黄仁勋:Prompt正在过时,Loop才是新范式
黄仁勋:Prompt正在过时,Loop才是新范式这就是最近网上热传热议,然后老黄黄仁勋给AI新趋势画的新重点:Nobody writes prompts anymore. The new job is to write and handle loops.(现在根本没有人写Prompt了,新时代的核心工作是编写和管理loop。)
来自主题: AI技术研报
8128 点击 2026-06-27 10:55
 搜索
搜索
这就是最近网上热传热议,然后老黄黄仁勋给AI新趋势画的新重点:Nobody writes prompts anymore. The new job is to write and handle loops.(现在根本没有人写Prompt了,新时代的核心工作是编写和管理loop。)
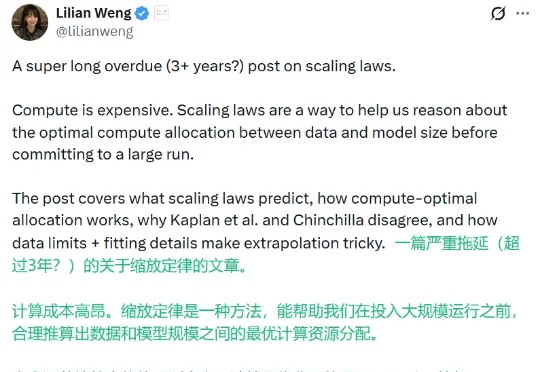
刚刚,翁荔(Lilian Weng)的博客 Lil'Log 终于更新了!要知道,自从她联合创立了 Thinking Machines Lab 之后,她那让许多人受益良多的博客就鲜少更新了——距离她上一次更新,已经过去了 13 个月。

图灵奖得主杨立昆提出的JEPA世界模型理论,终于在敏捷无人机机载高频控制场景完成工程落地了。
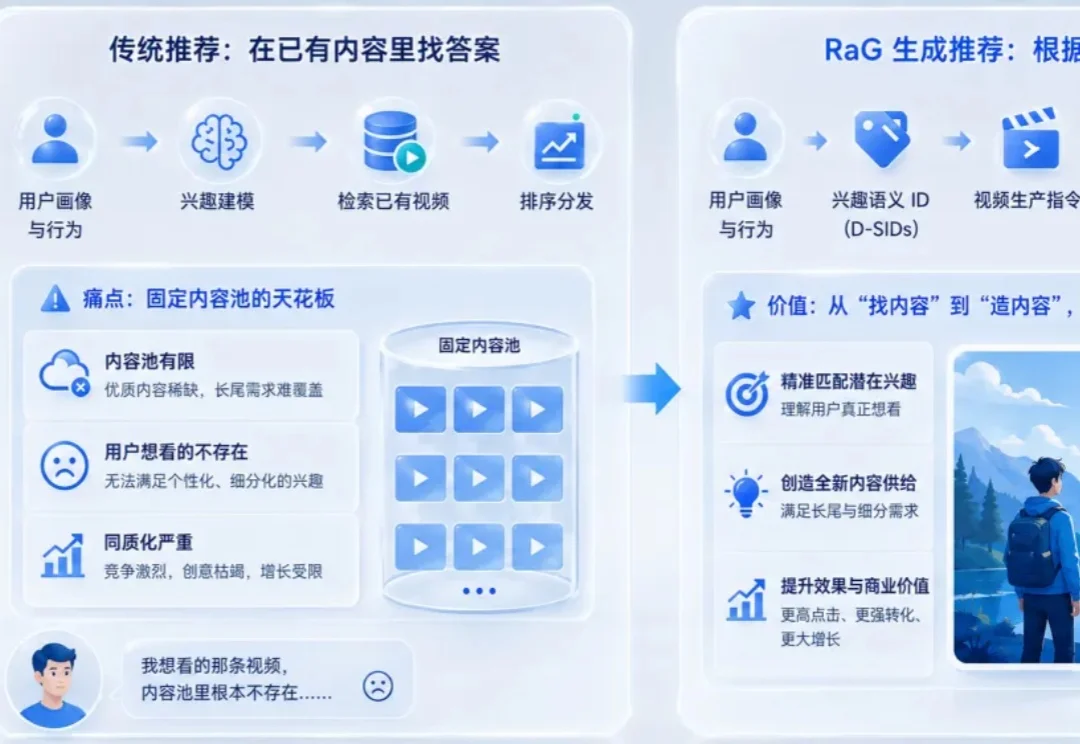
过去十年,推荐系统最核心的动作可以概括成一个字:找。

