比Stable Diffusion便宜118倍!1890美元训出11.6亿参数高质量文生图模型
比Stable Diffusion便宜118倍!1890美元训出11.6亿参数高质量文生图模型近日,来自加州大学尔湾分校等机构的研究人员,利用延迟掩蔽、MoE、分层扩展等策略,将扩散模型的训练成本降到了1890美元。
来自主题: AI资讯
9124 点击 2024-08-12 17:11
 搜索
搜索
近日,来自加州大学尔湾分校等机构的研究人员,利用延迟掩蔽、MoE、分层扩展等策略,将扩散模型的训练成本降到了1890美元。
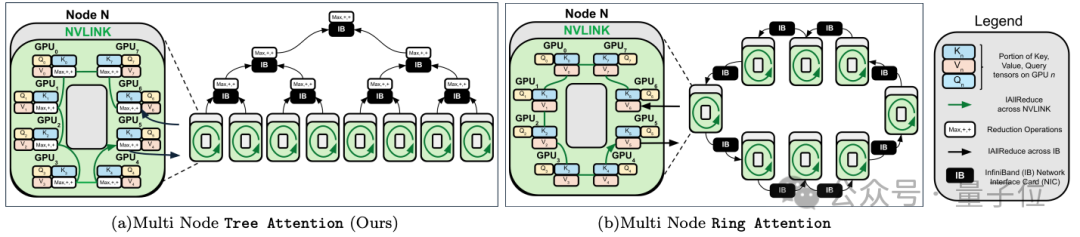
跨GPU的注意力并行,最高提速8倍,支持512万序列长度推理。
在新一轮互联网创新历程中,大模型有幸成了下一个赛点,这次不再像之前的元宇宙一样稍纵即逝,而是真的在逐渐往应用层面渗透。

卓世科技」CEO屠静女士表示:“通过本轮融资,卓世科技将进一步加大在人工智能领域的研发投入,推动行业大模型的商业化进程。“

Figure的机器人大脑此前也使用了ViLa模型,这是「千寻智能」联合创始人高阳所提出。

2017 年,谷歌在论文《Attention is all you need》中提出了 Transformer,成为了深度学习领域的重大突破。该论文的引用数已经将近 13 万,后来的 GPT 家族所有模型也都是基于 Transformer 架构,可见其影响之广。 作为一种神经网络架构,Transformer 在从文本到视觉的多样任务中广受欢迎,尤其是在当前火热的 AI 聊天机器人领域。
只需30秒,AI就能像3D建模师一样,在各种指示下生成高质量人造Mesh。
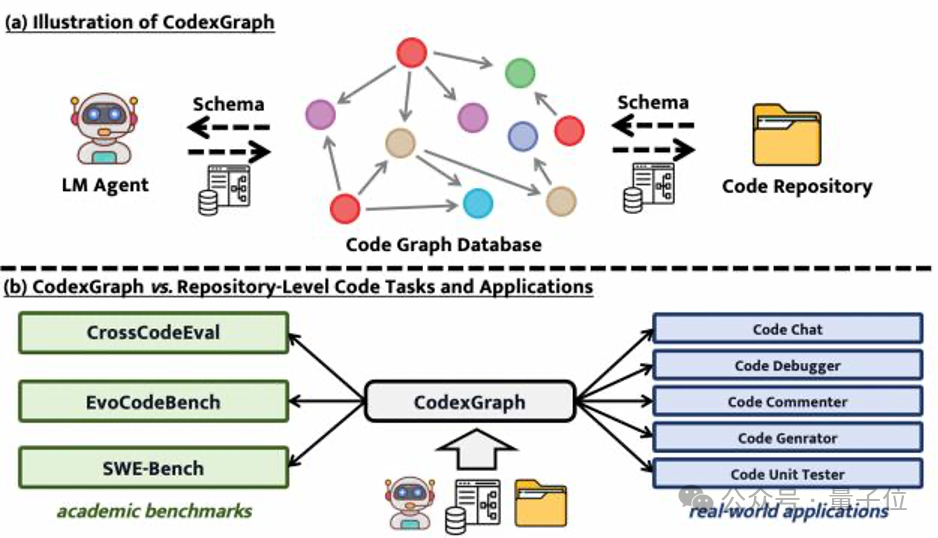
代码生成和补全任务做不完了?!
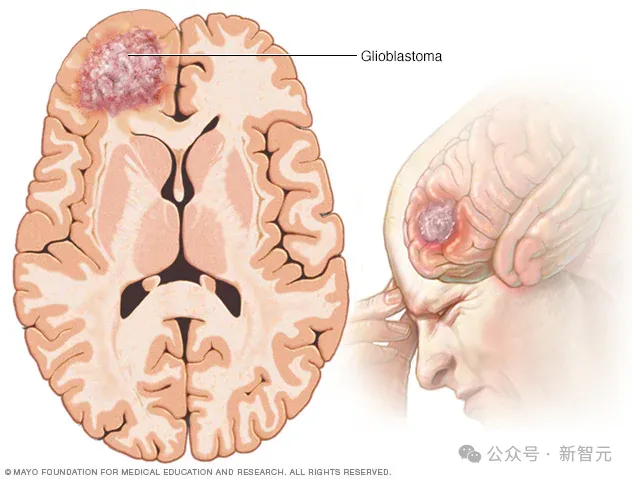
南加州大学凯克医学院利用AI技术将脑癌细胞转化为免疫细胞,在胶质母细胞瘤小鼠模型中将生存机会提高了75%。

把Llama 3.1 405B和Claude 3超大杯Opus双双送进小黑屋,你猜怎么着——