4K分辨率视觉预训练首次实现!伯克利&英伟达多模态新SOTA,更准且3倍加速处理
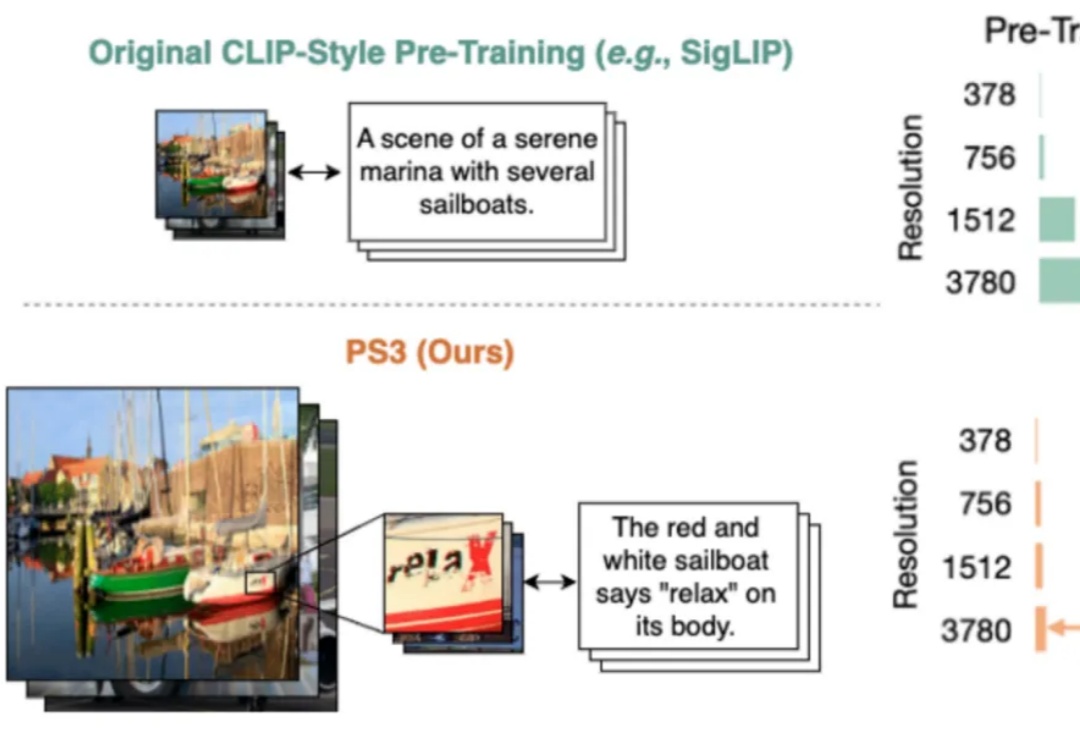
4K分辨率视觉预训练首次实现!伯克利&英伟达多模态新SOTA,更准且3倍加速处理当前,所有主流的视觉基础模型(如 SigLIP、DINOv2 等)都仍然在低分辨率(如 384 * 384 分辨率)下进行预训练。对比人类视觉系统可以轻松达到 10K 等效分辨率,这种低分辨率预训练极大地限制了视觉模型对于高清细节的理解能力。
来自主题: AI技术研报
7880 点击 2025-04-17 13:54
 搜索
搜索