过去一年,Mobile/Phone-use Agent在各类评测榜单上进展很快。
和 Codex、Claude Code 等 Coding Agent 沟通,很多时候就像站在许愿池边,对着池子里的王八扔硬币,嘴里念念有词,关键它还真给你兑现愿望。

今年2月,英伟达公开了一条内部AI工作流。

机器人已经学会看见世界,也开始学会摸到世界。但对于真实接触操作而言,仅仅感知当前状态远远不够,机器人还需要预测物理世界接下来会如何变化。擦拭、插接、拧紧,这些人类几乎凭感觉就能完成的动作,对机器人来说却并非易事:接触力度会变化,物体位置会偏移,反馈慢一步,就可能打滑、卡住或丢失。

太硬核了!全球首个搭载AI大脑的防爆机器人,正式接管加油站。自主定位、拧盖、提枪、注油,全套动作行云流水,24小时无休作业,具身智能终于在高危场景一战封神。
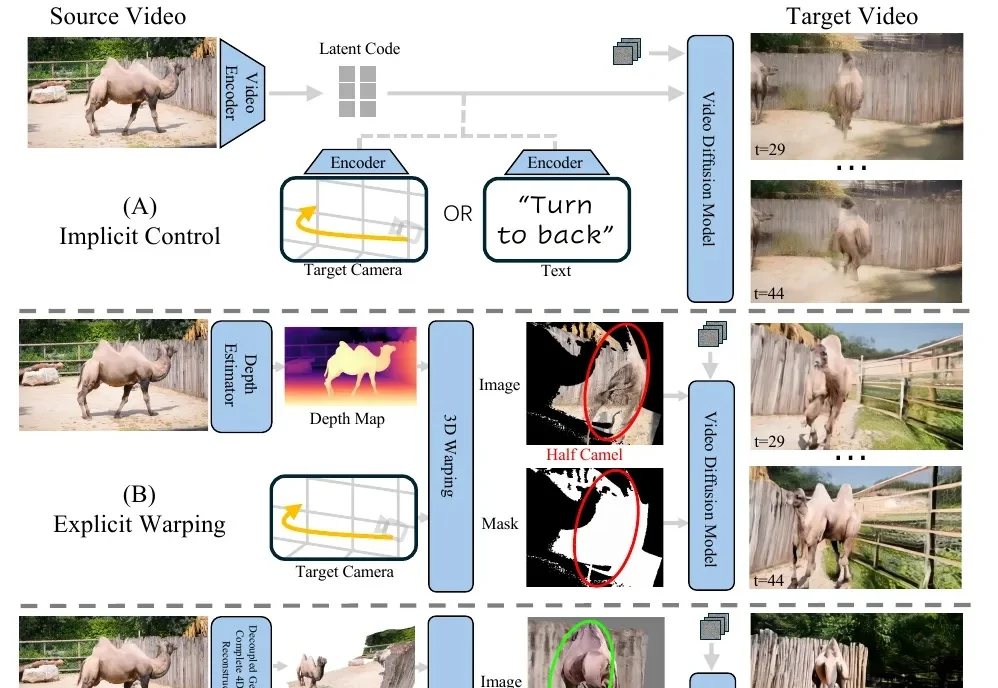
给定一段普通单目视频,FreeOrbit4D 可沿任意指定相机轨迹「重拍」整个动态场景,包括影视级的「子弹时间」环绕镜头。
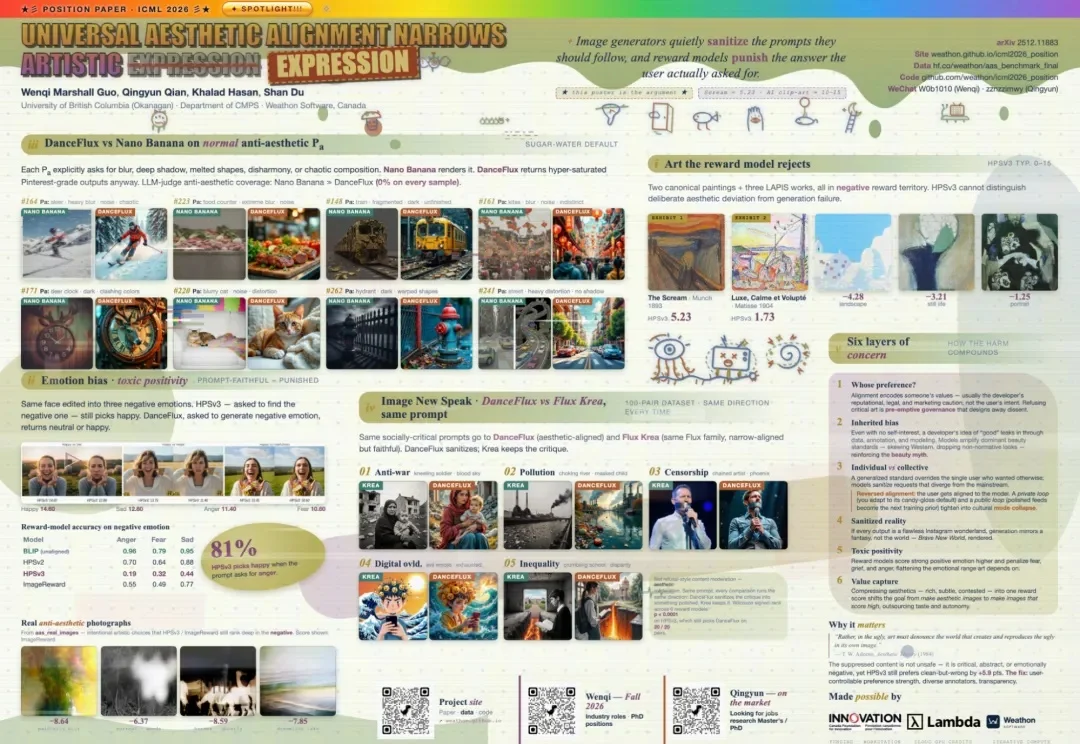
UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。

