
B300现状调研,供给断裂 ,信用崩塌
B300现状调研,供给断裂 ,信用崩塌最近的B300市场可以说是“冰火两重天”——群里叫卖得火热,实际成交却降至冰点。老美的出口管制如同悬在头顶的达摩克利斯之剑,彻底改变了顶级算力芯片的流通逻辑。 以下是基于近期一线实操、买卖双方博弈以及
来自主题: AI资讯
9007 点击 2026-06-14 11:51
 搜索
搜索
最近的B300市场可以说是“冰火两重天”——群里叫卖得火热,实际成交却降至冰点。老美的出口管制如同悬在头顶的达摩克利斯之剑,彻底改变了顶级算力芯片的流通逻辑。 以下是基于近期一线实操、买卖双方博弈以及
刚刚,田渊栋创业公司,交出了首个研究成果。田渊栋在X上宣布,其创立的Recursive,在NVIDIA官方的GPU kernel优化榜SOL-ExecBench上拿下了整体和四个子类别的SOTA。
今日,小米MiMo团队与推理系统团队TileRT联合宣布,Xiaomi MiMo-V2.5-Pro的UltraSpeed模式已实现万亿参数(1T)旗舰模型输出速度首次突破1000 tokens/s。

复盘三年多的AI行情,就是一个不断找硬件瓶颈的过程:最开始涨GPU,后来涨服务器,再后来涨数据中心,然后涨电力,接着涨HBM存,现在又开始涨CPU、高速互联和ASIC。
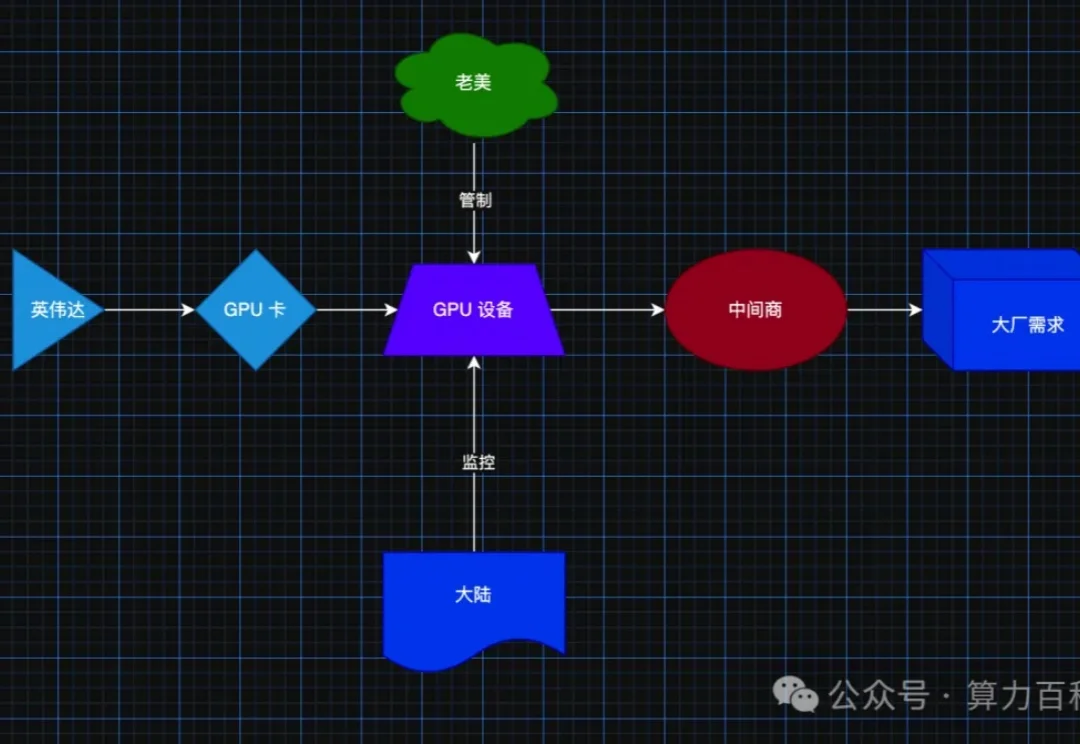
5 月份,非常非常多的人寄希望于两个大佬谈判之后的的 GPU管制放松,特别是上一代 hopper架构的顶配算力卡松绑,弥补内部的算力不足,但是结果事与愿违,双方在 GPU 算力领域抓紧了卡脖子竞赛,彼此相互掐。(不要抱幻想了,干就完了)

在具身智能训练中,“把计算全部塞进GPU”似乎成了唯一的提速密码,机器人运控并行训练的框架,IsaacLab、MuJoCoPlayground、mjlab都默认遵循这一范式,这些系统都牢牢绑定在NVIDIA生态中。

Omdia这份名为《2026全球AI工厂市场格局》的报告,点明了新时代的核心逻辑——决定胜负的,不再是谁拥有更多GPU,而是谁能够更高效地把“电力+算力+数据”转化为真正有价值的Token。

所有人都在比谁的模型参数更大,但真正决定AI能不能落地的,其实是另一件没那么性感的事:一颗Token,能不能被稳定、便宜、规模化地生产出来。死磕这件事的,是一支从中国超级计算体系里走出来的年轻团队,是石科技。
ElevenLabs的声音克隆和长文本音频生成质量确实很好,但也太贵了。

当所有人都在盯着 GPU,真正卡住 AI 脖子的,是另一块芯片。