当前,所有主流的视觉基础模型(如 SigLIP、DINOv2 等)都仍然在低分辨率(如 384 * 384 分辨率)下进行预训练。对比人类视觉系统可以轻松达到 10K 等效分辨率,这种低分辨率预训练极大地限制了视觉模型对于高清细节的理解能力。

作为一家公司,我们专注于三件事:预训练、微调和对齐。我们使用自有数据集进行预训练,这一点非常关键,而很多公司并不具备这样的能力。然后,我们用专家手工整理的数据进行微调。最有趣、最重要的部分在于对齐,这与简单地寻找“当前最优解”是截然不同的。
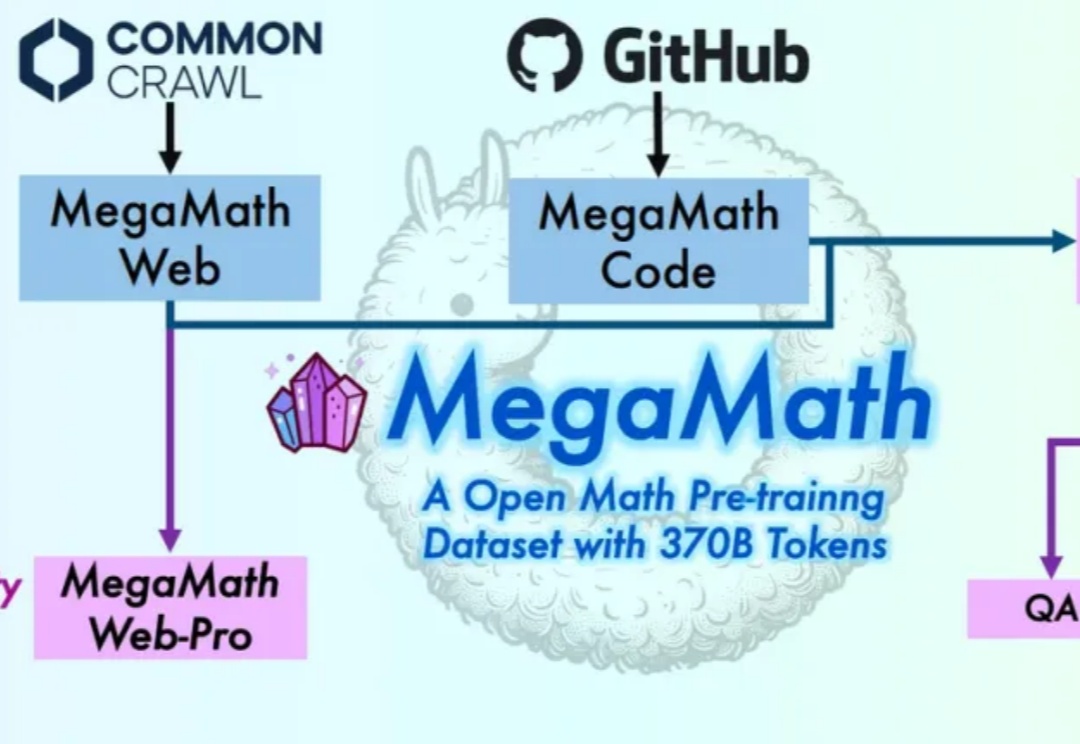
在大模型迈向推理时代的当下,数学推理能力已成为衡量语言模型智能上限的关键指标。
高质量数据枯竭,传统预训练走向终点,大模型如何突破瓶颈?

