
天工所打造!国内首个生物制造大语言模型,网页版已上线!
天工所打造!国内首个生物制造大语言模型,网页版已上线!当前,传统生物制造方法在知识整合、数据处理和实验设计方面面临诸多挑战,限制了其在工业化应用中的效率和可扩展性。
来自主题: AI技术研报
11360 点击 2025-03-24 10:41
 搜索
搜索
当前,传统生物制造方法在知识整合、数据处理和实验设计方面面临诸多挑战,限制了其在工业化应用中的效率和可扩展性。

3月20日,丹麦制药巨头诺和诺德执行副总裁兼首席科学官Marcus Schindler在Linkedin发布了关于诺和诺德的研发组织架构调整的消息。Marcus Schindler还提到,大数据和人工智能将成为我们科学工作的核心,使我们能够加深对疾病的理解并做出明智的决定。这些变化不仅使我们能够快速创新,而且还缩短了从不确定到确定的路径,减少了周期时间和成本,同时增加了我们成功的可能性。

华人学者、斯坦福大学副教授 James Zou 领导的团队提出了 TextGrad ,通过文本自动化“微分”反向传播大语言模型(LLM)文本反馈来优化 AI 系统。只需几行代码,你就可以自动将用于分类数据的“逐步推理”提示转换为一个更复杂的、针对特定应用的提示。
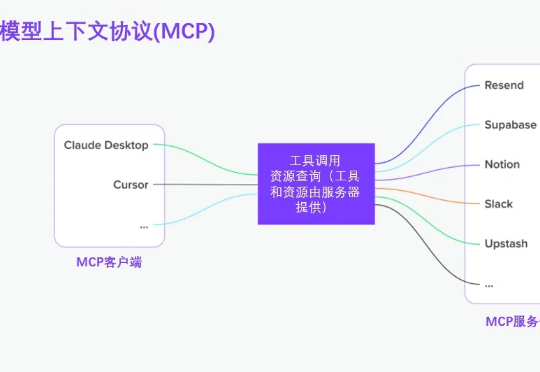
自 2023年OpenAI发布函数调用功能以来,我一直在思考如何开启智能体和工具使用的生态系统。随着基础模型变得越来越智能,智能体与外部工具、数据和API交互的能力却日益碎片化:开发人员需要为智能体运行和集成的每个系统都实现具有特殊业务逻辑的智能体。

在虚拟现实、游戏以及 3D 内容创作领域,从单张图像重建高保真且可动画的全身 3D 人体一直是一个极具挑战性的问题:人体多样性、姿势复杂性、数据稀缺性等等。

Anthropic终于为Claude解锁了网络搜索功能,这一姗姗来迟的升级让它从「数据截止」的限制中解放出来,网友泪目欢呼雀跃!现在,Claude不仅能实时获取网络资讯,还能在回答中附上来源,实用性大幅提升。

就在刚刚,OpenAI 宣布在其 API 中推出全新一代音频模型,包括语音转文本和文本转语音功能,让开发者能够轻松构建强大的语音 Agent。据 OpenAI 介绍,新推出的 gpt-4o-transcribe 采用多样化、高质量音频数据集进行了长时间的训练,能更好地捕获语音细微差别,减少误识别,大幅提升转录可靠性。

当我们看到一张猫咪照片时,大脑自然就能识别「这是一只猫」。但对计算机来说,它看到的是一个巨大的数字矩阵 —— 假设是一张 1000×1000 像素的彩色图片,实际上是一个包含 300 万个数字的数据集(1000×1000×3 个颜色通道)。每个数字代表一个像素点的颜色深浅,从 0 到 255。

AI说:“我懂你”,然后转头写进大数据。

当今世界,人们都在谈论生成式人工智能。全世界都知道所有最新的GenAI概念和术语——因此,你会比以往听到更多这样的话:“这个词不等于token”。全世界都开始实施至少一个或两个GenAI用例,当然——我引用它的意思是“改变生活”。