
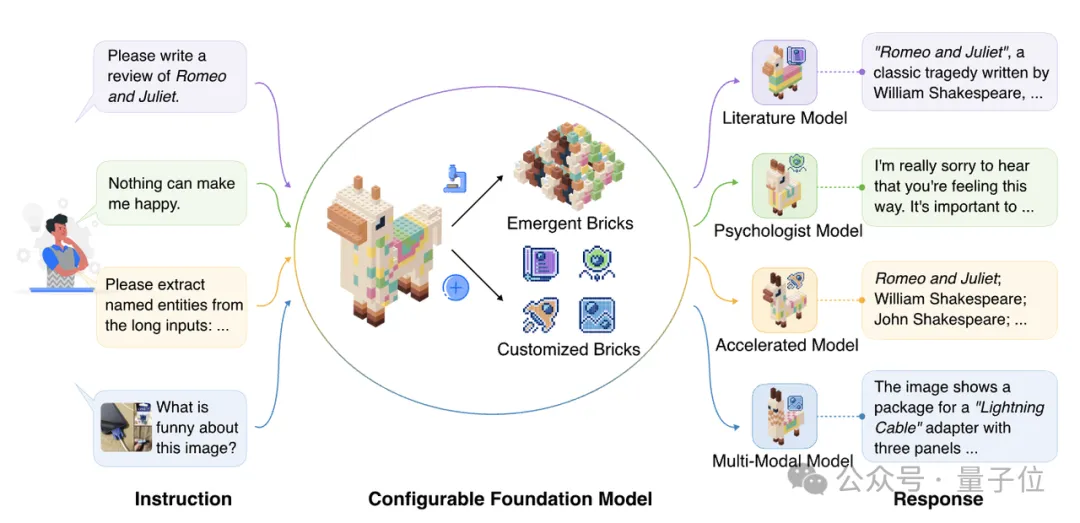
清华团队革新MoE架构!像搭积木一样构建大模型,提出新型类脑稀疏模块化架构
清华团队革新MoE架构!像搭积木一样构建大模型,提出新型类脑稀疏模块化架构探索更高效的模型架构, MoE是最具代表性的方向之一。 MoE架构的主要优势是利用稀疏激活的性质,将大模型拆解成若干功能模块,每次计算仅激活其中一小部分,而保持其余模块不被使用,从而大大降低了模型的计算与学习成本,能够在同等计算量的情况下产生性能优势。
来自主题: AI技术研报
4433 点击 2024-11-01 17:11
探索更高效的模型架构, MoE是最具代表性的方向之一。 MoE架构的主要优势是利用稀疏激活的性质,将大模型拆解成若干功能模块,每次计算仅激活其中一小部分,而保持其余模块不被使用,从而大大降低了模型的计算与学习成本,能够在同等计算量的情况下产生性能优势。

