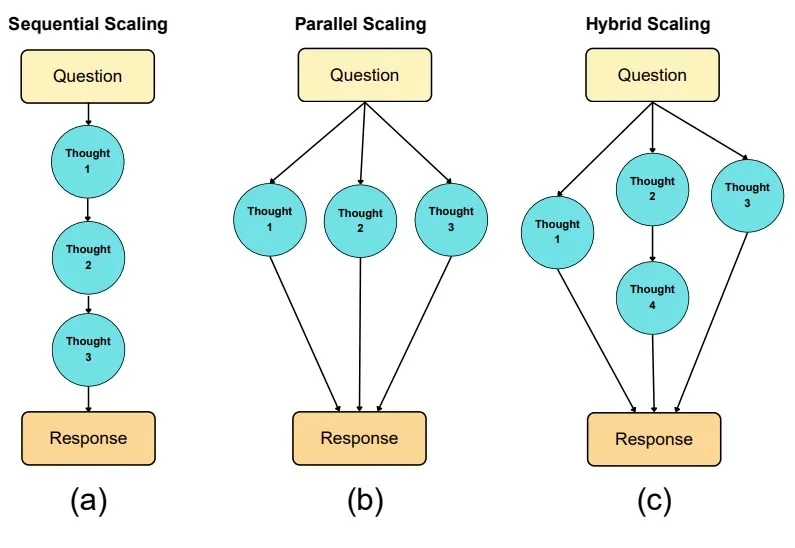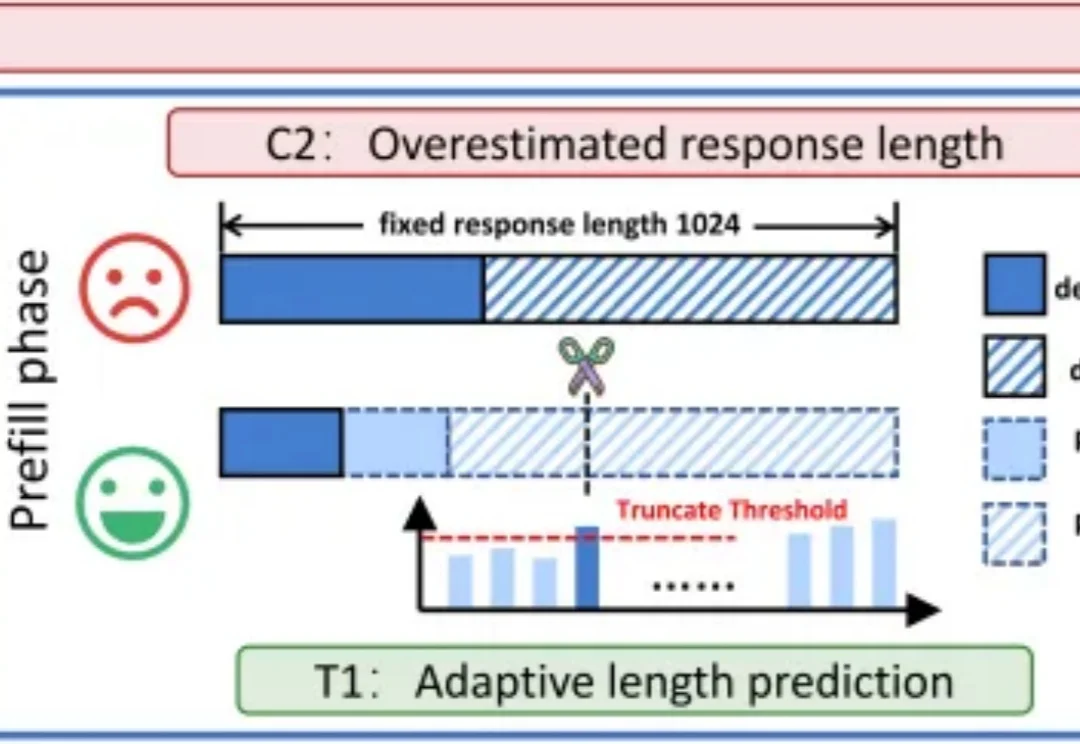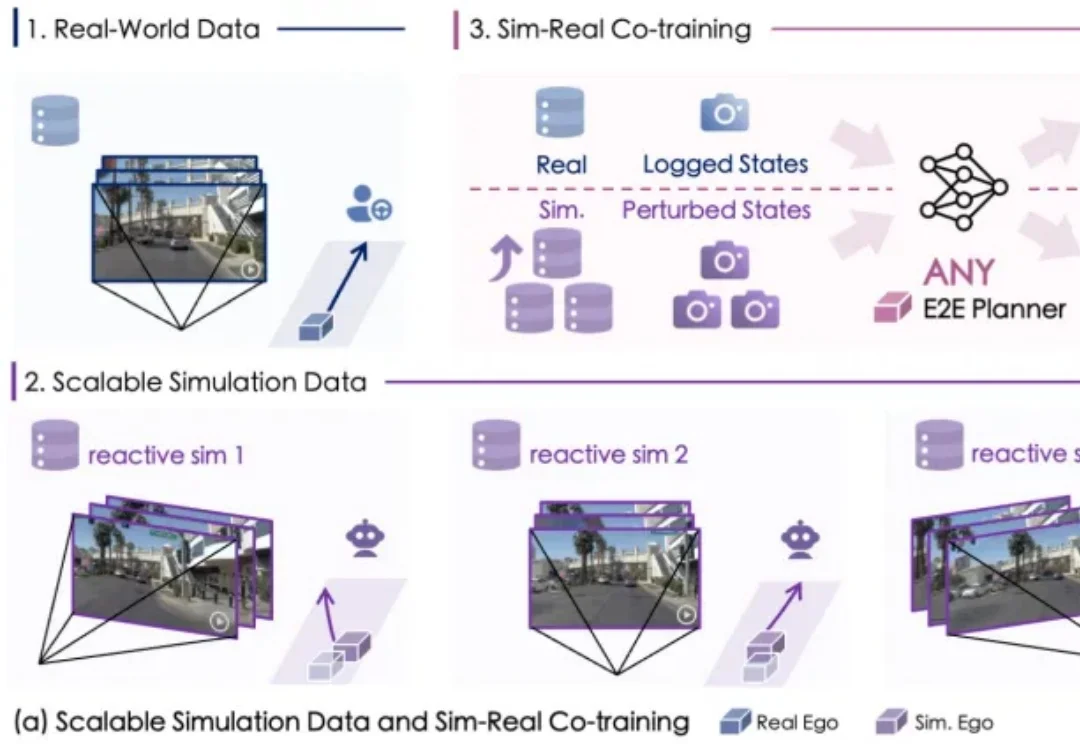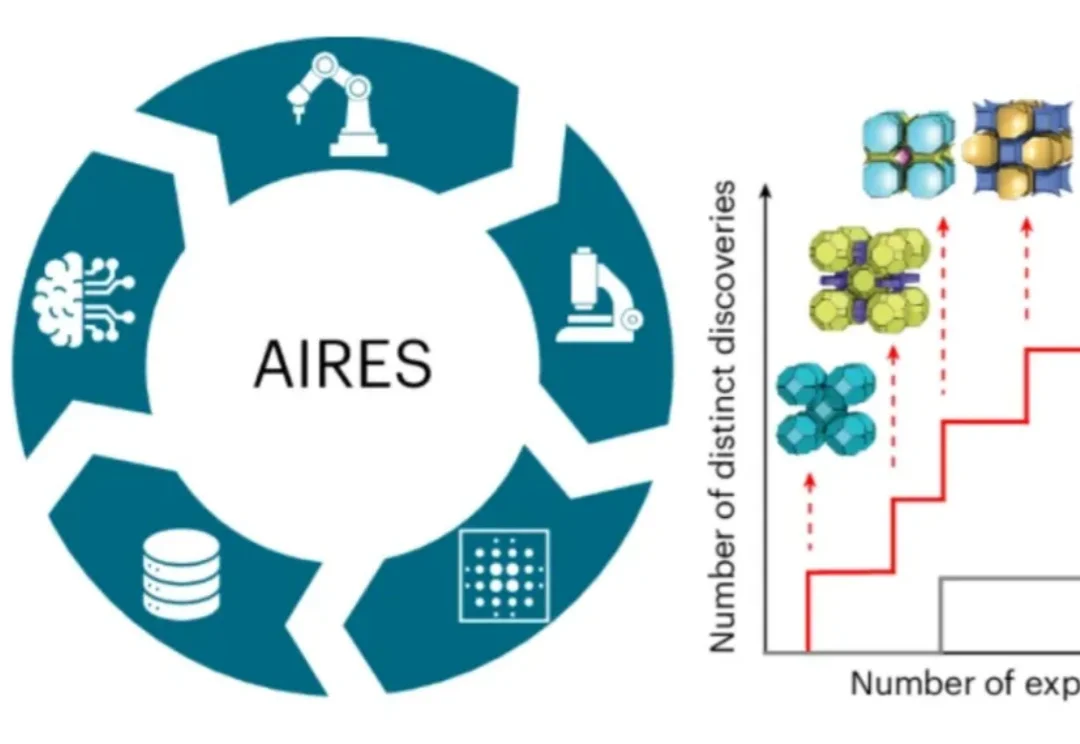
NUS LV Lab新作|FeRA:基于「频域能量」动态路由,打破扩散模型微调的静态瓶颈
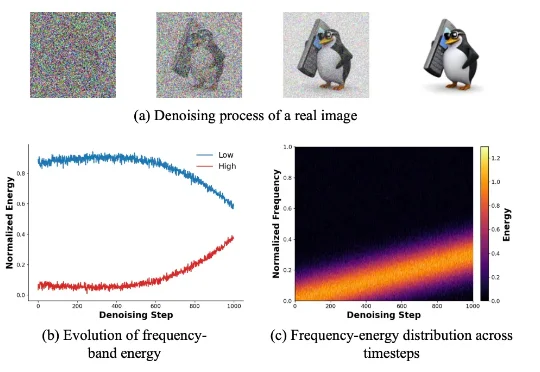
NUS LV Lab新作|FeRA:基于「频域能量」动态路由,打破扩散模型微调的静态瓶颈新加坡国立大学 LV Lab(颜水成团队) 联合电子科技大学、浙江大学等机构提出 FeRA (Frequency-Energy Constrained Routing) 框架:首次从频域能量的第一性原理出发,揭示了扩散去噪过程具有显著的「低频到高频」演变规律,并据此设计了动态路由机制。
来自主题: AI技术研报
7783 点击 2025-12-12 15:34