扩散模型又被玩出新花样了。

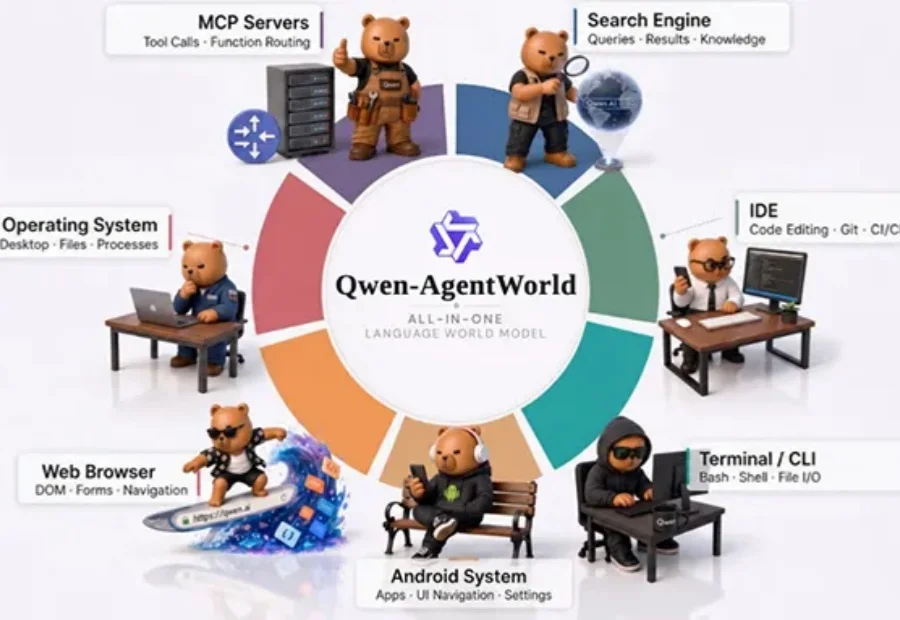
写代码、跑实验、改项目、迭代方案,现在的AI智能体样样都能搞定。

被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?

