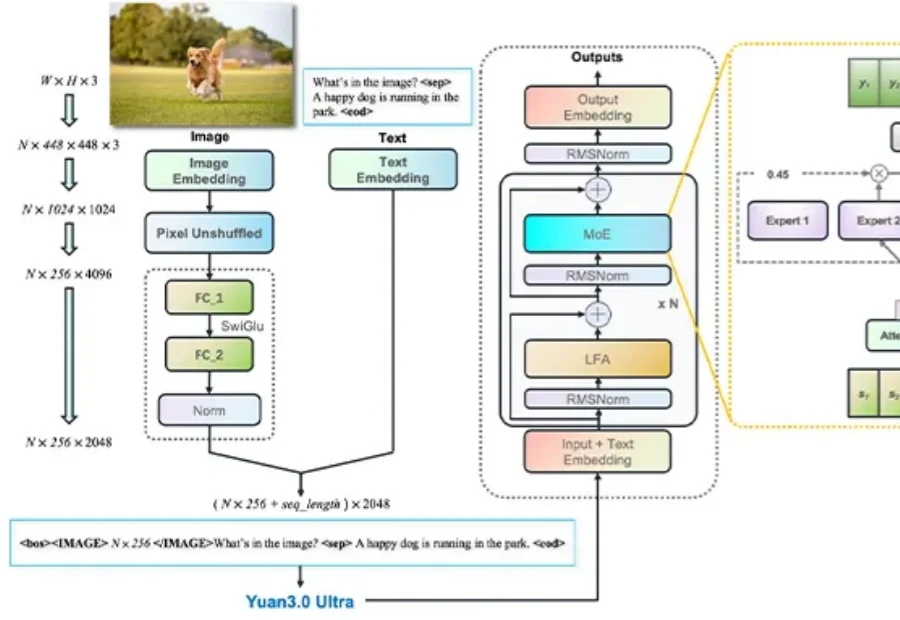
告别Token老虎,给大模型来了个“减脂增肌”。

当全网还在为搞定环境配置和Token账单焦头烂额时,有人直接掀了桌子,把OpenClaw从「工具」变成了「造印钞机」!
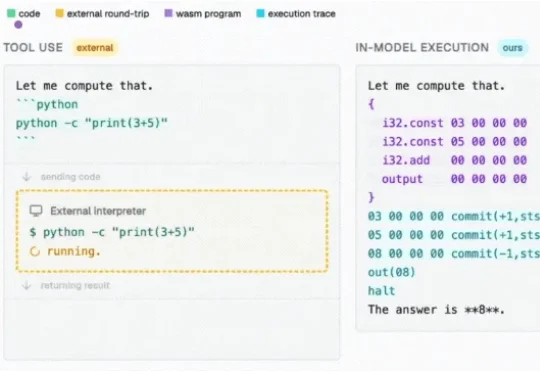
LLM推理已经顶尖,精确计算却跟不上。这局怎么破?卡帕西点赞的解决方法来了,在大模型内部构建一台原生计算机。新方法不搞外包那一套(不依赖任何外部工具),直接在Transformer权重里内嵌可执行程序。

昨晚,阿里巴巴突然宣布成立 Alibaba Token Hub(ATH)事业群,CEO 吴泳铭直接负责,这可能是阿里在 AI 时代最重要的一次组织架构调整。
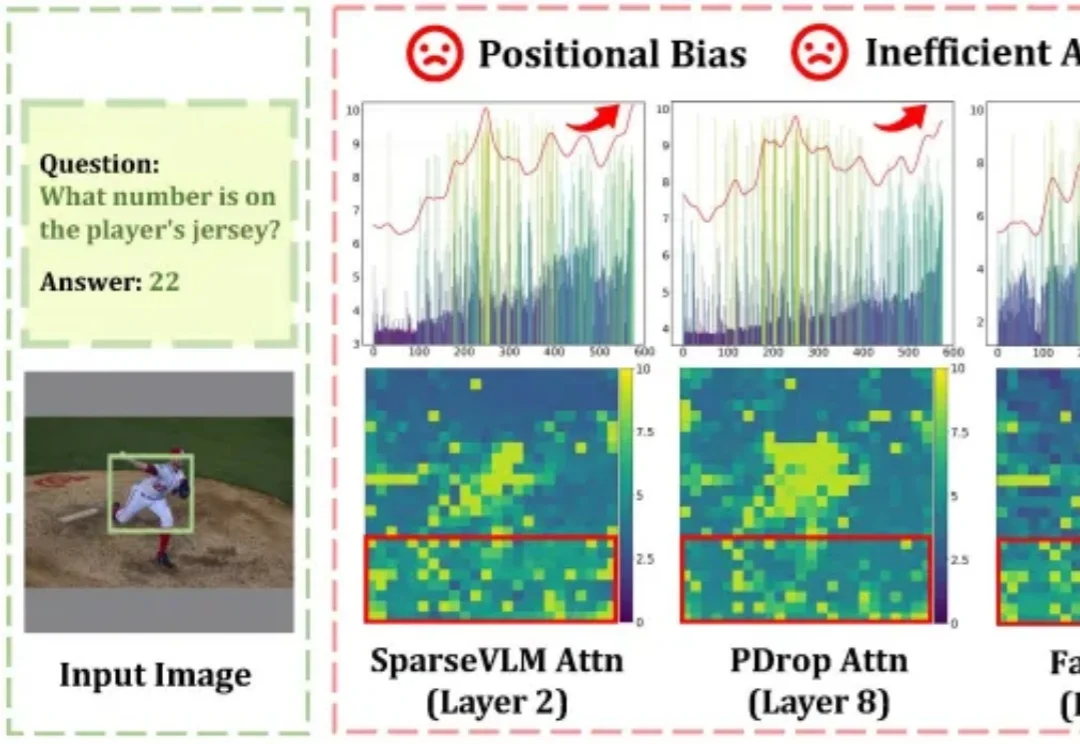
随着高分辨率图像理解与长视频处理需求的爆发式增长,大型视觉语言模型(LVLMs)所需处理的视觉 Token 数量急剧膨胀,推理效率成为落地部署的核心瓶颈。Token 压缩是缩短序列、提升吞吐的直接手段,但现有方法普遍依赖注意力权重来判断 Token 重要性,这一路线暗藏两个致命缺陷: