



57.1%的人分不清真假!Runway新视频模型太爆炸
57.1%的人分不清真假!Runway新视频模型太爆炸不er,这个世界还有什么是真的?反正我是已经分不清了...
来自主题:
AI资讯
7225 点击 2026-01-22 17:14
不er,这个世界还有什么是真的?反正我是已经分不清了...

最有看点的苹果产品要来了,但可能不是 iPhone。
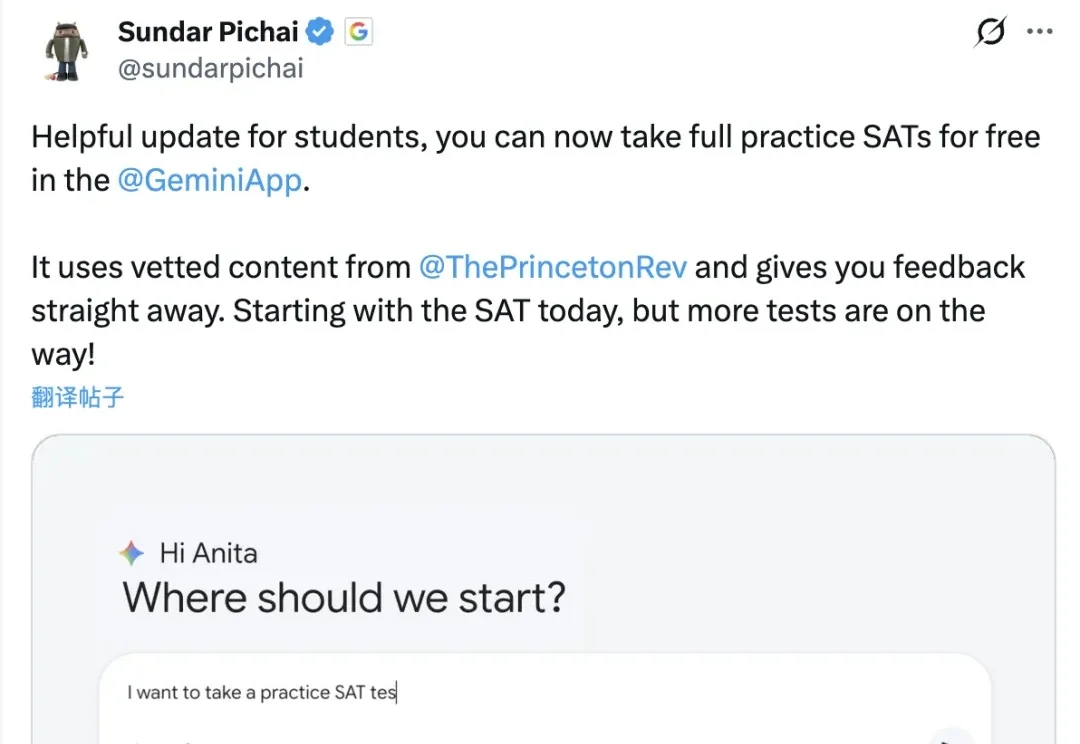
谷歌来给考生送福利了!

