
Post-Training有多重要?AI2研究员长文详解前沿模型的后训练秘籍
Post-Training有多重要?AI2研究员长文详解前沿模型的后训练秘籍越来越多研究发现,后训练对模型性能同样重要。Allen AI的机器学习研究员Nathan Lambert最近发表了一篇技术博文,总结了科技巨头们所使用的模型后训练配方。
来自主题: AI技术研报
12469 点击 2024-08-19 14:47
 搜索
搜索
越来越多研究发现,后训练对模型性能同样重要。Allen AI的机器学习研究员Nathan Lambert最近发表了一篇技术博文,总结了科技巨头们所使用的模型后训练配方。
Mamba 虽好,但发展尚早。

研究发现:大模型尚无法独立学习或获得新技能。

单目深度估计新成果来了!
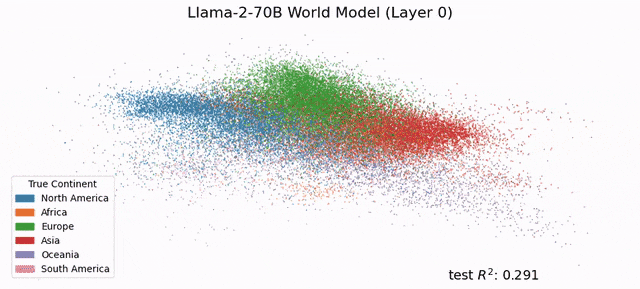
MIT CSAIL的研究人员发现,LLM的「内心深处」已经发展出了对现实的模拟,模型对语言和世界的理解,绝不仅仅是简单的「鹦鹉学舌」。也就说,在未来,LLM会比今天更深层地理解语言。

让模型具有更加广泛和通用的认知能力,是当前人工智能(AI)领域发展的重要目标。目前流行的大模型路径是基于 Scaling Law (尺度定律) 去构建更大、更深和更宽的神经网络提升模型的表现,可称之为 “基于外生复杂性” 的通用智能实现方法。然而,这一路径也面临着一些难以克服的困境,例如高昂的计算资源消耗和能源消耗,并且在可解释性方面存在不足。

互相检查,让小模型也能解决大问题。
大模型的安全性,可以说是「有很大进步空间」。

越来越多人开始关注大模型,很多做工程开发的同学问我怎么入门大模型训练推理系统软件(俗称大模型Infra)。

发布40天后,最强开源模型Llama 3.1 405B等来了微调版本的发布。但不是来自Meta,而是一个专注于开放模型的神秘初创Nous Research。