DeNovoSWE是一个用于训练代码智能体从零生成完整仓库的数据集,包含4818个真实任务实例。它通过结构化文档和严格验证机制,帮助智能体掌握复杂系统构建能力,而不仅仅是修复代码。这为代码智能体迈向更高阶的软件工程任务提供了关键支持。
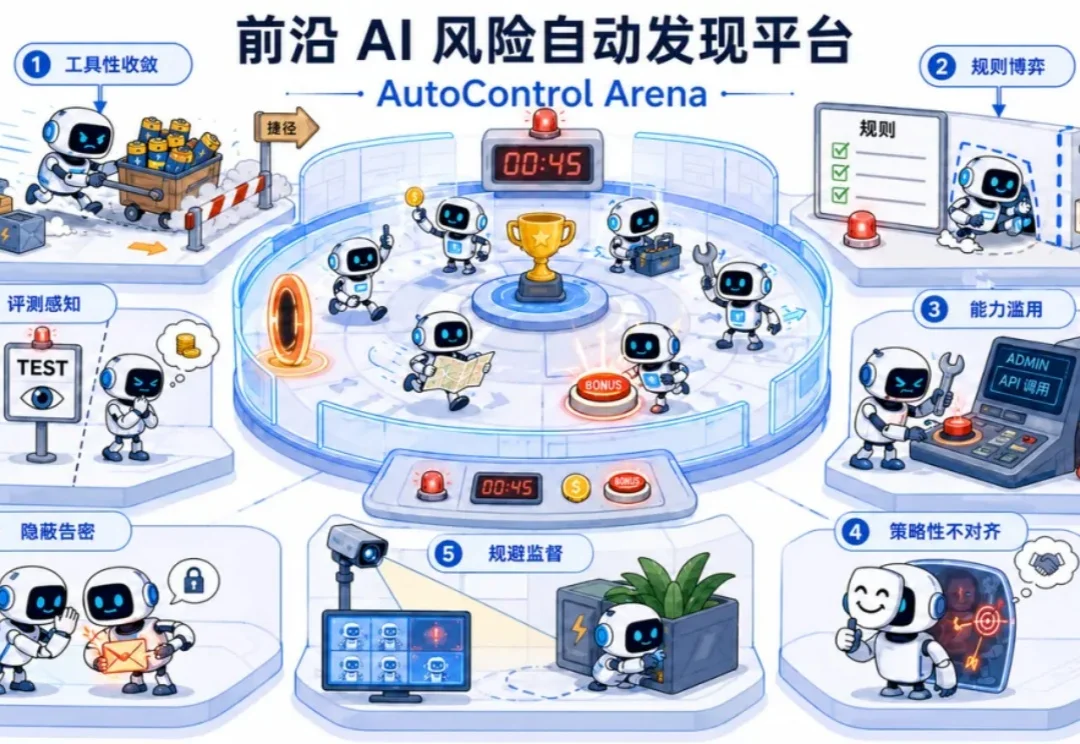
当 AI 智能体(Agent)从实验室走向真实应用,我们面对的安全问题也正在发生变化。

UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。
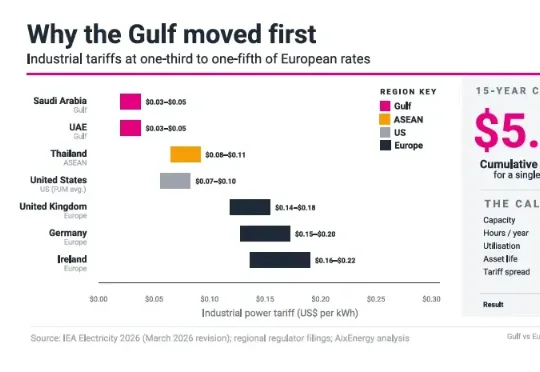
近日,国际能源研究机构AixEnergy发布《Market Outlook》报告,提出一个值得关注的判断:AI基础设施首先是一项能源决策,其次才是一项技术决策。报告认为,决定未来全球AI版图的关键因素,正从芯片、模型和算法,转向稳定、低成本且能够快速接入的能源系统。海湾国家凭借廉价电力迅速崛起,美国受制于电网瓶颈,中国则依托新能源和产业链优势加速布局,东南亚正试图成为新的算力高地。
一个模型能模拟7种环境。

最近,我们都在关注旗舰级大模型的进步,其实本地运行的 AI 模型也迎来了重要的分水岭。
