
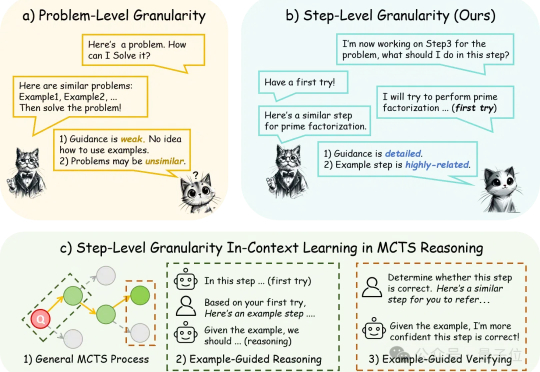
简单示例提升DeepSeek-R1美国数学邀请赛AIME分数:以步骤为粒度对齐上下文学习与推理
简单示例提升DeepSeek-R1美国数学邀请赛AIME分数:以步骤为粒度对齐上下文学习与推理仅需简单提示,满血版DeepSeek-R1美国数学邀请赛AIME分数再提高。
来自主题: AI技术研报
5776 点击 2025-02-20 14:25
仅需简单提示,满血版DeepSeek-R1美国数学邀请赛AIME分数再提高。
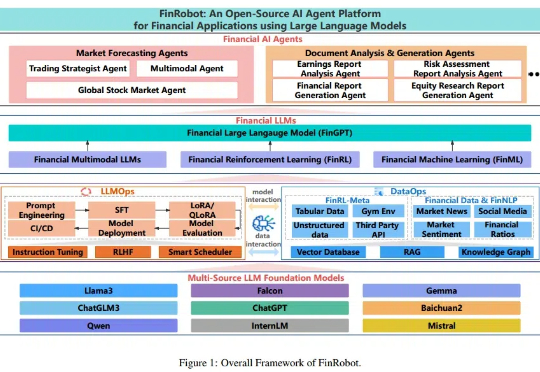
随着金融机构和专业人士越来越多地将大语言模型(LLMs)纳入其工作流程中,金融领域与人工智能社区之间依然存在显著障碍,包括专有数据和专业知识的壁垒。本文提出了 FinRobot,一种支持多个金融专业化人工智能智能体的新型开源 AI 智能体平台,每个代理均由 LLM 提供动力。

DeepSeek爆火甚至引发API低价内卷……
