
性能提升、成本降低,这是分布式强化学习算法最新研究进展
性能提升、成本降低,这是分布式强化学习算法最新研究进展分布式强化学习是一个综合的研究子领域,需要深度强化学习算法以及分布式系统设计的互相感知和协同。考虑到 DDRL 的巨大进步,我们梳理形成了 DDRL 技术的展历程、挑战和机遇的系列文章。
来自主题: AI技术研报
3412 点击 2024-02-13 14:05
 搜索
搜索
分布式强化学习是一个综合的研究子领域,需要深度强化学习算法以及分布式系统设计的互相感知和协同。考虑到 DDRL 的巨大进步,我们梳理形成了 DDRL 技术的展历程、挑战和机遇的系列文章。
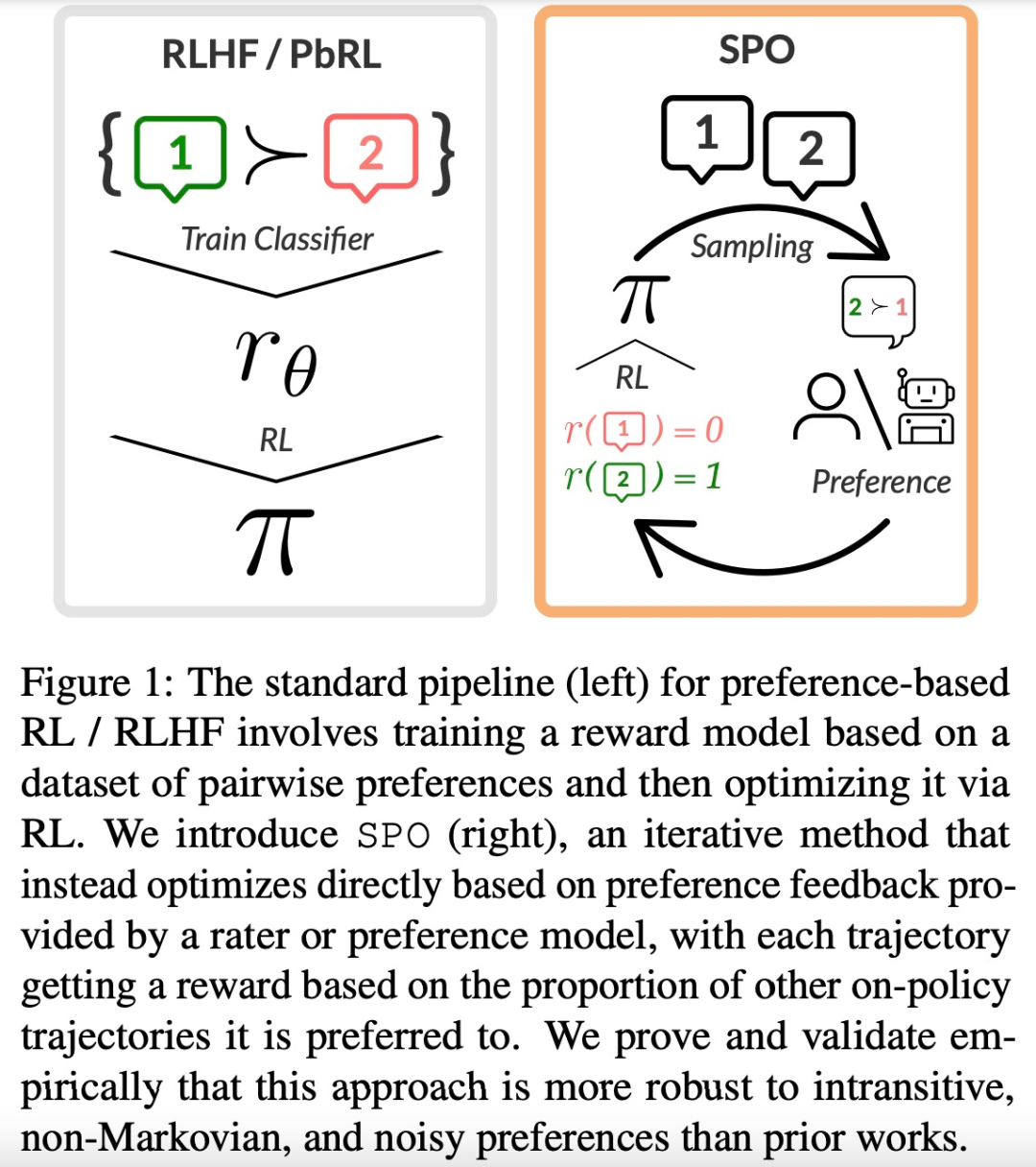
大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。

有的大模型对齐方法包括基于示例的监督微调(SFT)和基于分数反馈的强化学习(RLHF)。然而,分数只能反应当前回复的好坏程度,并不能明确指出模型的不足之处。相较之下,我们人类通常是从语言反馈中学习并调整自己的行为模式。

SPF算法是一种基于状态序列频域预测的表征学习方法,利用状态序列的频域分布来显式提取状态序列数据中的趋势性和规律性信息,从而辅助表征高效地提取到长期未来信息。

OpenAI认为,未来十年来将诞生超过人类的超级AI系统。但是,这会出现一个问题,即基于人类反馈的强化学习技术将终结。

谷歌带着Gemini真的来了,多模态能力震惊全网。下一代模型将融合AlphaGo深度强化学习技术,2024年面世。真正可以叫板GPT-4的模型,当属谷歌Gemini。

大模型的效果好不好,有时候对齐调优很关键。但近来很多研究开始探索无微调的方法,艾伦人工智能研究所和华盛顿大学的研究者用「免调优」对齐新方法超越了使用监督调优(SFT)和人类反馈强化学习(RLHF)的 LLM 性能。

来自清华大学的研究团队提出了一个深度强化学习算法的模型。基于 15 分钟城市概念,该模型可以进行复杂的城市空间规划。

近日,复旦大学附属中山医院内分泌科李小英、陈颖团队联合北京邮电大学王光宇教授团队首次提出采用基于强化学习算法的AI系统“RL-DITR”制定胰岛素决策策略。

谷歌团队的最新研究提出了,用大模型替代人类,进行偏好标注,也就是AI反馈强化学习(RLAIF)。