2026年,AI的第一个规模商业化赛道—AI漫剧,正在爆发。

马斯克要亲自下场抢人了。

在当前的AI Research浪潮中,Autonomous Agents已经改变了我们获取信息的方式——从被动接收到主动检索。

今年的达沃斯,没有一个论坛不讲AI的。
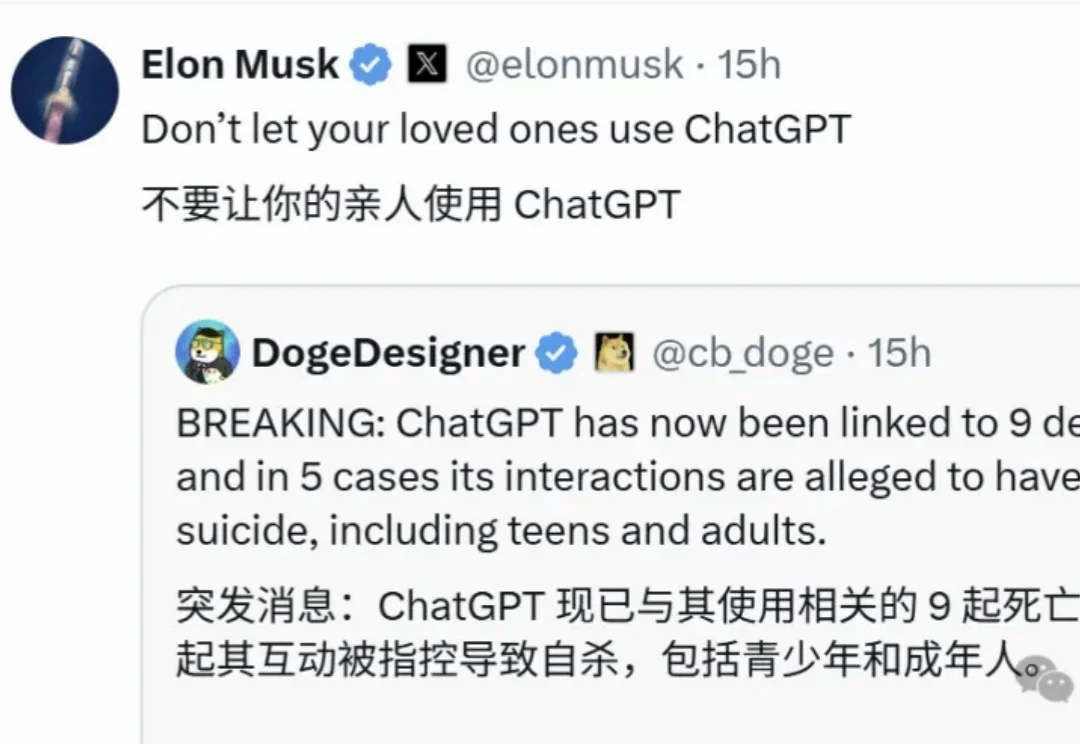
