# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
对于人类而言,一旦掌握了 “打开瓶盖” 的动作,面对 “拧紧螺丝” 这样的任务通常也能游刃有余,因为这两者依赖于相似的手部动作。然而,对于机器人来说,即使是这样看似简单的任务转换依然充满挑战。例如,换成另一种类型的瓶盖,机器人可能无法成功打开。这表明,目前的机器人方法尚未充分让模型学习到任务的内在执行逻辑,而只是单纯的依赖于数据拟合。
针对该问题,来自中山大学和华为诺亚等单位的研究团队提出了一种全新的原语驱动的路径点感知世界模型,借助 VLMs 作为机器人的大脑,理解任务之间的动作关联性,并通过 “世界模型” 获取对未来动作的表征,从而更好地帮助机器人学习和决策。该方法显著提升了机器人的学习能力,并保持良好的泛化性。

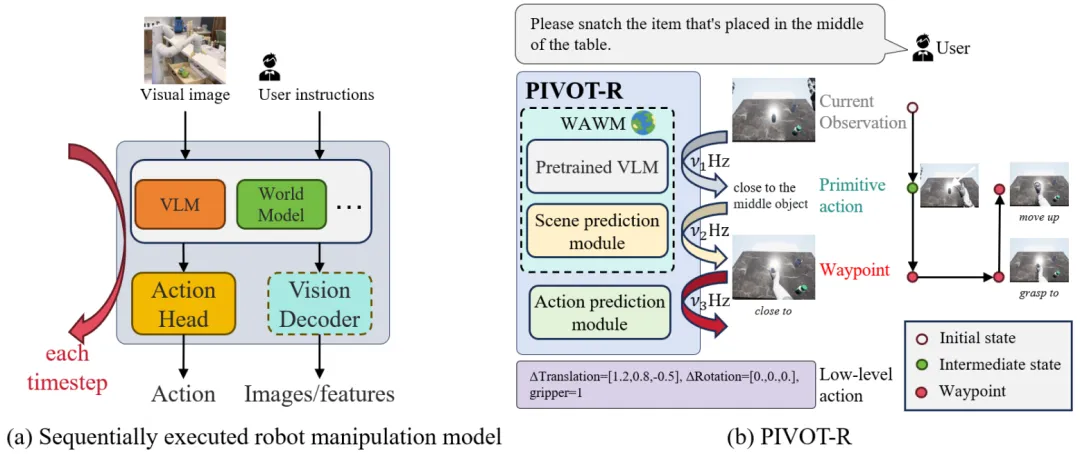
当前,现有机器人操作任务有两个关键问题:
为了解决上述问题,研究团队提出了 PIVOT-R,一种原语驱动的路径点感知世界模型。如上图所示,对比左图现有的方法,右图展示了 PIVOT-R 通过关注与任务相关的路径点预测,提升机器人操作的准确性,并设计了一个异步分层执行器,降低计算冗余,提升模型的执行效率。
这样做有几个好处:
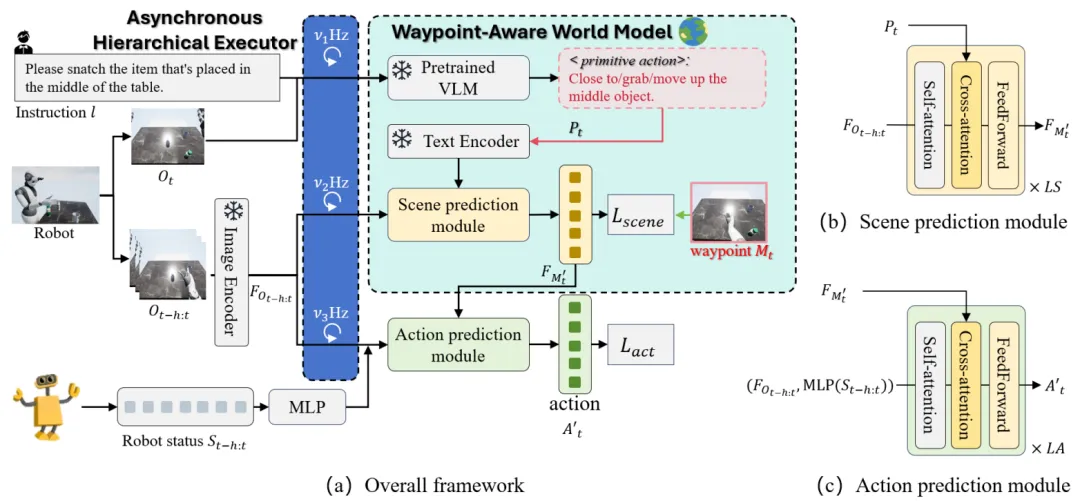
原语动作解析
PIVOT-R 的第一个核心步骤是原语动作解析,这一步通过预训练的视觉 - 语言模型(VLM)来解析用户的语言指令。VLM 可以将复杂的自然语言指令转换为一组简单的原语动作,例如 “靠近”、“抓取”、“移动” 等。这些原语动作为机器人提供了操作任务的粗略路径。
