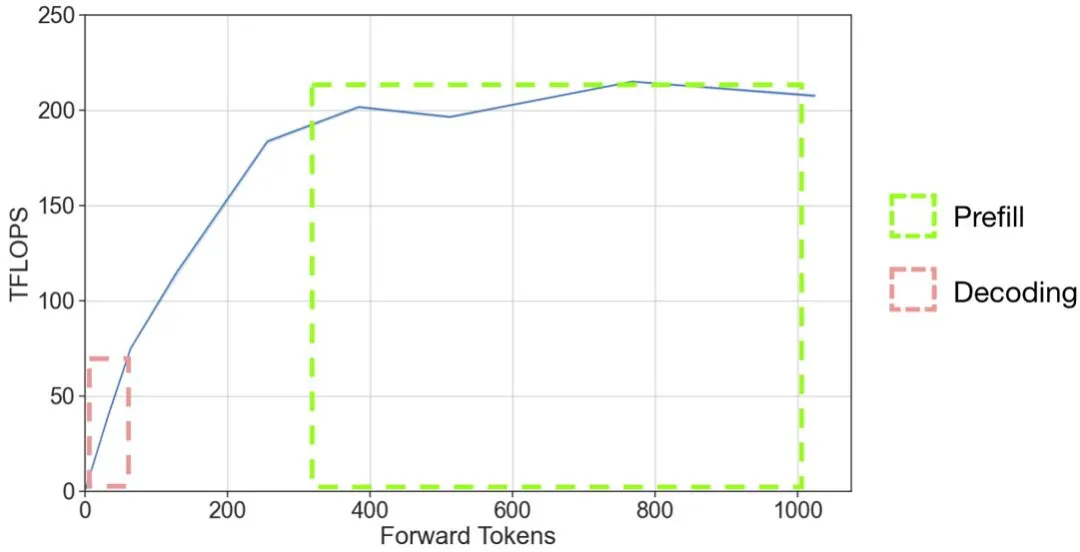
腾讯PCG自研高性能大语言模型推理引擎「一念LLM」正式开源
腾讯PCG自研高性能大语言模型推理引擎「一念LLM」正式开源以 OpenAI 的 GPT 系列模型为代表的大语言模型(LLM)掀起了新一轮 AI 应用浪潮,但是 LLM 推理的高昂成本一直困扰着业务团队。
来自主题: AI技术研报
11260 点击 2024-05-24 20:58
 搜索
搜索
以 OpenAI 的 GPT 系列模型为代表的大语言模型(LLM)掀起了新一轮 AI 应用浪潮,但是 LLM 推理的高昂成本一直困扰着业务团队。

在 AI 领域,扩展定律(Scaling laws)是理解 LM 扩展趋势的强大工具,其为广大研究者提供了一个准则,该定律在理解语言模型的性能如何随规模变化提供了一个重要指导。
这才是 AI 视频生成的未来?

在多标签图像识别领域中,由于图像本身和潜在标签类别的复杂性,收集满足现有模型训练的多标签标注信息往往成本高昂且难以拓展。中山大学联合广东工业大学联手探索标注受限情况下的多标签图像识别任务,通过对多标签图像中的强语义相关性的探索研究,提出了一种异构语义转移(Heterogeneous Semantic Transfer, HST) 框架,实现了有效的未知标签生成。