周二早上,马斯克和奥特曼又吵起来了。
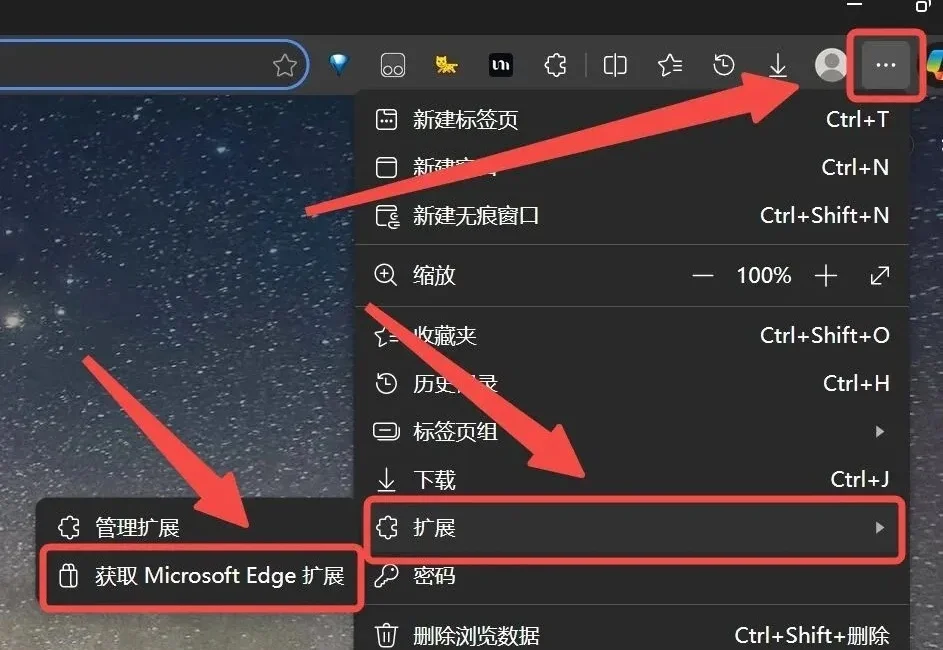
最近群里好多朋友在问我,Gemini 生成的图片水印能不能去掉。
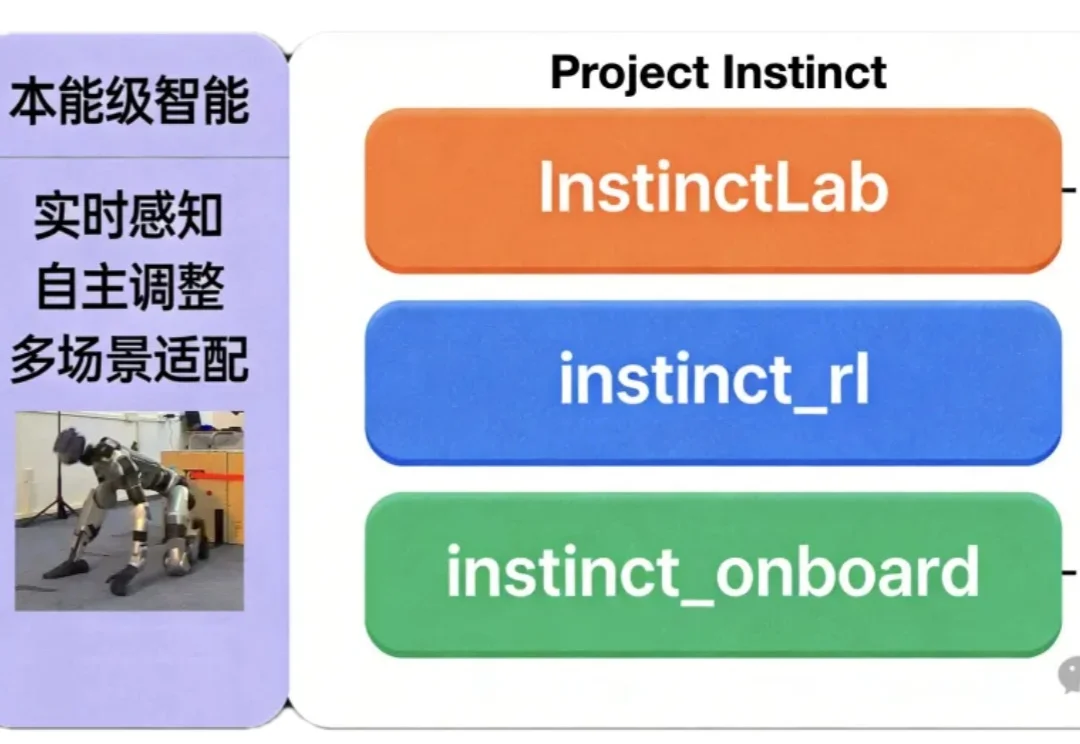
如何让机器人同时具备“本能反应”与复杂运动能力?

