
英伟达下场,首次优化DeepSeek-R1!B200性能狂飙25倍,碾压H100
英伟达下场,首次优化DeepSeek-R1!B200性能狂飙25倍,碾压H100最近,英伟达开源了首个在Blackwell架构上优化的DeepSeek-R1,实现了推理速度提升25倍,和每token成本降低20倍的惊人成果。同时,DeepSeek连续开源多个英伟达GPU优化项目,共同探索模型性能极限。
来自主题: AI技术研报
11898 点击 2025-02-27 16:33
 搜索
搜索
最近,英伟达开源了首个在Blackwell架构上优化的DeepSeek-R1,实现了推理速度提升25倍,和每token成本降低20倍的惊人成果。同时,DeepSeek连续开源多个英伟达GPU优化项目,共同探索模型性能极限。
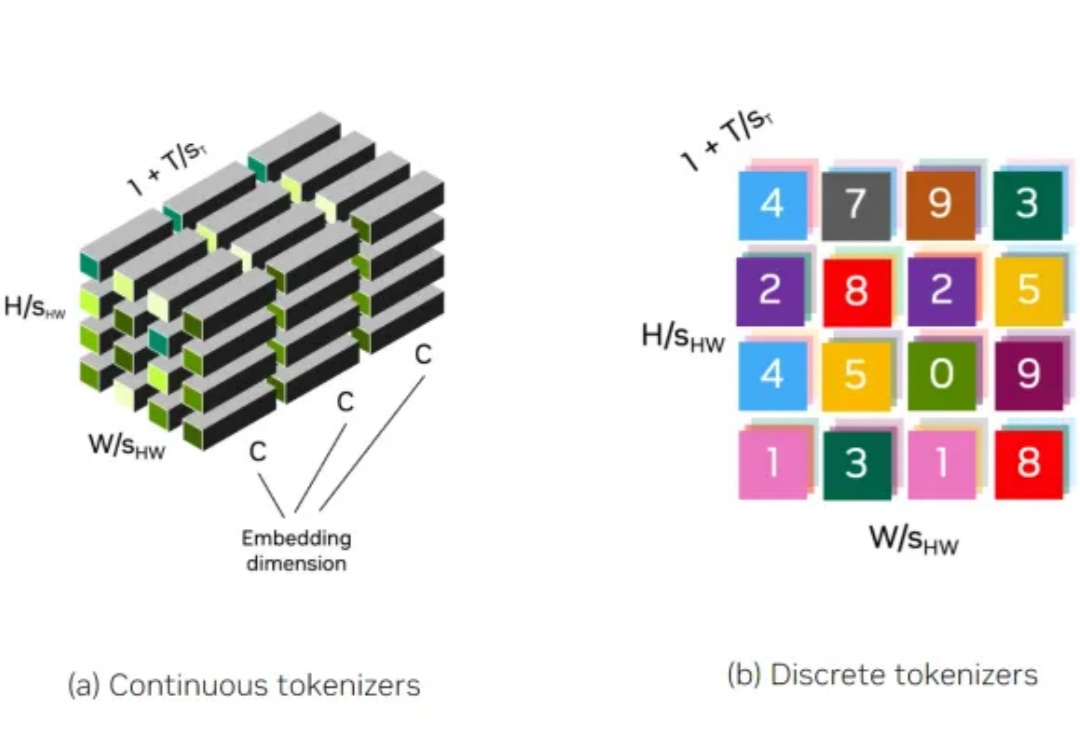
tokenizer对于图像、视频生成的重要性值得重视。

文本到图像的生成模型让创作更加灵活,用户可以用自然语言引导生成图像。
英伟达不仅要做显卡领域的领先者,还要在大模型领域逐渐建立起自己的优势。
英伟达开源了超强模型Nemotron-70B,后者一经发布就超越了GPT-4o和Claude 3.5 Sonnet,仅次于OpenAI o1!AI社区惊呼:新的开源王者又来了?业内直呼:用Llama 3.1训出小模型吊打GPT-4o,简直是神来之笔!

NVLM 1.0系列多模态大型语言模型在视觉语言任务上达到了与GPT-4o和其他开源模型相媲美的水平,其在纯文本性能甚至超过了LLM骨干模型,特别是在文本数学和编码基准测试中,平均准确率提高了4.3个百分点。
小模型,正在成为 AI 巨头的新战场。

刚刚,英伟达全新发布的开源模型Nemotron-4 340B,有可能彻底改变训练LLM的方式!从此,或许各行各业都不再需要昂贵的真实世界数据集了。而且,Nemotron-4 340B直接超越了Mixtral 8x22B、Claude sonnet、Llama3 70B、Qwen 2,甚至可以和GPT-4掰手腕!
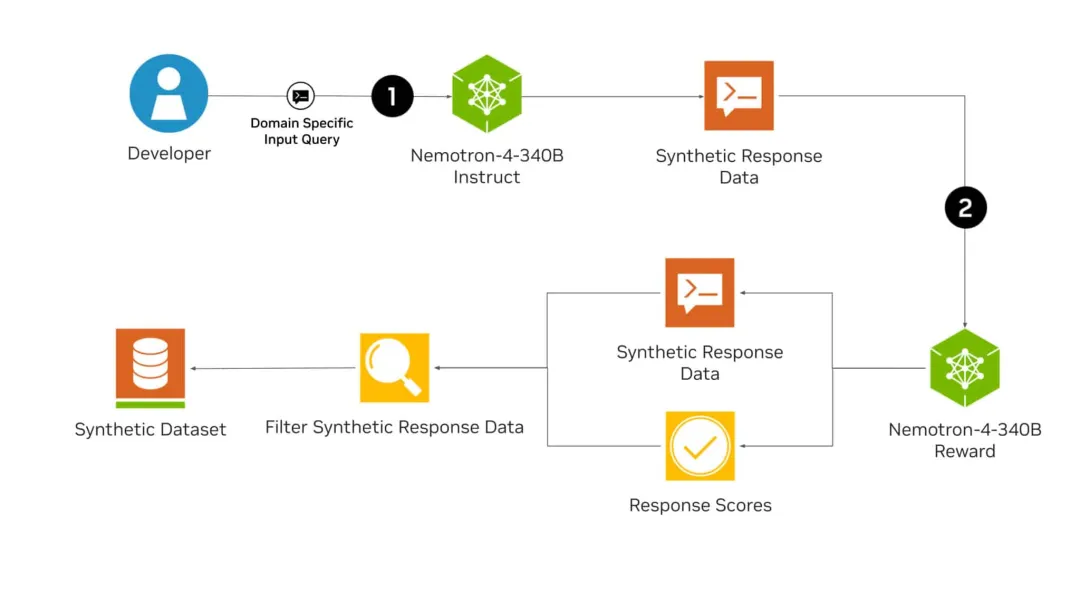
性能超越 Llama-3,主要用于合成数据。

FoundationPose模型使用RGBD图像对新颖物体进行姿态估计和跟踪,支持基于模型和无模型设置,在多个公共数据集上大幅优于针对每个任务专门化的现有方法.