
NeurIPS 2024 | 水印与高效推理如何两全其美?最新理论:这做不到
NeurIPS 2024 | 水印与高效推理如何两全其美?最新理论:这做不到近日,DeepMind 团队将水印技术和投机采样(speculative sampling)结合,在为大语言模型加入水印的同时,提升其推理效率,降低推理成本,因此适合用于大规模生产环境。
来自主题: AI技术研报
7897 点击 2024-11-22 10:14
近日,DeepMind 团队将水印技术和投机采样(speculative sampling)结合,在为大语言模型加入水印的同时,提升其推理效率,降低推理成本,因此适合用于大规模生产环境。
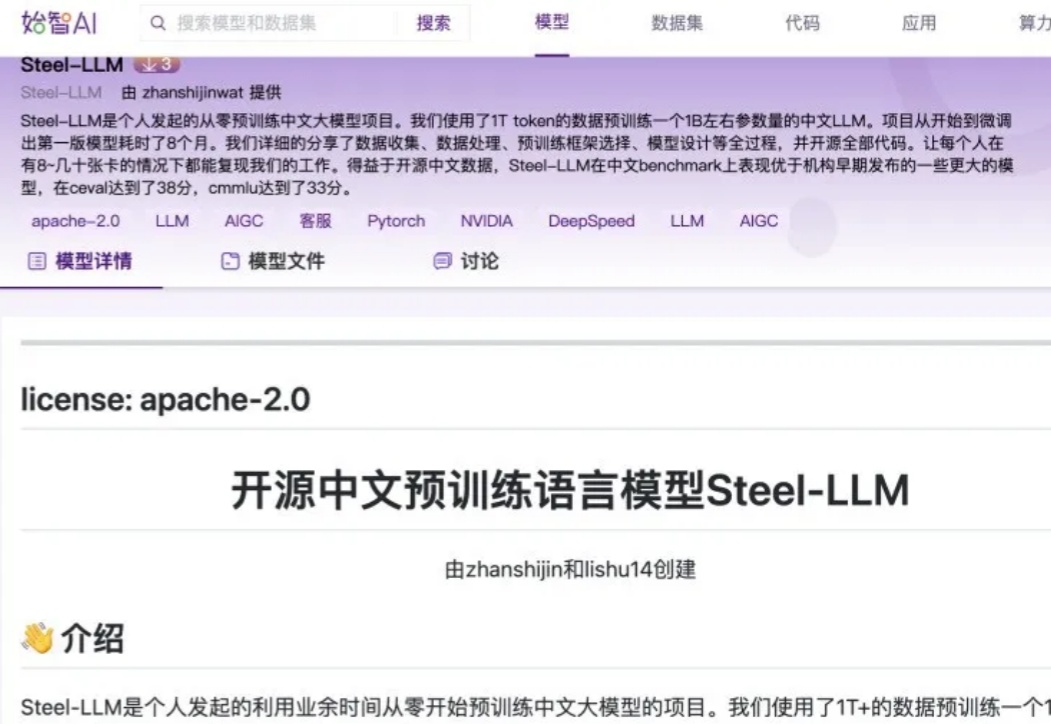
随着开源数据的日益丰富以及算力价格的持续下降,对于个人或小型机构而言,预训练一个小型的 LLM 已逐渐成为可能。开源中文预训练语言模型 Steel - LLM 就是一个典型案例,其模型参数量与数据量并非十分庞大,基本处于参数量为 B 级别、数据量为 T 级别的规模。