聊天救不了命!这家中国AI选择死磕临床:斩获中美日欧全满贯认证,落地全球5000家医院,硬是走通了这条「最难的路」。
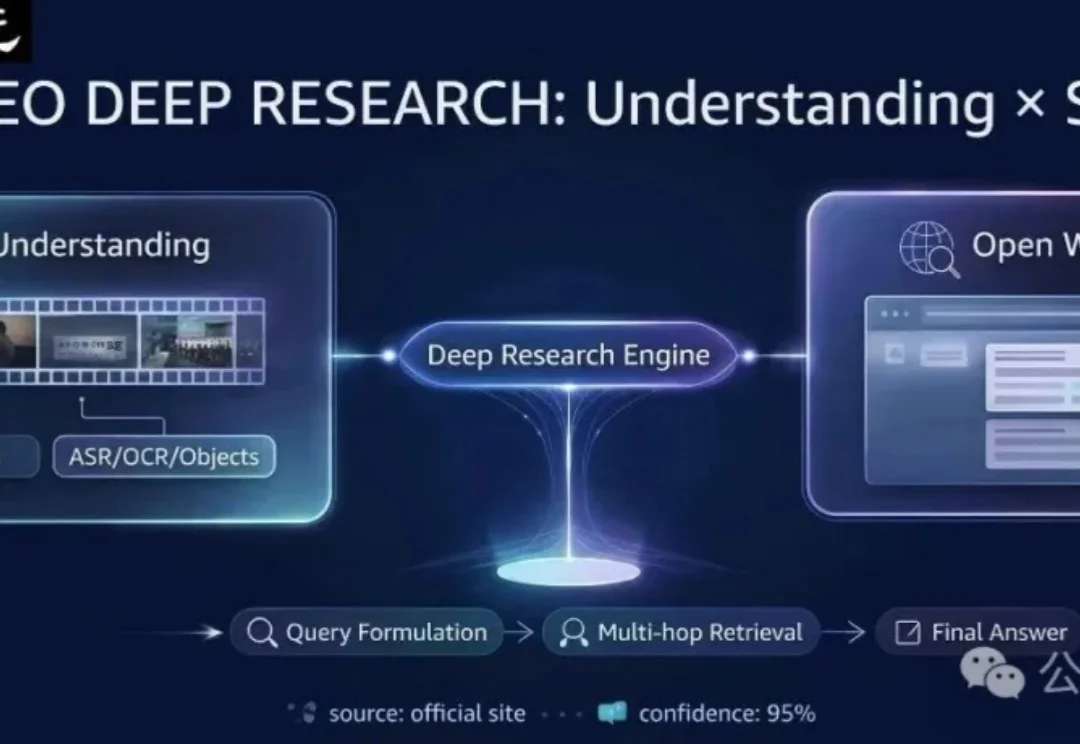
现有的多模态模型往往被困在「视频」的孤岛里——它们只能回答视频内的问题。但在真实世界中,人类解决问题往往是「看视频找线索 -> 上网搜证 -> 综合推理」。
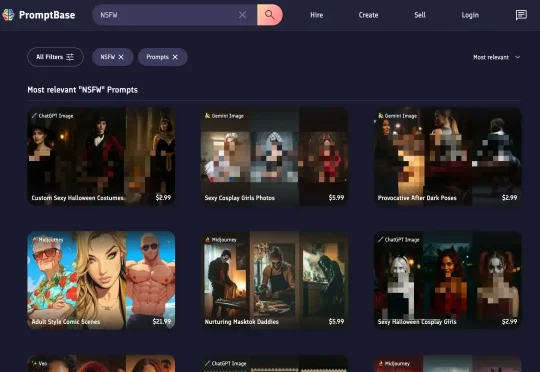
比如说,最近有一个叫做 Unlucid.ai 的视频生成网站流量很好,排名窜的很快,在这个网站主页里,你能看到非常「像片儿」的 AI 生成视频:有人反复试错,研究哪些描述可以通过,哪些词语组合更容易出结果,怎样的写法既不触发拦截,又能让画面往“成人内容”的方向靠近。
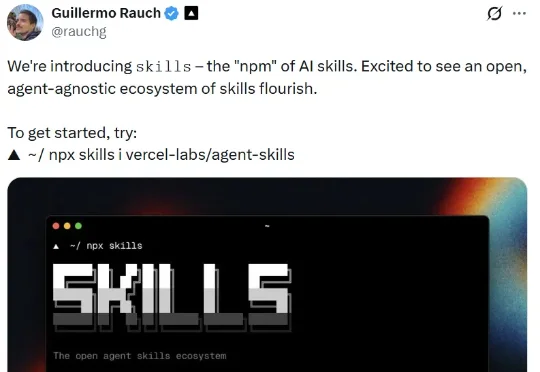