在图像生成领域占据主导地位的扩散模型,开始挑战强化学习智能体。

4年前的开源项目突然在Hacker News爆火,通过可视化的「小球下山」,帮助非专业和专业人士,更好地理解AI训练中梯度下降的过程。
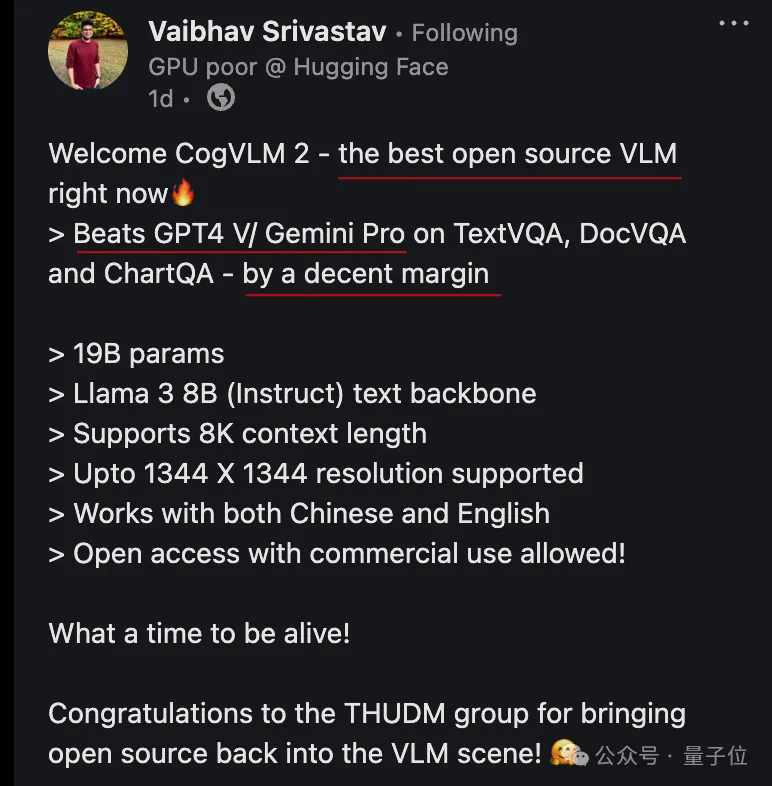
开源多模态SOTA模型再易主!Hugging Face开发者大使刚刚把王冠交给了CogVLM2,来自大模型创业公司智谱AI。CogVLM2甚至在3项基准测试上超过GPT-4v和Gemini Pro,还不是超过一点,是大幅领先。
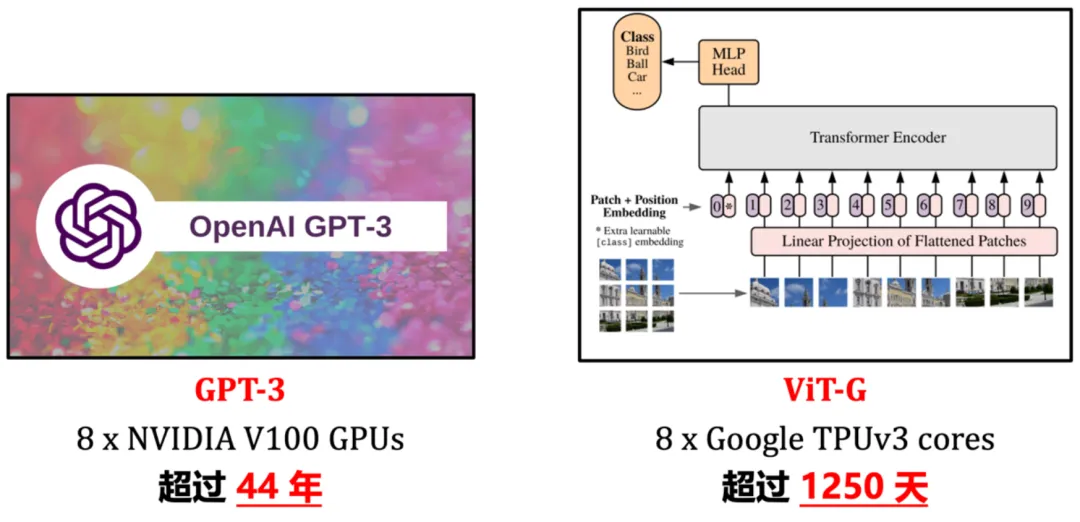
近年来,「scaling」是计算机视觉研究的主角之一。随着模型尺寸和训练数据规模的增大、学习算法的进步以及正则化和数据增强等技术的广泛应用,通过大规模训练得到的视觉基础网络(如 ImageNet1K/22K 上训得的 Vision Transformer、MAE、DINOv2 等)已在视觉识别、目标检测、语义分割等诸多重要视觉任务上取得了令人惊艳的性能。

近日,西交微软北大联合提出信息密集型训练大法,使用纯数据驱动的方式,矫正LLM训练过程产生的偏见,在一定程度上治疗了大语言模型丢失中间信息的问题。

近日,又一惊人结论登上Hacker News热榜:没有指数级数据,就没有Zero-shot!多模态模型被扒实际上没有什么泛化能力,生成式AI的未来面临严峻挑战。