

GPT在模仿人类?Nature发现:大脑才是最早的Transformer!
GPT在模仿人类?Nature发现:大脑才是最早的Transformer!我们以为语言是语法、规则、结构。但最新的Nature研究却撕开了这层幻觉。GPT的层级结构与竟与人大脑里的「时间印记」一模一样。当浅层、中层、深层在脑中依次点亮,我们第一次看见:理解语言,也许从来不是解析,而是预测。
来自主题: AI技术研报
8744 点击 2025-12-12 09:39
我们以为语言是语法、规则、结构。但最新的Nature研究却撕开了这层幻觉。GPT的层级结构与竟与人大脑里的「时间印记」一模一样。当浅层、中层、深层在脑中依次点亮,我们第一次看见:理解语言,也许从来不是解析,而是预测。

谷歌DeepMind掌门人断言,2030年AGI必至!不过,在此之前,还差1-2个「Transformer级」核爆突破。恰在NeurIPS大会上,谷歌甩出下一代Transformer最强继任者——Titans架构。

两项关于大模型新架构的研究一口气在NeurIPS 2025上发布,通过“测试时训练”机制,能在推理阶段将上下文窗口扩展至200万token。两项新成果分别是:Titans:兼具RNN速度和Transformer性能的全新架构;MIRAS:Titans背后的核心理论框架。

当地时间12月4日下午,谷歌研究员的一篇论文在现场引来了超多AI爱好者的围观。甚至,被业界专家视为“为AGI发展提供了新框架”,一位人士评价为:这篇论文将成为逐步推动实现AGI的5~10篇论文中的一篇。
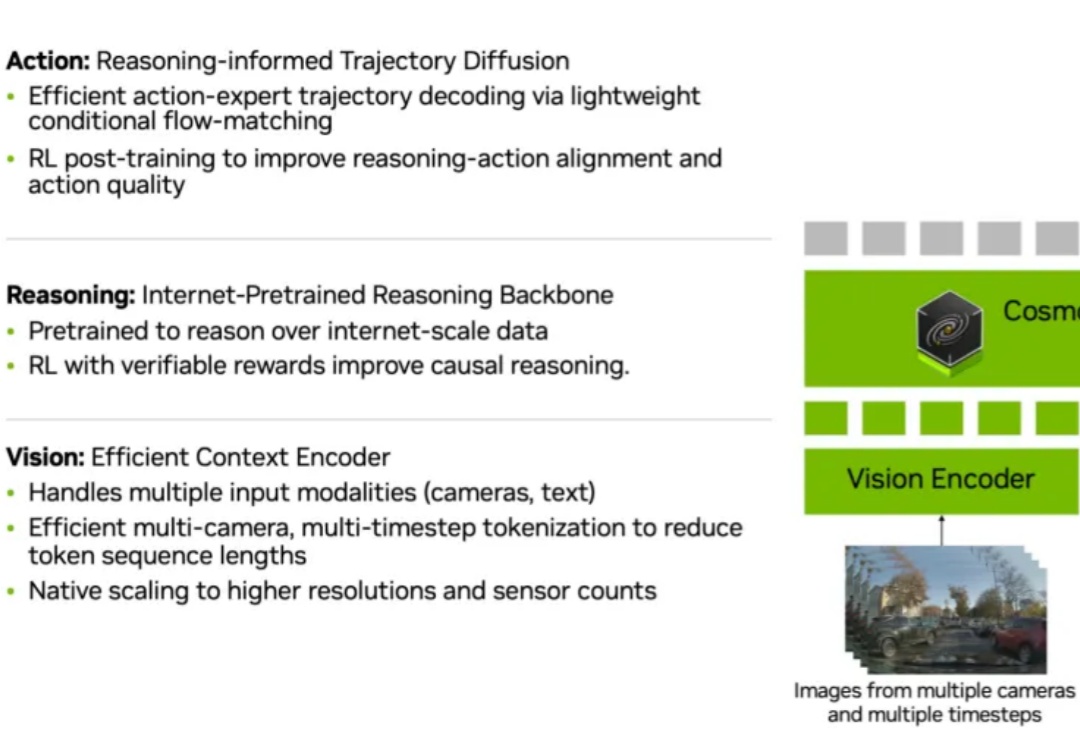
当今自动驾驶模型越来越强大,摄像头、雷达、Transformer 网络一齐上阵,似乎什么都「看得见」。但真正的挑战在于:模型能否像人一样「想明白」为什么要这么开?

我们正在经历一次静悄悄、但本质性的AI范式转换。

当大模型参数量冲向万亿级,GPT-4o、Llama4 等模型不断刷新性能上限时,AI 行业也正面临前所未有的瓶颈。Transformer 架构效率低、算力消耗惊人、与物理世界脱节等问题日益凸显,通用人工智能(AGI)的实现路径亟待突破。

当前,视频生成模型性能正在快速提升,尤其是基于Transformer架构的DiT模型,在视频生成领域的表现已经逐渐接近真实拍摄效果。然而,这些扩散模型也面临一个共同的瓶颈:推理时间长、算力成本高、生成速度难以提升。随着视频生成长度持续增加、分辨率不断提高,这个瓶颈正在成为影响视频创作体验的主要障碍之一。

在视觉处理任务中,Vision Transformers(ViTs)已发展成为主流架构。然而,近期研究表明,ViT 模型的密集特征中会出现部分与局部语义不一致的伪影(artifact),进而削弱模型在精细定位类任务中的性能表现。因此,如何在不耗费大量计算资源的前提下,保留 ViT 模型预训练核心信息并消除密集特征中的伪影?

刚刚,创下日本估值新高的AI初创公司诞生了!