比如前些天,Vercel 创始人 Guillermo Rauch 推出了所谓的「AI skill 的 npm」,让用户仅需一个简单命令 npx skills add [package],就能为自己的 AI 智能体轻松注入专业能力。

就在刚刚,Liquid AI 又一次在 LFM 模型上放大招。他们正式发布并开源了 LFM2.5-1.2B-Thinking,一款可完全在端侧运行的推理模型。Liquid AI 声称,该模型专门为简洁推理而训练;在生成最终答案前,会先生成内部思考轨迹;在端侧级别的低延迟条件下,实现系统化的问题求解;在工具使用、数学推理和指令遵循方面表现尤为出色。
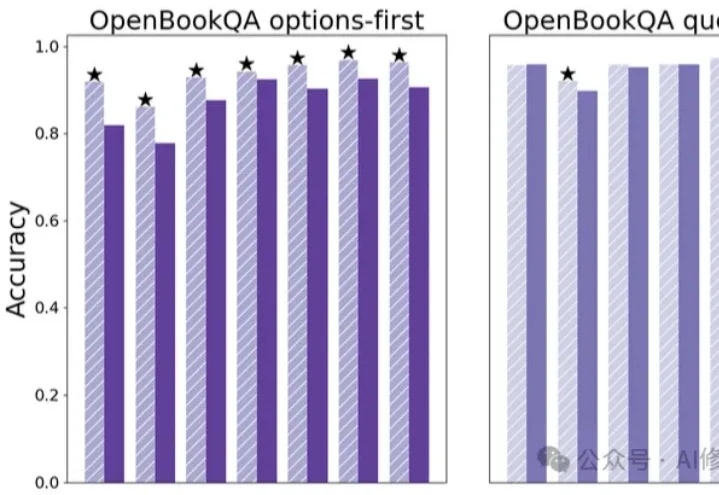
竟然只需要一次Ctrl+V?这可能是深度学习领域为数不多的“免费午餐”。