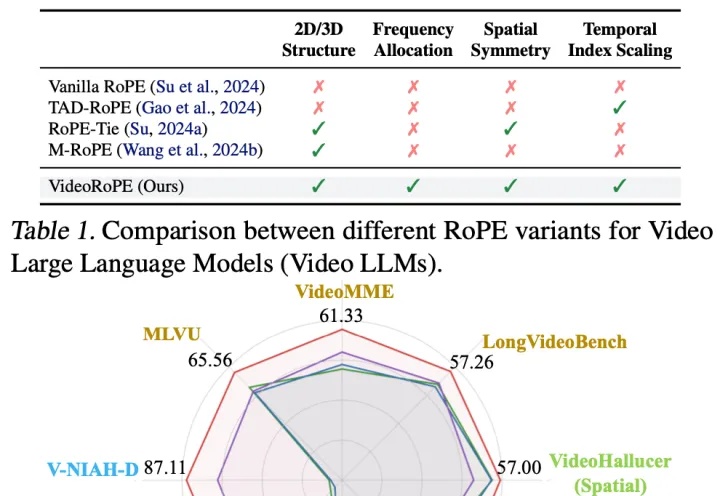
Llama都在用的RoPE(旋转位置嵌入)被扩展到视频领域,长视频理解和检索更强了。
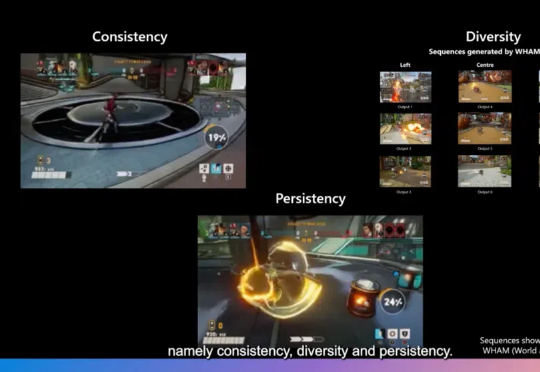
游戏开发不仅需要生成新颖的内容,更需要在保持游戏世界一致性、多样性和用户修改持续性方面达到高度平衡。近日,一篇发表在Nature上的研究论文World and Human Action Models towards Gameplay Ideation揭示了如何利用生成式AI模型推动游戏玩法创意的生成。

OpenAI刚刚发布SWE-Lancer编码基准测试,直接让AI模型挑战真实外包任务!这些任务总价值高达100万美元。有趣的是,测试结果显示,Anthropic的Claude 3.5 Sonnet在「赚钱」能力上竟然超越了OpenAI自家的GPT-4o和o1模型。
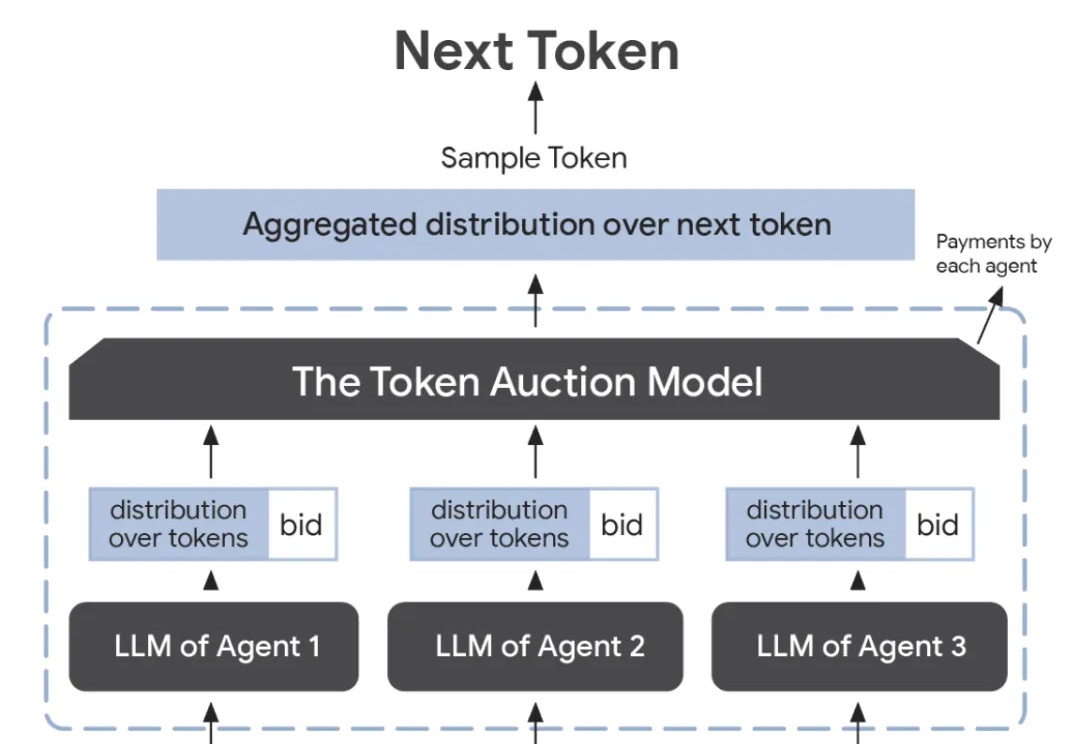