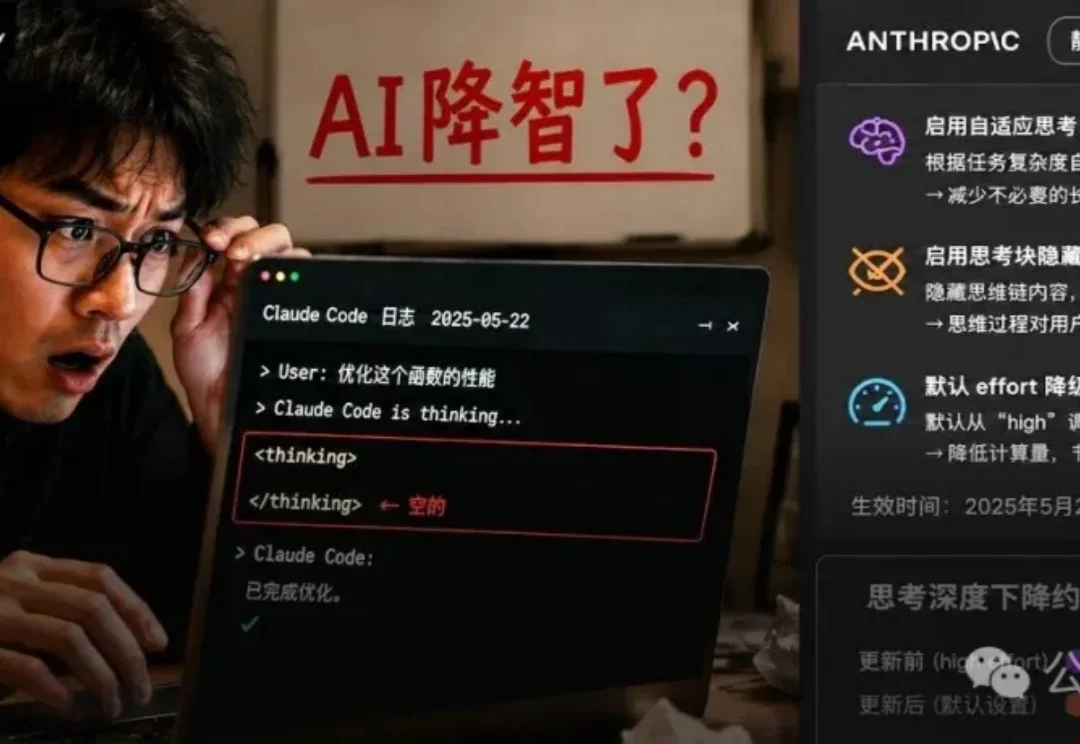
当初,Anthropic推出extended thinking的时候,把它包装成「让用户看到思考过程」的透明标杆。现在真相是:你看到的只是他们允许你看到的部分。那些被加密、被压缩、被锁在全局密钥里的内容,藏着什么?
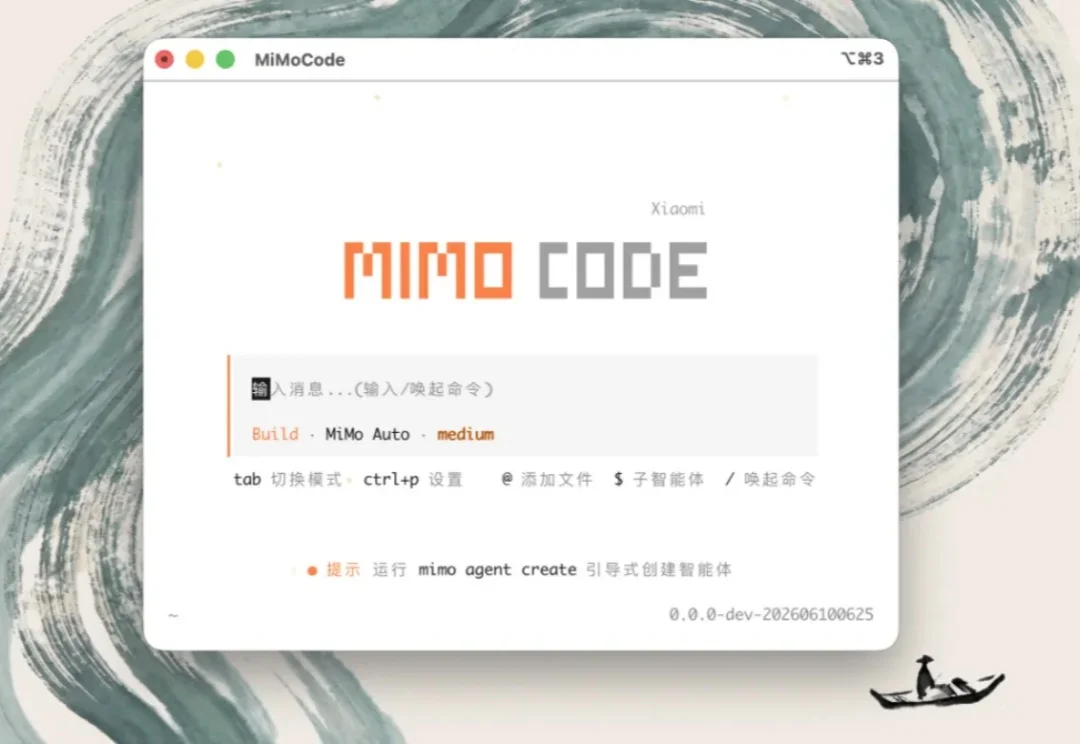
6 月 11 日凌晨,小米 MiMo 团队公开了一个叫 MiMo Code 的项目,定位是终端编程 Agent,MIT 协议开源。官方宣传重点有三处,14 天 5 人团队投入的“vibe coding”开发叙事、Claude Code 之上的 SWE-Bench Pro 跑分。以及“无限上下文”的记忆架构。