随着AI浪潮的袭来,笔者本人以及团队都及时的调整了业务方向,转型为一名AI开发者和AI产品开发团队,常常需要微调大模型注入业务场景依赖的私域知识,然后再把大模型部署上线进行推理,以支撑业务智能体或智能问答产品的逻辑流程。
给马斯克干活,压力真的好大!
想象一家“永不眠”的公司:白天,全天候运行的 Google Meet 与麦克风捕捉着办公室内的每一处沟通细节,AI 助理实时解析、拆解任务,并在次日清晨8点将策略与进度精准推送到员工指尖;夜幕降临,当人类休息时,另一套自动化流程无缝接管——监测报错、编写代码、生成PR,静待工程师次日一键合并。
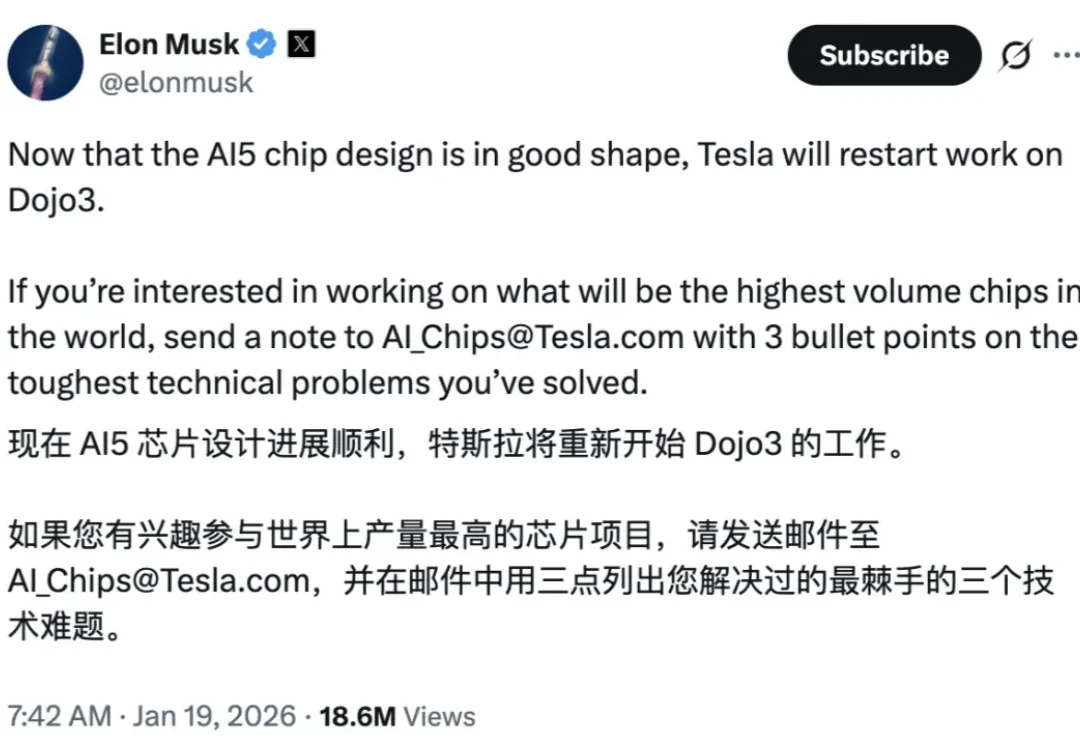
刚刚,马斯克丢了个重磅炸弹:「AI5 芯片设计进展顺利,特斯拉将重启 Dojo3 的工作。」
要不是 App Logo 上那只举着魔法棒的小狗先「剧透」,你很难把它和京东联系在一起。