谷歌研究人员提出了一种创新的token拍卖模型,通过「竞拍」的方式,让智能体在文本生成过程中进行出价,确保最终输出能满足各方利益,实现最佳效果。这一机制优化了广告、内容创作等领域的协作。
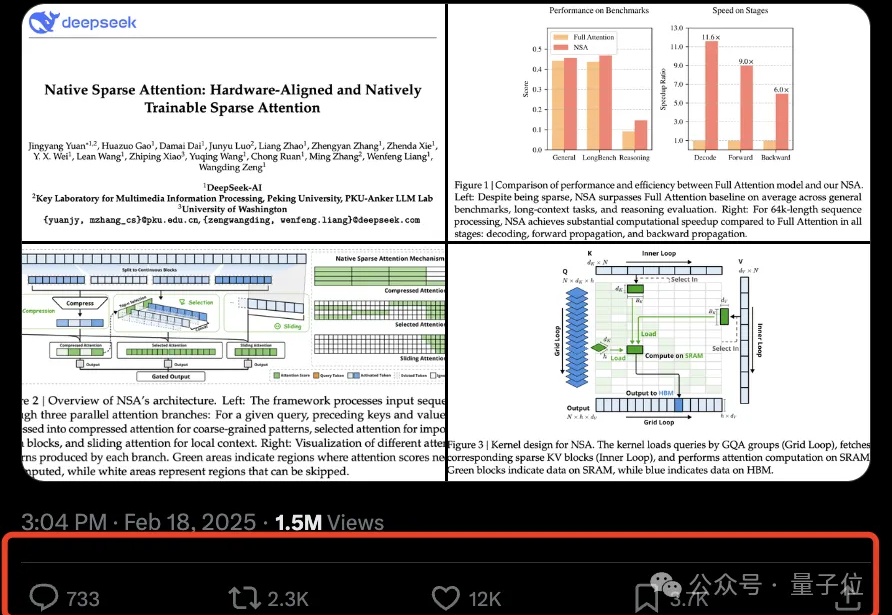
DeepSeek新注意力机制论文一出,再次引爆讨论热度。
全网首发!DeepSeek V3/R1满血版低成本监督微调秘籍来了,让高达6710亿参数AI巨兽释放最强性能。

过去一年,3D 生成技术迎来爆发式增长。在大场景生成领域,涌现出一批 “静态大场景生成” 工作,如 SemCity [1]、PDD [2]、XCube [3] 等。这些研究推动了 AI 利用扩散模型的强大学习能力来解构和创造物理世界的趋势。
“凡我无法创造的,我就无法真正理解。” -- 费曼
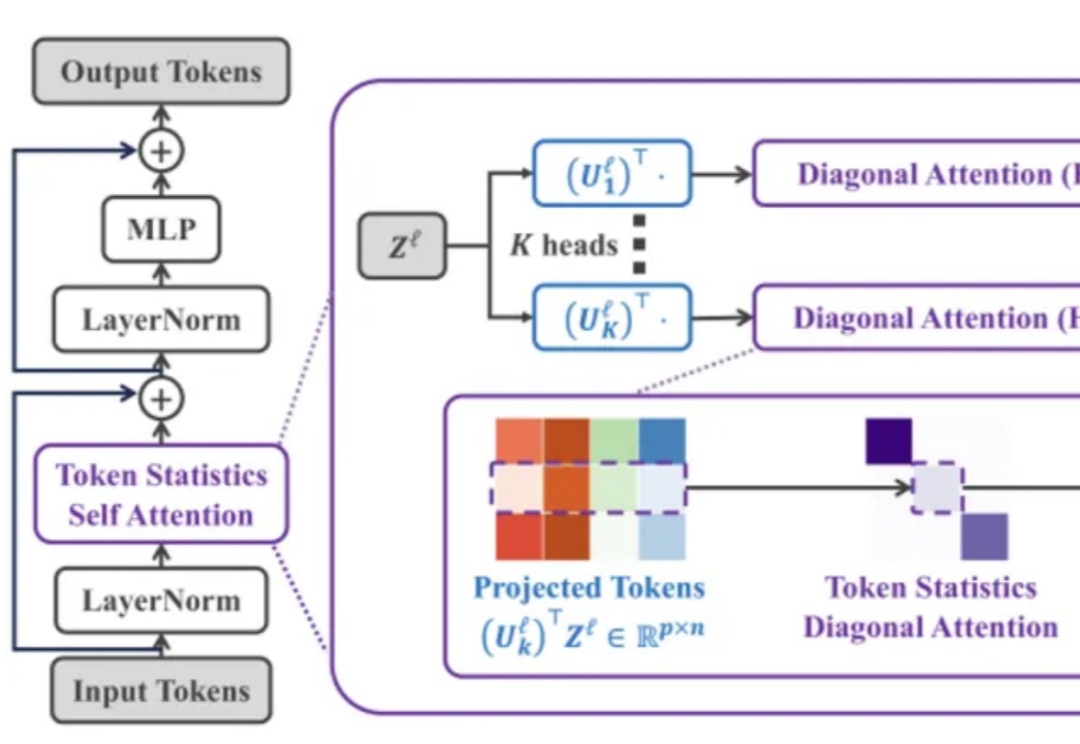
Transformer 架构在过去几年中通过注意力机制在多个领域(如计算机视觉、自然语言处理和长序列任务)中取得了非凡的成就。然而,其核心组件「自注意力机制」 的计算复杂度随输入 token 数量呈二次方增长,导致资源消耗巨大,难以扩展到更长的序列或更大的模型。