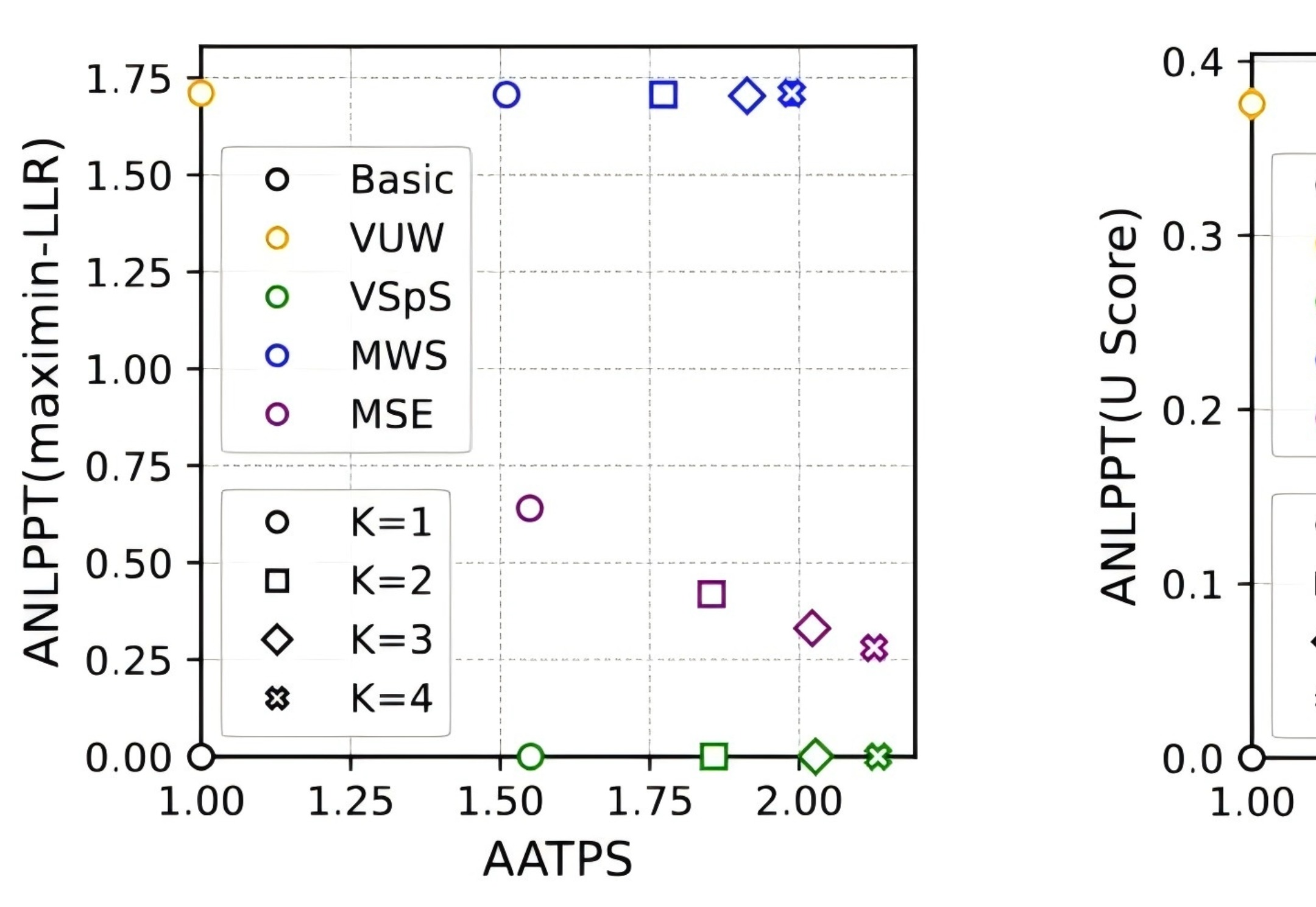
新的大语言模型(LLM)评估基准对于跟上大语言模型的快速发展至关重要。
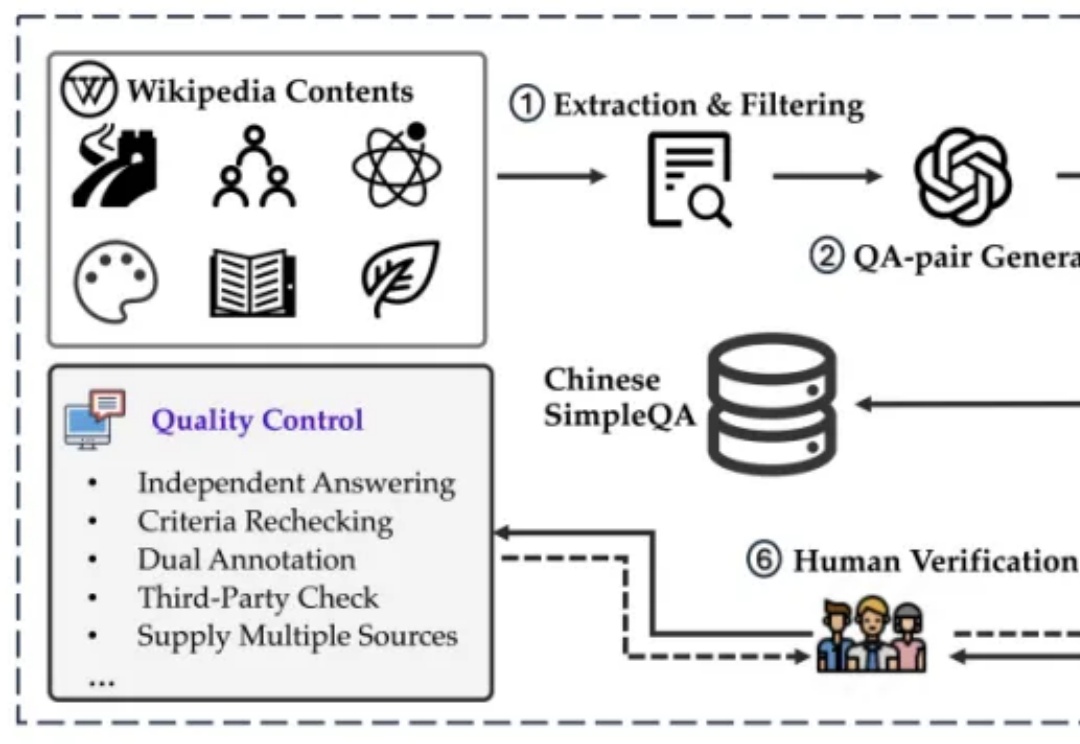
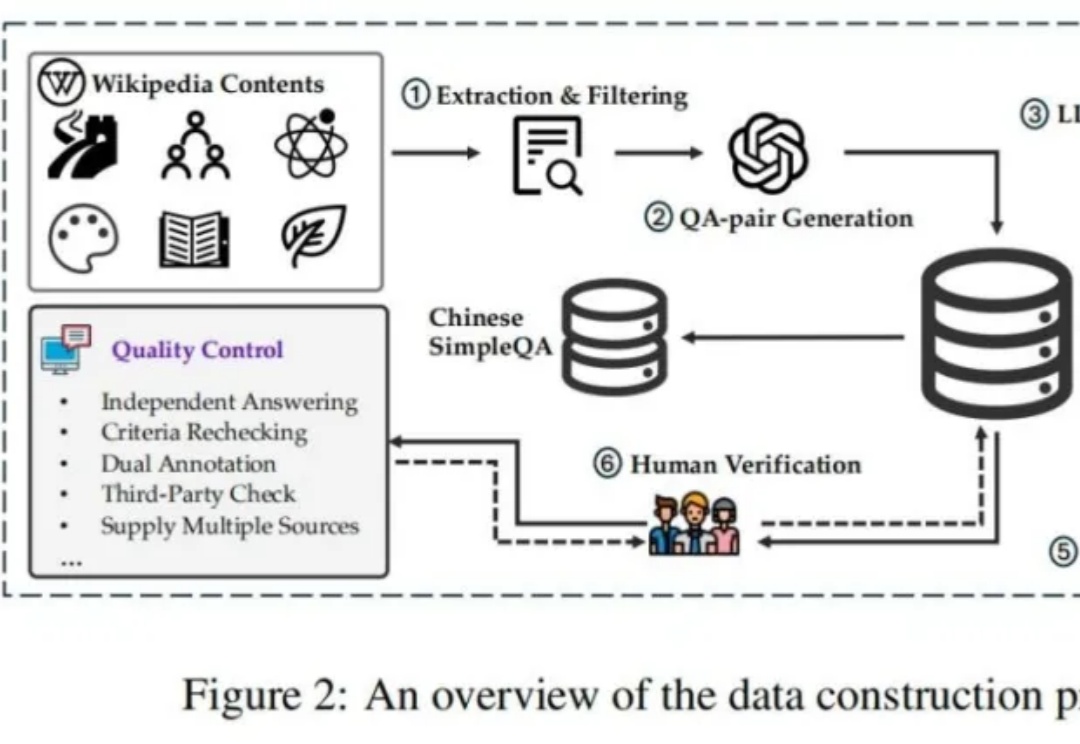
如何解决模型生成幻觉一直是人工智能(AI)领域的一个悬而未解的问题。为了测量语言模型的事实正确性,近期 OpenAI 发布并开源了一个名为 SimpleQA 的评测集。而我们也同样一直在关注模型事实正确性这一领域,目前该领域存在数据过时、评测不准和覆盖不全等问题。例如现在大家广泛使用的知识评测集还是 CommonSenseQA、CMMLU 和 C-Eval 等选择题形式的评测集。

近年来,代码语言模型(Language Models for Code,简称 CodeLMs)逐渐成为推动智能化软件开发的关键技术,应用场景涵盖智能代码生成与补全、漏洞检测与修复等。
耽误业界好多年?

自我纠错(Self Correction)能力,传统上被视为人类特有的特征,正越来越多地在人工智能领域,尤其是大型语言模型(LLMs)中得到广泛应用,最近爆火的OpenAI o1模型[1]和Reflection 70B模型[2]都采取了自我纠正的方法。
受 ChatGPT 强大问答能力的影响,大型语言模型(LLM)提供商往往优化模型来回答人们的问题,以提供良好的消费者体验。
大规模语言模型(LLMs)已经在自然语言处理任务中展现了卓越的能力,但它们在复杂推理任务上依旧面临挑战。推理任务通常需要模型具有跨越多个步骤的推理能力,这超出了LLMs在传统训练阶段的表现。

Recraft团队通过结合TextDiffuser-2技术和自训练的大型语言模型,提升了文本到图像渲染的质量和准确性,不过现有模型在处理复杂语言如中文和未明确指定的文本时,仍存在渲染不准确的问题。