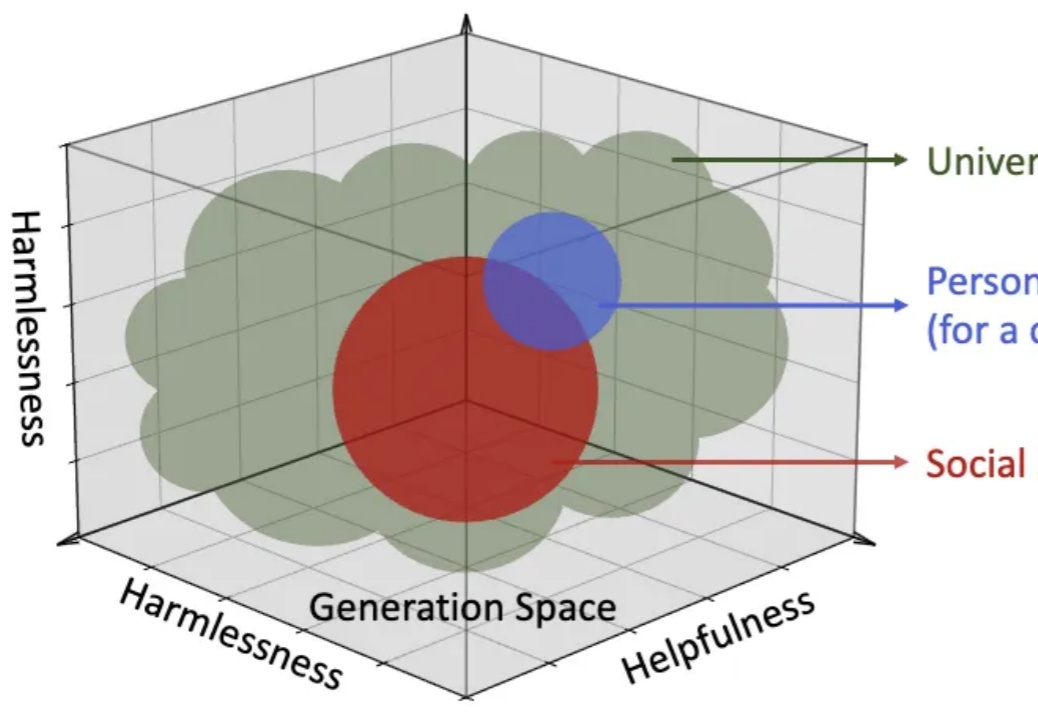
首个个性化对齐大模型问世!可精准识别用户内在动机和偏好,还有百万用户画像开源数据集 | 蚂蚁&人大
首个个性化对齐大模型问世!可精准识别用户内在动机和偏好,还有百万用户画像开源数据集 | 蚂蚁&人大如何让大模型更懂「人」?
来自主题: AI技术研报
7452 点击 2025-04-08 09:07
 搜索
搜索
如何让大模型更懂「人」?

让大语言模型更懂特定领域知识,有新招了!
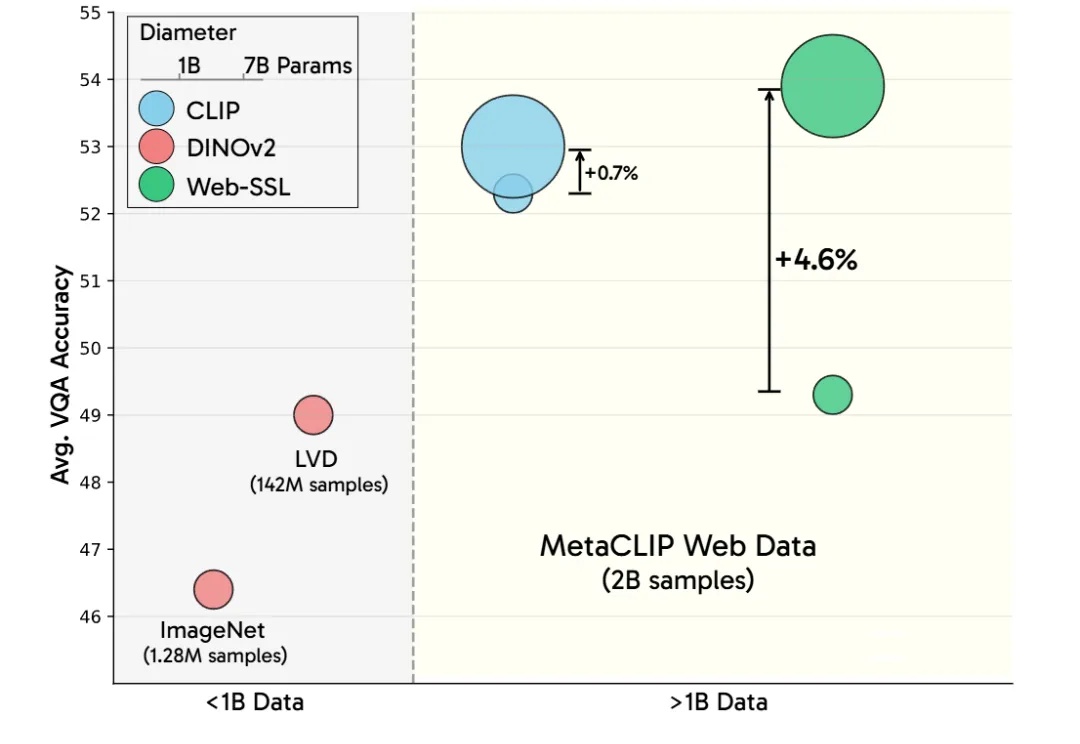
LeCun谢赛宁等研究人员通过新模型Web-SSL验证了SSL在多模态任务中的潜力,证明其在扩展模型和数据规模后,能媲美甚至超越CLIP。这项研究为无语言监督的视觉预训练开辟新方向,并计划开源模型以推动社区探索。