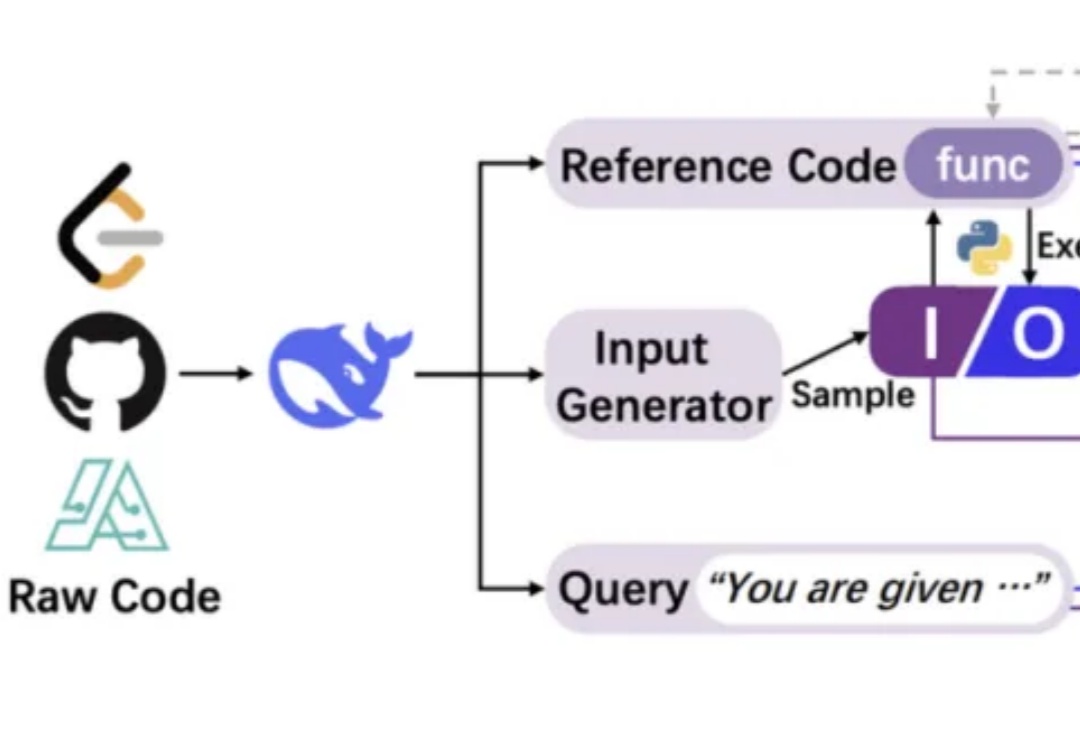
我们正见证一场静默的推理革命。传统AI训练如同盲人摸象,依赖碎片化文本拼凑认知图景,DeepSeek-AI团队的CODEI/O范式首次让机器真正"理解"了推理的本质——它将代码执行中蕴含的逻辑流,转化为可解释、可验证的思维链条,犹如为AI装上了解剖推理过程的显微镜。

RedStone是一个高效构建大规模指定领域数据的处理管道,通过优化数据处理流程,从Common Crawl中提取了RedStone-Web、RedStone-Code、RedStone-Math和RedStone-QA等数据集,在多项任务中超越了现有开源数据集,显著提升了模型性能。

强化学习训练数据越多,模型推理能力就越强?新研究提出LIM方法,揭示提升推理能力的关键在于优化数据质量,而不是数据规模。该方法在小模型上优势尽显。从此,强化学习Scaling Law可能要被改写了!
用扩散模型替代自回归,大模型的逆诅咒有解了!