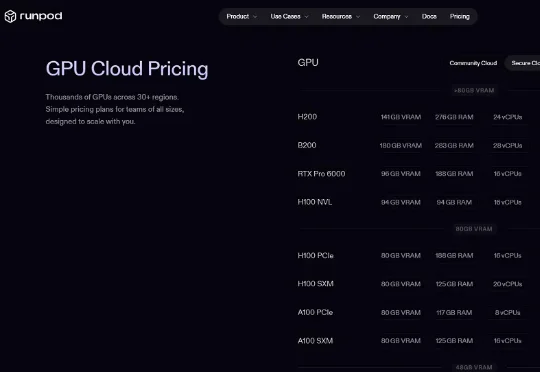
又一家ARR突破1亿美元的AI创企诞生了!近日,由华人CEO领衔的美国AI云创企RunPod对外披露,其年化收入已达到1.2亿美元(约合人民币8.35亿元),平台累计开发者用户数超过50万。
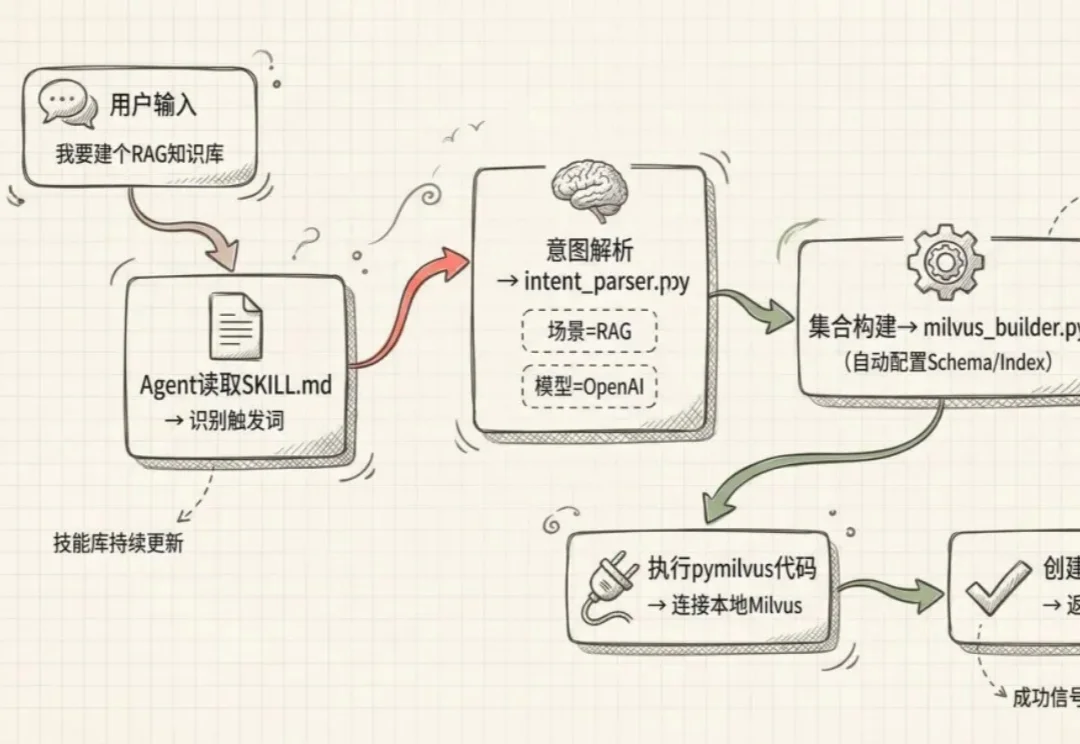
Agent很好,但要做好工具调用能才能跑得通。

我对Atoms的印象是没有印象。
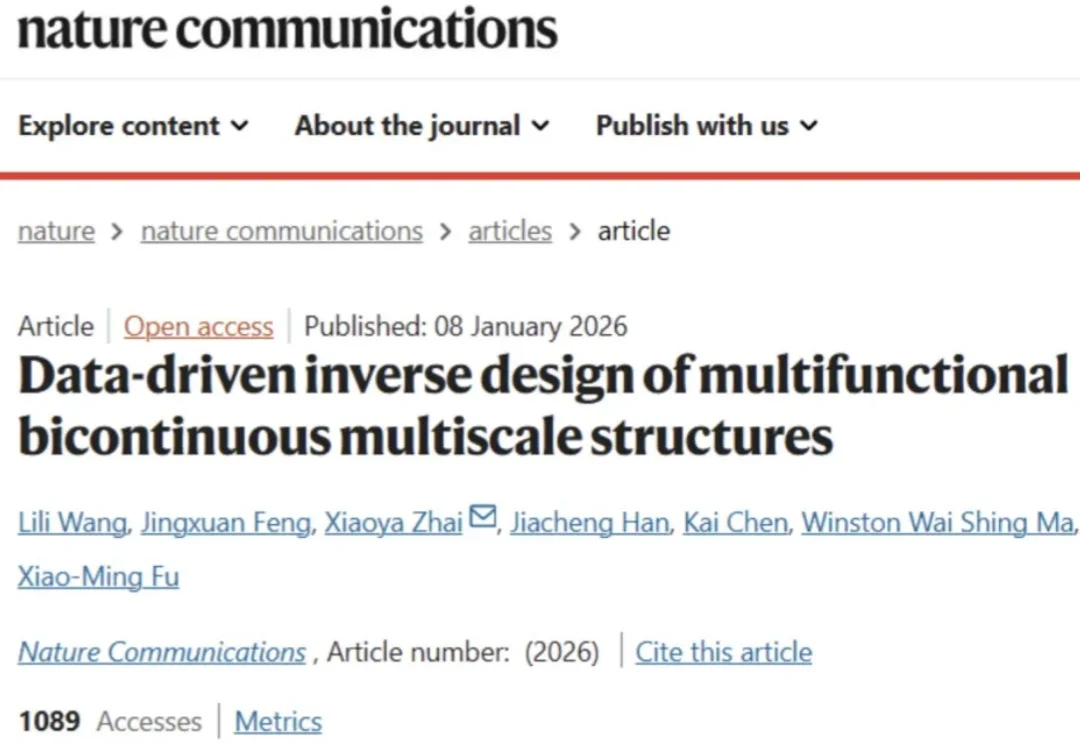
近日,中国科学技术大学(USTC)联合新疆师范大学、中关村人工智能研究院、香港理工大学,在数据驱动的多功能双连通多尺度结构逆向设计领域取得重要突破。

我经常一种票据风格的提示词帮我的内容生成图片,很多朋友一直问啥时候发。