港中文、清华等高校提出SICOG框架,通过预训练、推理优化和后训练协同,引入自生成数据闭环和结构化感知推理机制,实现模型自我进化,为大模型发展提供新思路。
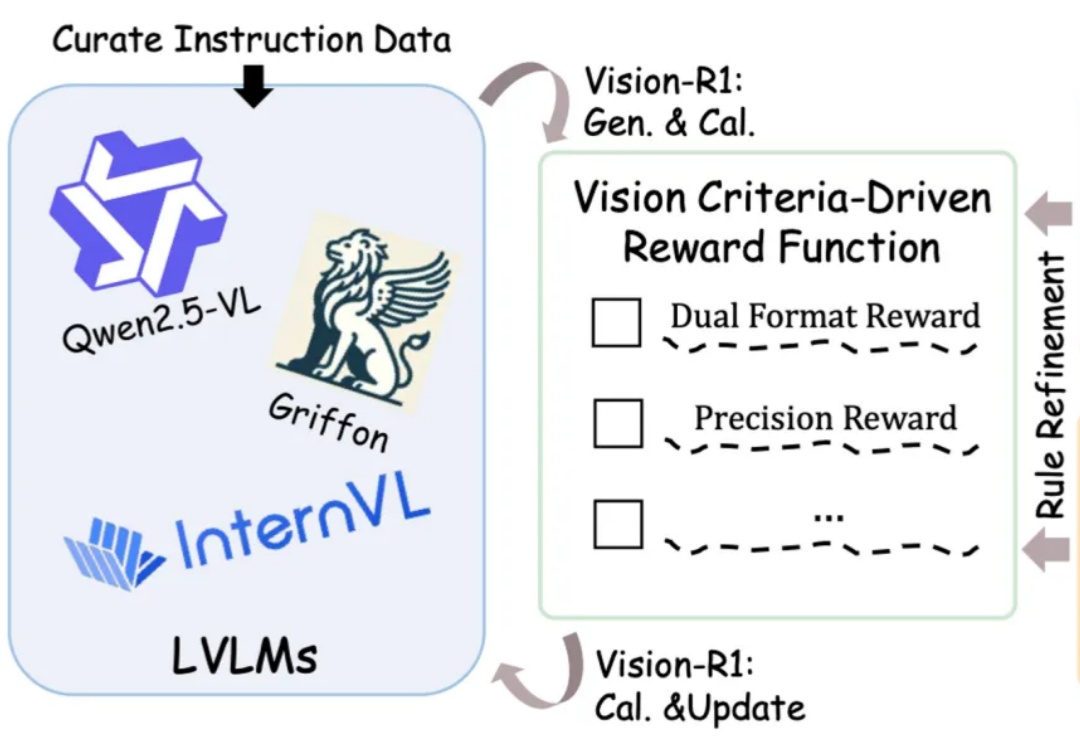
图文大模型通常采用「预训练 + 监督微调」的两阶段范式进行训练,以强化其指令跟随能力。受语言领域的启发,多模态偏好优化技术凭借其在数据效率和性能增益方面的优势,被广泛用于对齐人类偏好。目前,该技术主要依赖高质量的偏好数据标注和精准的奖励模型训练来提升模型表现。然而,这一方法不仅资源消耗巨大,训练过程仍然极具挑战。
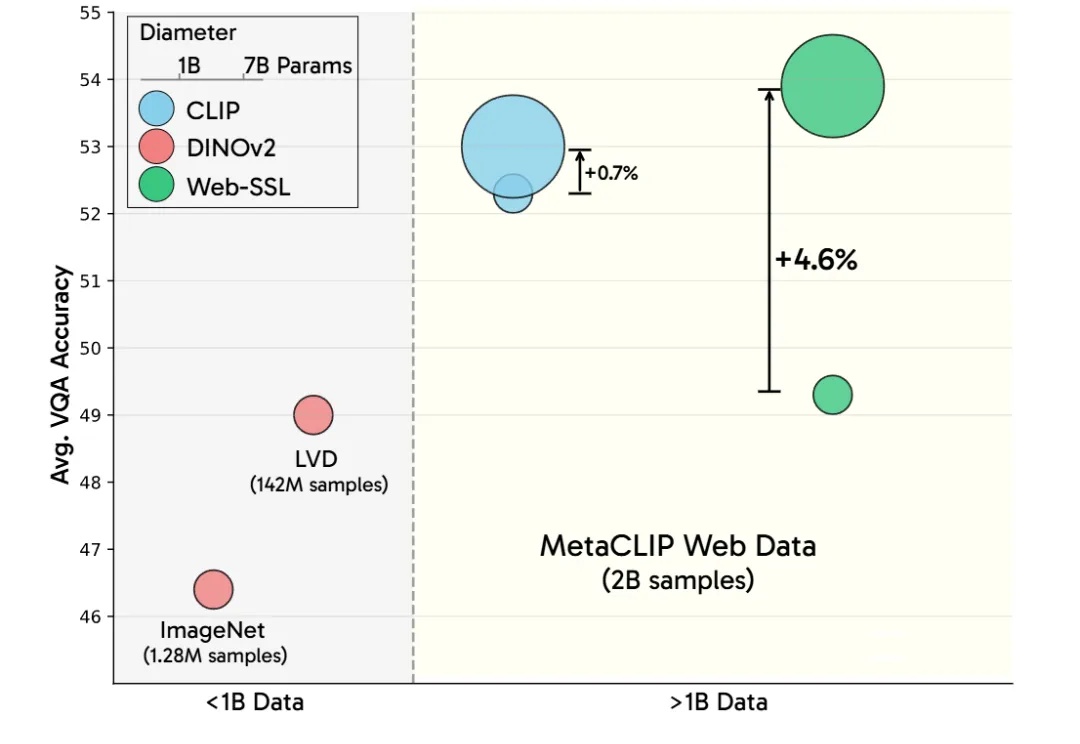
LeCun谢赛宁等研究人员通过新模型Web-SSL验证了SSL在多模态任务中的潜力,证明其在扩展模型和数据规模后,能媲美甚至超越CLIP。这项研究为无语言监督的视觉预训练开辟新方向,并计划开源模型以推动社区探索。