国产AI几何模型性能达IMO金牌水平,打平谷歌DeepMind最新AlphaGeometry系列——
用代码训练大模型思考,其他方面的推理能力也能提升。
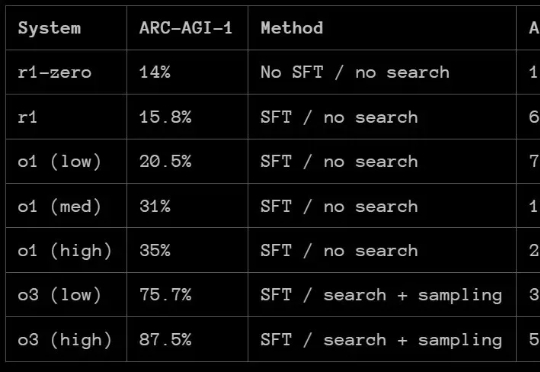
那么,DeepSeek-R1 的 ARC-AGI 成绩如何呢?根据 ARC Prize 发布的报告,R1 在 ARC-AGI-1 上的表现还赶不上 OpenAI 的 o1 系列模型,更别说 o3 系列了。但 DeepSeek-R1 也有自己的特有优势:成本低。
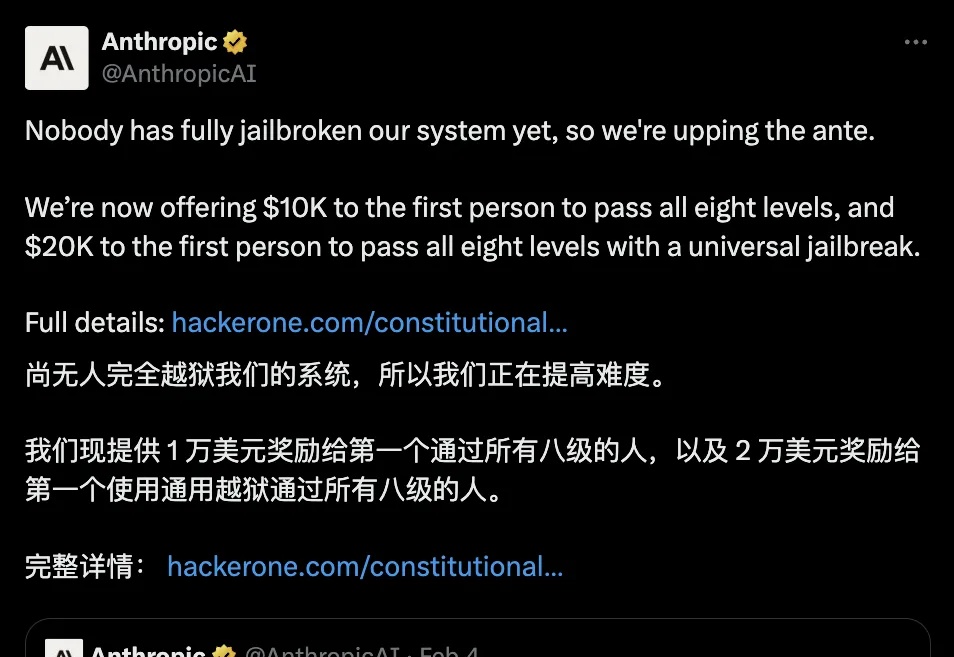
Anthropic,公布了新的AI模型防护方法,在之后约48小时内,无人完全攻破新系统,将赏金提高到了最高2万美元。新方法真这么强?

