换了30多种方言,我们竟然没能考倒中国电信的语音大模型
换了30多种方言,我们竟然没能考倒中国电信的语音大模型不管你来自哪个城市,相信在你的记忆中,都有自己的「家乡话」:吴语柔软细腻、关中方言质朴厚重、四川方言幽默诙谐、粤语古雅潇洒…… 某种意义上说,方言不只是一种语言习惯,也是一种情感连接、一种文化认同。我们「上网冲浪」遇到的新鲜词汇中,有不少就是来自各地方言。当然,有些时候,方言也是一种交流「壁垒」。
来自主题: AI资讯
9852 点击 2024-05-27 16:10
 搜索
搜索
不管你来自哪个城市,相信在你的记忆中,都有自己的「家乡话」:吴语柔软细腻、关中方言质朴厚重、四川方言幽默诙谐、粤语古雅潇洒…… 某种意义上说,方言不只是一种语言习惯,也是一种情感连接、一种文化认同。我们「上网冲浪」遇到的新鲜词汇中,有不少就是来自各地方言。当然,有些时候,方言也是一种交流「壁垒」。

最近,许久没有新动向的马斯克放出了大消息——他旗下的人工智能初创公司xAI将投入巨资建造一个超算中心,以保证Grok 2及之后版本的训练。这个「超级计算工厂」预计于2025年秋季建成,规模将达到目前最大GPU集群的四倍。

GPT-4在为人类选股时,表现竟然超越了大部分人类分析师,和针对金融训练的专业模型?在没有任何上下文的情况下,它们直接就成功分析了财务报表,这一发现让许多业内大咖震惊了。然而好景不长,有AI大牛指出研究中的bug:之所以会这样,很可能是训练数据被污染了。

本文介绍了香港科技大学(广州)的一篇关于大模型高效微调(LLM PEFT Fine-tuning)的文章「Parameter-Efficient Fine-Tuning with Discrete Fourier Transform」

为了将大型语言模型(LLM)与人类的价值和意图对齐,学习人类反馈至关重要,这能确保它们是有用的、诚实的和无害的。在对齐 LLM 方面,一种有效的方法是根据人类反馈的强化学习(RLHF)。尽管经典 RLHF 方法的结果很出色,但其多阶段的过程依然带来了一些优化难题,其中涉及到训练一个奖励模型,然后优化一个策略模型来最大化该奖励。

Alexandr Wang创办的Scale AI是一个为AI模型提供训练数据的数据标注平台,近期完成新一轮10亿美元融资,估值飙升至138亿美元。该公司表示将利用新资金生产丰富的前沿数据,为通向AGI铺平道路。

国产大模型最新进展,这次来自“国家队”! 刚刚,全栈国产化生态大模型“九天智能基座”正式发布! 它由中国移动自研。包括万卡算力、千亿模型及百汇平台三部分。 其中模型部分是九天自主研发的从算子到框架全栈国产训练的千亿参数大模型,能力达到GPT-4的90%水平。

第一个以「泛化」能力为核心设计原则的可学习图像匹配器来了!
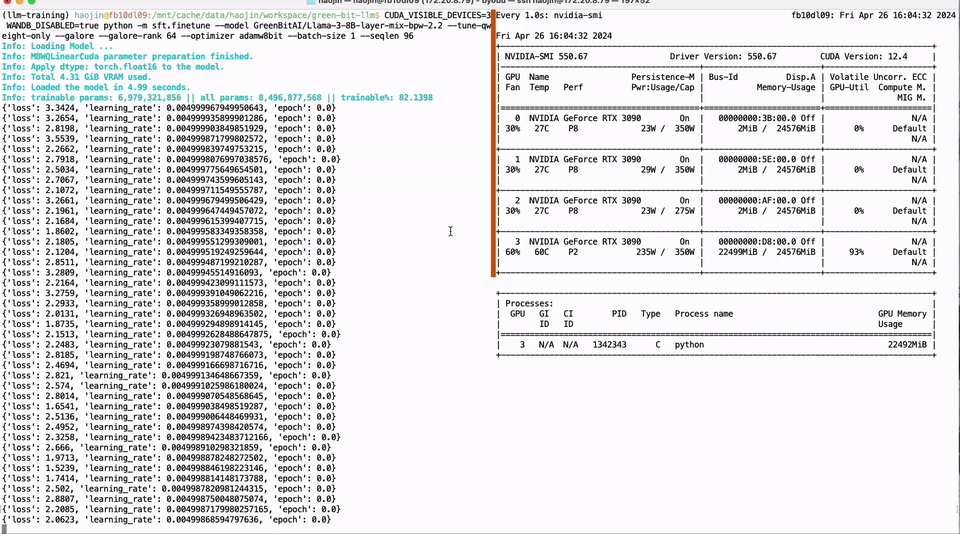
本文由GreenBit.AI团队撰写,团队的核心成员来自德国哈索·普拉特纳计算机系统工程院开源技术小组。我们致力于推动开源社区的发展,倡导可持续的机器学习理念。我们的目标是通过提供更具成本效益的解决方案,使人工智能技术在环境和社会层面产生积极影响。

既能像 Transformer 一样并行训练,推理时内存需求又不随 token 数线性递增,长上下文又有新思路了?