现有AI记忆评测存在局限,如数据源单一、忽视变化本质、注入成本高等。CloneMem通过层次化生成框架构建合成人生,设计贴近真实场景的评测任务,涵盖多种问题类型。
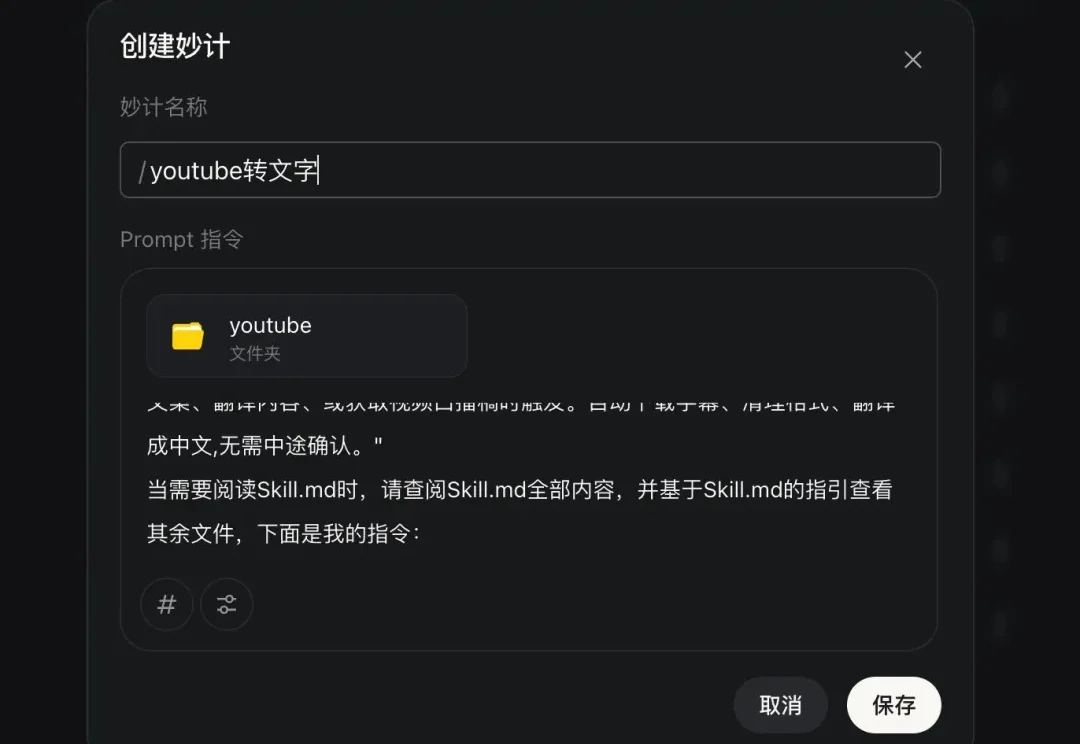
1 月 13 日,Claude Cowork 发布,我的朋友圈被刷屏了。

随着大模型在单点推理上日益逼近 PhD 水平,Agent 领域迎来了新的分水岭:短程任务表现惊艳,长程任务却显乏力。为精准评估大模型的多模态理解与复杂问题解决能力,红杉中国在两周内连续发布两篇论文,旨在通过构建更科学的评估基准,预判技术演进的未来方向。

太抓马了!奥特曼的宫斗大戏,竟然还有内幕? 就在奥特曼被董事会罢免的那个周末,微软差点来了一波雇佣式收购。 短短一天,资金、法律文书就全部到位,连名字都想好了……