DeepSeek团队最新力作一上线,就获得Ai2研究所大牛推荐,和DeepSeek铁粉们的热情研读!他们提出的CodeI/O全新方法,通过代码提取了LLM推理模式,在逻辑、数学等推理任务上得到显著改进。
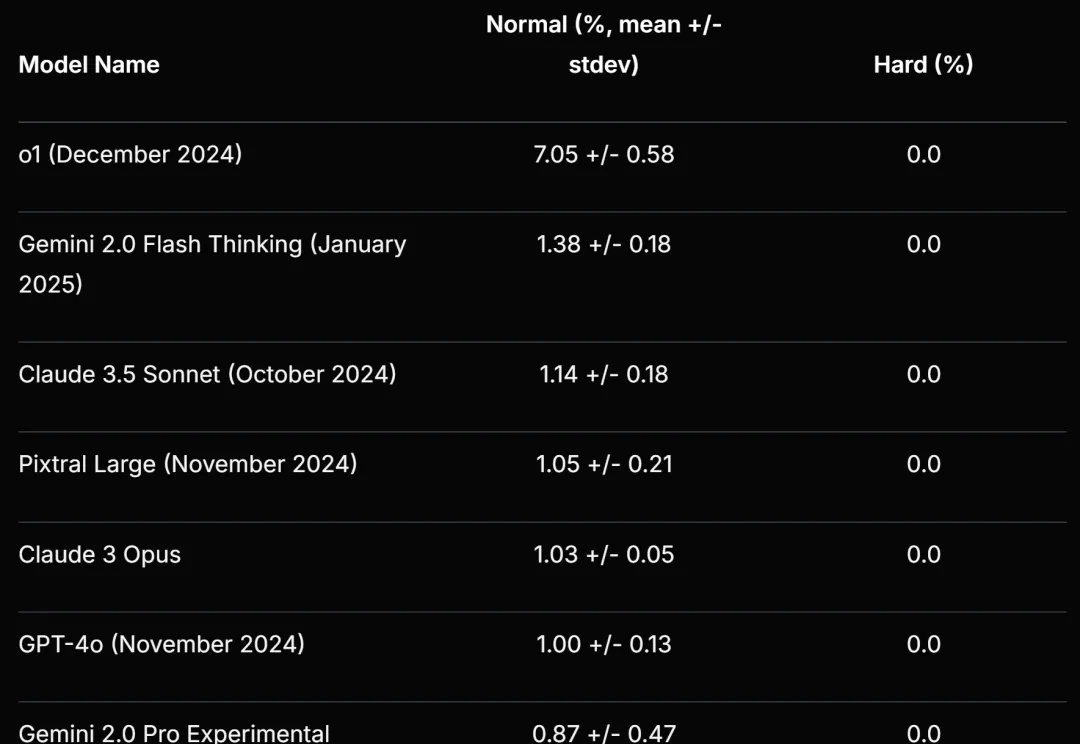
Scale AI 等提出的新基准再次暴露了大语言模型的弱点。
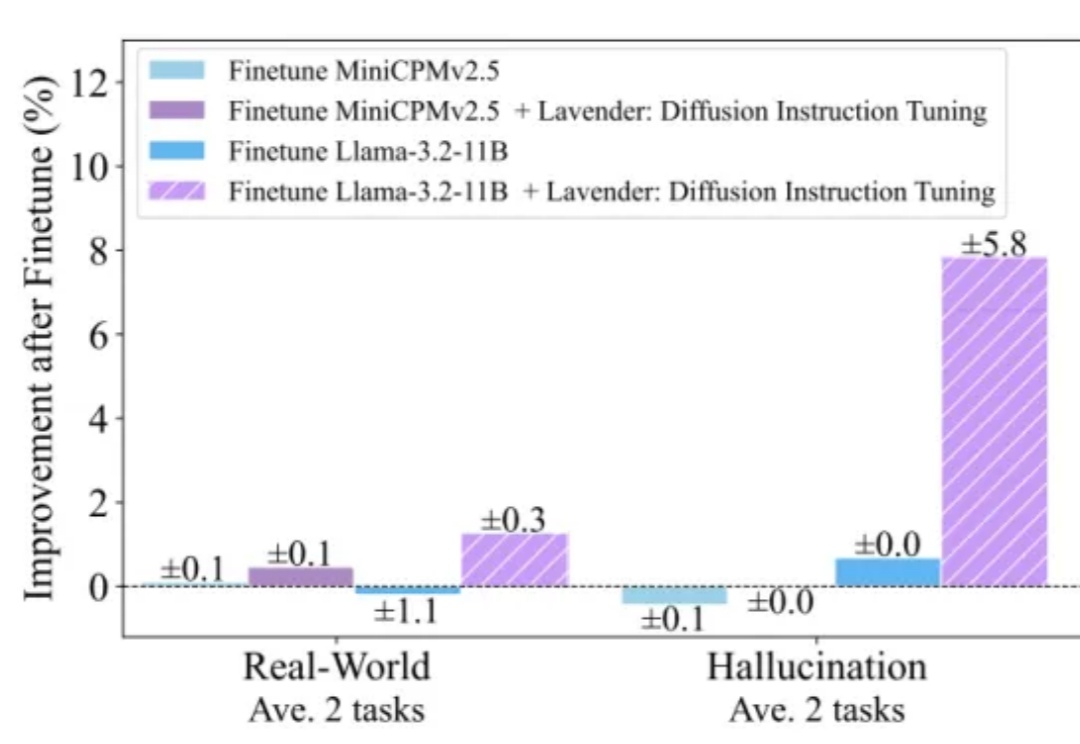
这次不是卷参数、卷算力,而是卷“跨界学习”——
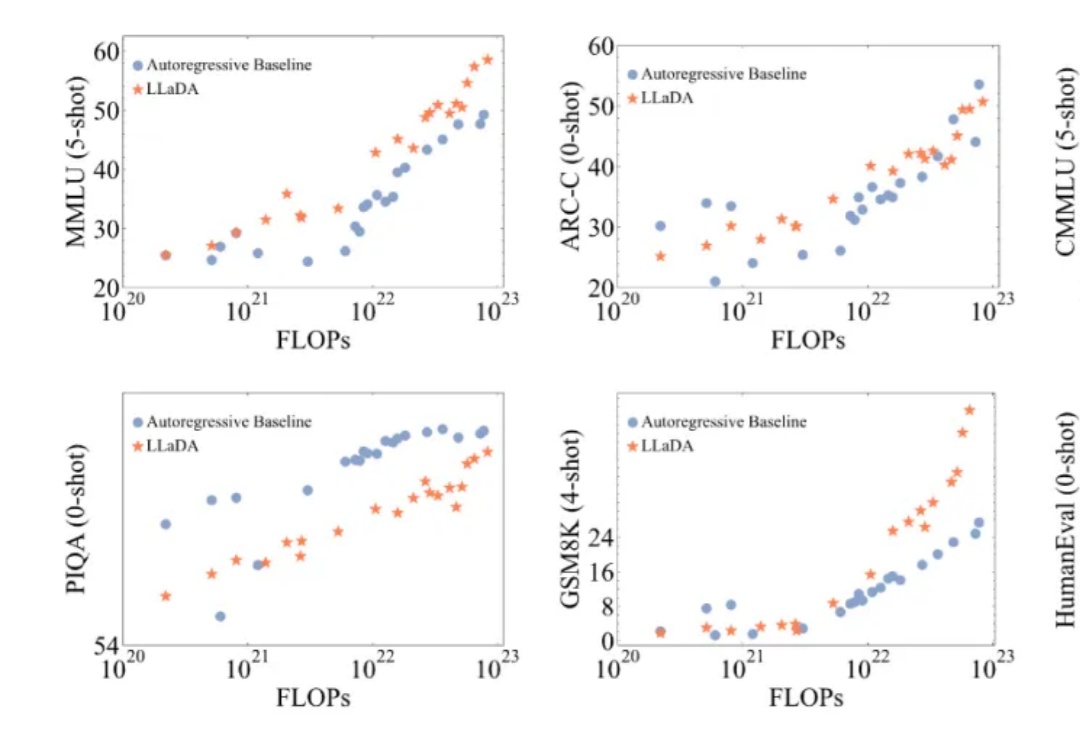
近年来,大语言模型(LLMs)取得了突破性进展,展现了诸如上下文学习、指令遵循、推理和多轮对话等能力。目前,普遍的观点认为其成功依赖于自回归模型的「next token prediction」范式。
本文的作用是帮你把问题具体化,这是用好DeepSeek-R1等推理型模型的前置步骤。

自然语言 token 代表的意思通常是表层的(例如 the 或 a 这样的功能性词汇),需要模型进行大量训练才能获得高级推理和对概念的理解能力,

AI搜索“老大哥”Perplexity,刚刚也推出了自家的Deep Research——随便给个话题,就能生成有深度的研究报告。

全球有多少AI算力?算力增长速度有多快?在这场AI「淘金热」中,都有哪些新「铲子」?AI初创企业Epoch AI发布了最新全球硬件估算报告。

英伟达巧妙地将DeepSeek-R1与推理时扩展相结合,构建了全新工作流程,自动优化生成GPU内核,取得了令人瞩目的成果。

问题挺严重,大模型说的话可不能全信。