强化学习(RL)对大模型复杂推理能力提升有关键作用,然而,RL 复杂的计算流程以及现有系统局限性,也给训练和部署带来了挑战。

大模型热,企业落地难?就在刚刚,百川智能推出「1+3」产品矩阵,一站式解决大模型商业化难题。「系列优质通用数据+领域增强训练工具链」,仅需10分钟就能让企业自主成为模型定制增强专家,实现行业最佳的多场景可用率。
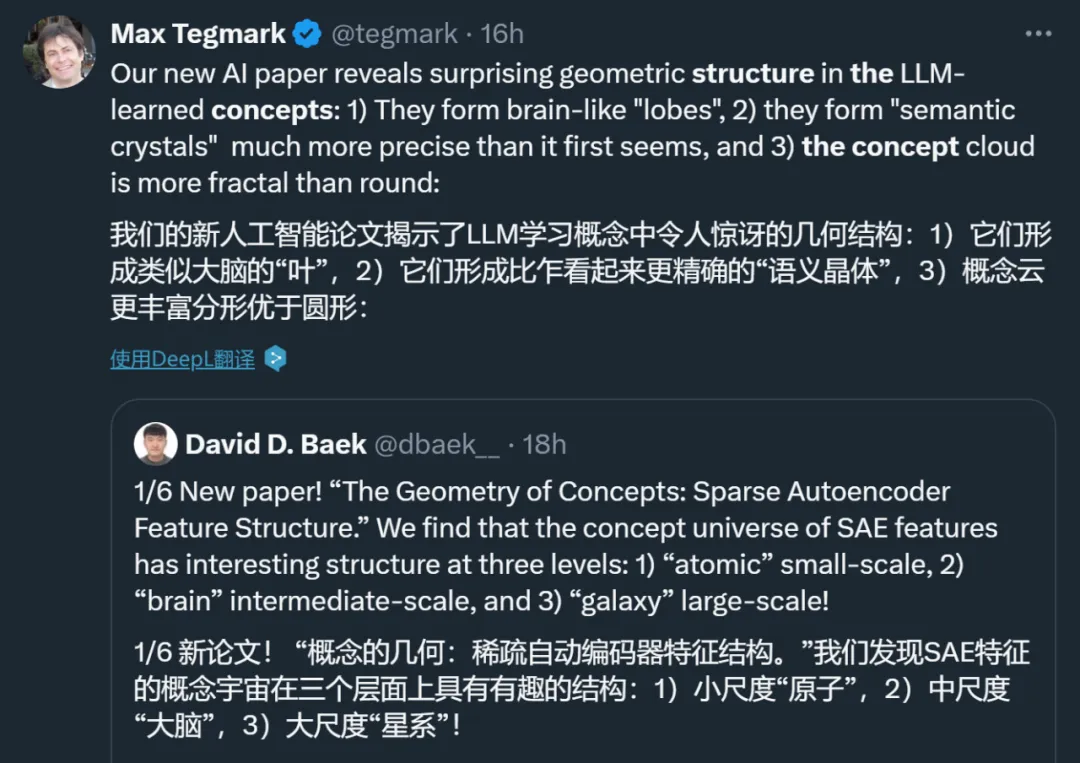
大型语言模型在学习概念时竟然会形成令人惊讶的几何结构,比如代码和数学特征会形成一个「叶(lobe)」,类似于我们在做磁共振功能成像时看到的大脑功能性脑叶。这说明什么呢?

Ferret-UI 2 是苹果研究团队最新发表的一款先进的多模态大型语言模型(MLLM),旨在实现跨多个平台的通用用户界面(UI)理解。

来自华东师范大学、南洋理工和中科院等高校的联合研究团队提出了一种新颖的人工智能教育框架“场景-对象-评估”(SOE),旨在利用大型语言模型(LLMs)构建能够模拟人类学生行为和个体差异的虚拟学生代理(LVSA)。
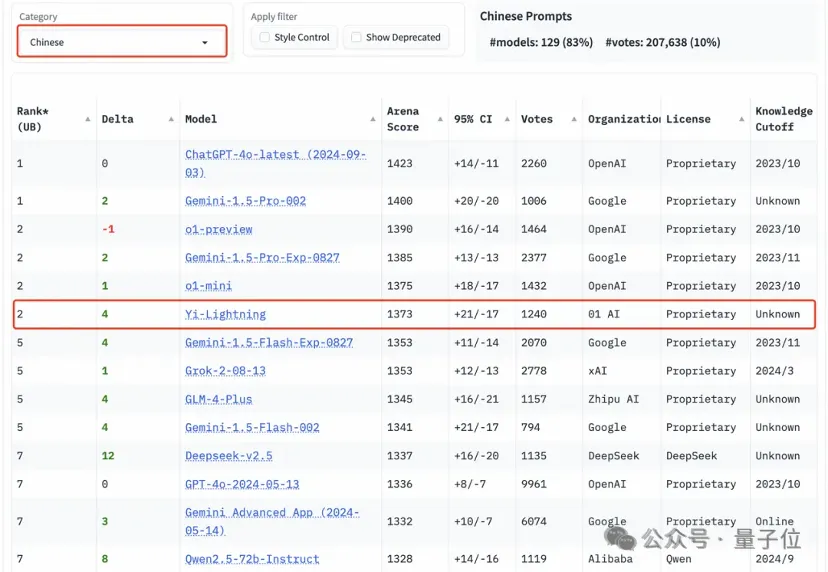
国产大模型首次在国际最具挑战的“大模型竞技场”榜单上超过GPT-4o(5月版本),当零一万物的名字紧跟在OpenAI、Google之后,李开复却如是坦言。

一个简单但具有挑战性的基准

近年来,大语言模型(Large Language Models, LLMs)的研究取得了重大进展,并对各个领域产生了深远影响。然而,LLMs的卓越性能来源于海量数据的大规模训练,这导致LLMs的训练成本明显高于传统模型。

上周Anthropic发布了Claude 3.5 Sonnet的升级,让AI助手能够通过"电脑使用"功能直接与计算机交互。