AI爬虫是互联网最顽固的「蟑螂」,不讲规则、压垮网站,令开发者深恶痛绝。面对这种AI时代的「DDoS攻击」,极客们用智慧反击:或设「神之审判」Anubis,或制造数据陷阱,以幽默和代码让机器人自食其果。这场攻防战,正演变成一场精彩绝伦的网络博弈。

不是我说,年轻人群体到底怎么看AI、用AI啊???

在人工智能飞速发展的今天,LLM 的能力令人叹为观止,但其局限性也日益凸显 —— 它们往往被困于训练数据的「孤岛」,无法直接触及实时信息或外部工具。

自2022年11月,美国硅谷初创公司OpenAI推出首款基于大语言模型的现象级聊天机器人ChatGPT以来,AI技术与我们的生活日益紧密。然而,大模型降世两年多,人们却吃惊地发现,自己最终的那个梦想,一个有强大AI为人类工作的社会,一个有更多的闲暇,上四休三甚至每周工作更短时间的世界,却仿佛更遥远了,我们变得更忙了,而且,这个事实居然在数据上得到了确认。

谷歌DeepMind研发的DreamerV3实现重大突破:无需任何人类数据,通过强化学习与「世界模型」,自主完成《我的世界》中极具挑战的钻石收集任务。该成果被视为通往AGI的一大步,并已登上Nature。

当我们遇到新问题时,往往会通过类比过去的经验来寻找解决方案,大语言模型能否如同人类一样类比?在对大模型的众多批判中,人们常说大模型只是记住了训练数据集中的模式,并没有进行真正的推理。
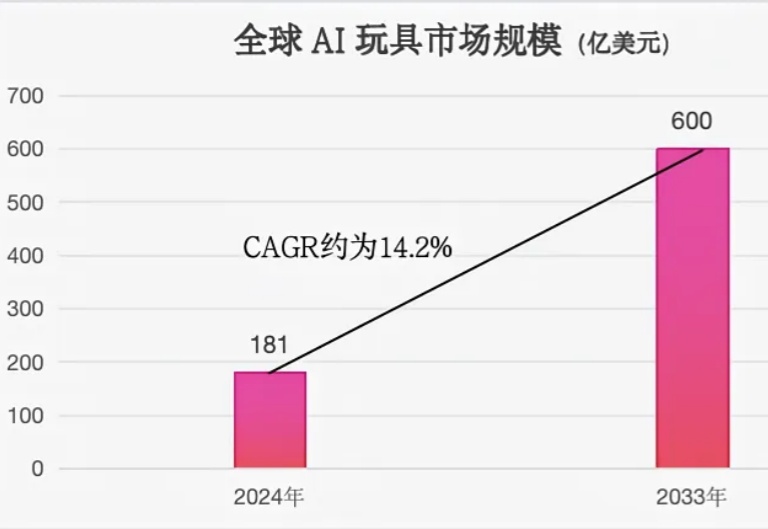
2025 年,DeepSeek 爆火带动传统产品的智能化升级,如传统玩具向 AI 玩具转型。央视新闻调查数据显示,2025 年 1 月,国内某电商平台面向 3-6 岁儿童的 AI 早教玩具销量环比增长 6 倍。咨询公司 IMARC 的预测数据显示,2024 年全球 AI 玩具市场规模已达 181 亿美元,预计到 2033 年将增长至 600 亿美元。