作为一家公司,我们专注于三件事:预训练、微调和对齐。我们使用自有数据集进行预训练,这一点非常关键,而很多公司并不具备这样的能力。然后,我们用专家手工整理的数据进行微调。最有趣、最重要的部分在于对齐,这与简单地寻找“当前最优解”是截然不同的。
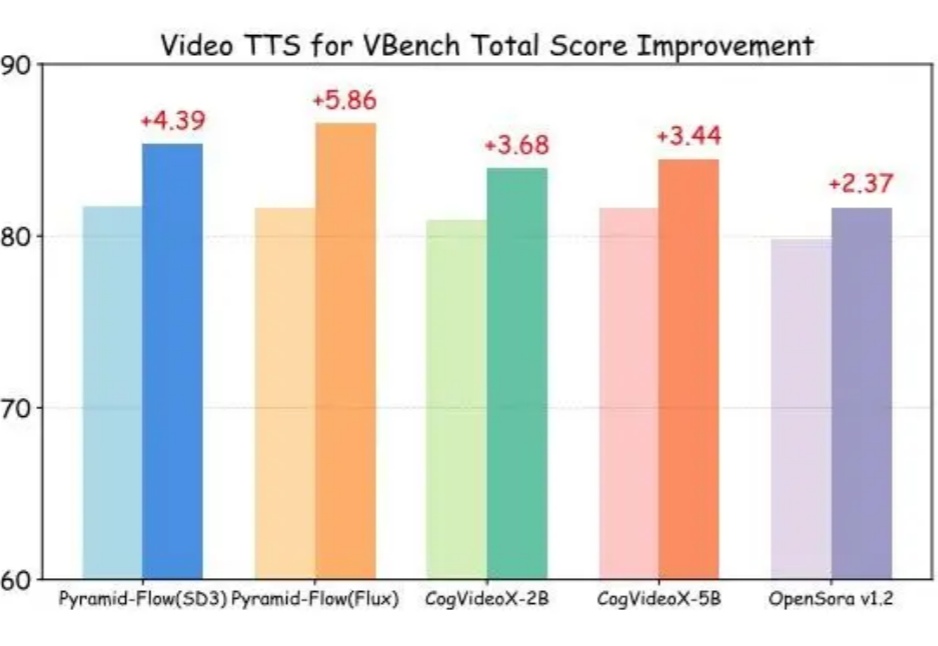
视频作为包含大量时空信息和语义的媒介,对于 AI 理解、模拟现实世界至关重要。视频生成作为生成式 AI 的一个重要方向,其性能目前主要通过增大基础模型的参数量和预训练数据实现提升,更大的模型是更好表现的基础,但同时也意味着更苛刻的计算资源需求。

超低成本图像生成预训练方案来了——仅需8张GPU训练,就能实现近SOTA的高质量图像生成效果。