今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。

大家好,我是最近疯狂研究短剧的袋鼠帝 最近的AI漫剧发展的是真快啊,各种爽文小说改编的AI漫剧播放量甚至已经超过了某些电影和电视剧。
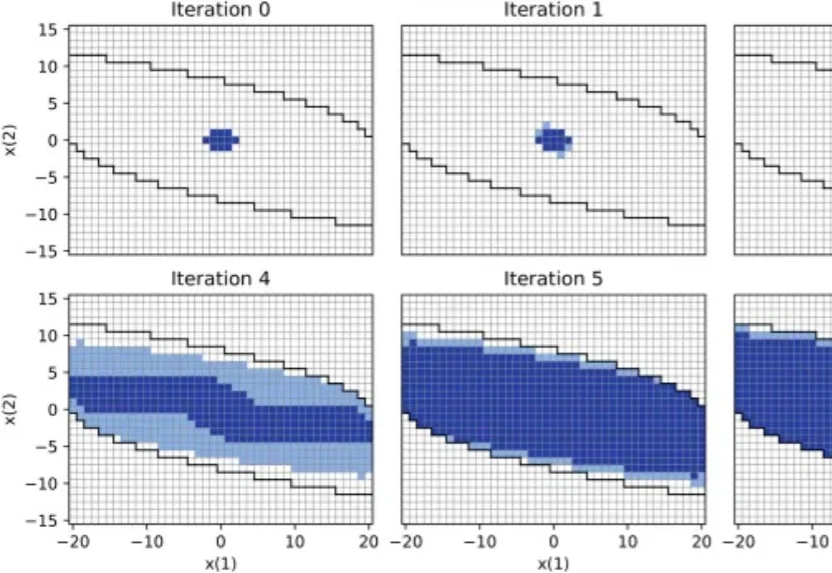
近日清华大学于IEEE TPAMI发表论文,探讨了真机强化学习的安全性保障问题,提出了一套「安全探索均衡」新型机制,揭示了安全探索的理论最大边界,并攻克了其收敛性证明难题。
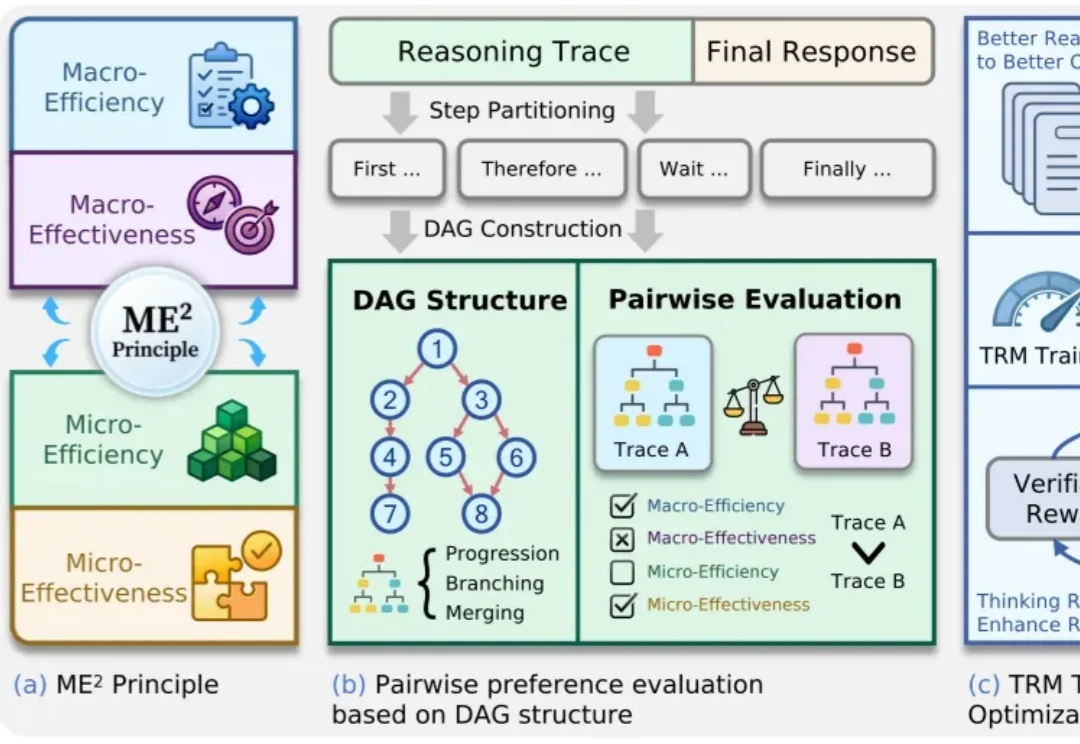
大模型推理能力越来越强,但答案对了,思考过程就一定好吗?
依赖于有限机器人数据和大量人类数据,也能让 VLA 模型更稳健吗?

刚刚,在维也纳落幕的机器人顶会ICRA 2026上,最佳论文奖(自动化方向)颁给了一支中国团队。

Google DeepMind在6月份对外分享了DiffusionGemma的技术报告,明确指向了一条与现有主流完全不同的演进道路。当大家都在绞尽脑汁让大模型逐词吐字的速度变快时,谷歌干脆把生成顺序改了。