具体流程如下:
路径点预测
在原语动作解析后,PIVOT-R 的下一步是路径点预测。路径点代表了机器人操控过程中一些关键的中间状态,例如靠近物体、抓取物体、移动物体等。通过预测路径点,PIVOT-R 能够在机器人执行任务时提供明确的操作指导。具体来说,通过一个 Transformer 架构的模型,预测路径点对应的视觉特征,为后续的动作预测模块提供指引。
动作预测模块
动作预测模块负责根据预测的路径点生成具体的低层次机器人动作。它以路径点为提示,结合机器人历史状态(如位置、姿态等),计算下一步应该执行的动作。该模块使用轻量级的 Transformer 架构进行动作预测,确保计算效率和性能的平衡。这一模块的设计重点在于低延迟和高精度执行操控任务。
异步分层执行器
此外,PIVOT-R 还引入了一个关键的执行机制,即异步分层执行器。与以往的机器人模型不同,PIVOT-R 并不对所有模块在每一步都进行同步更新,而是为不同模块设置了不同的执行频率,以多线程的方式进行异步更新,从而提升执行速度。
实验
作者在具有复杂指令的 SeaWave 仿真环境和真实环境下进行实验。
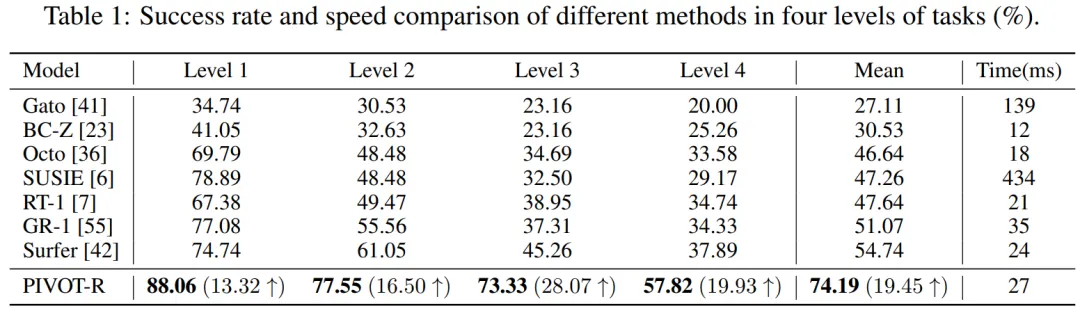
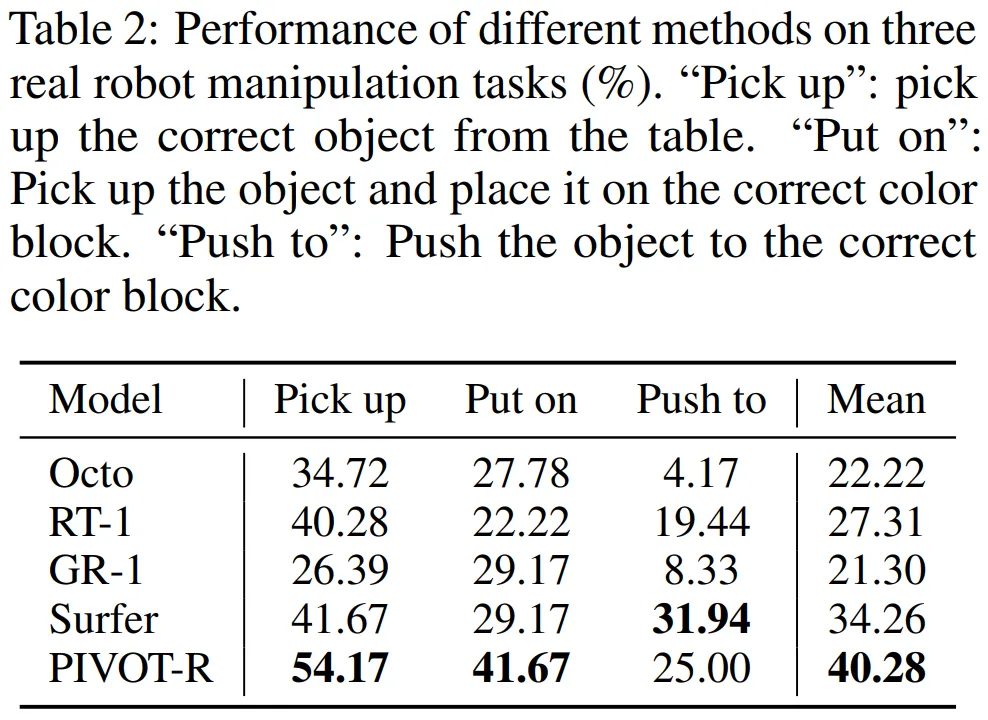
如 Table 1 和 Table 2 所示,PIVOT-R 在仿真环境和真实环境都取得了最优的效果,同时,模型的速度和 RT-1 等方法速度相近,没有因为使用大模型而导致速度变慢。
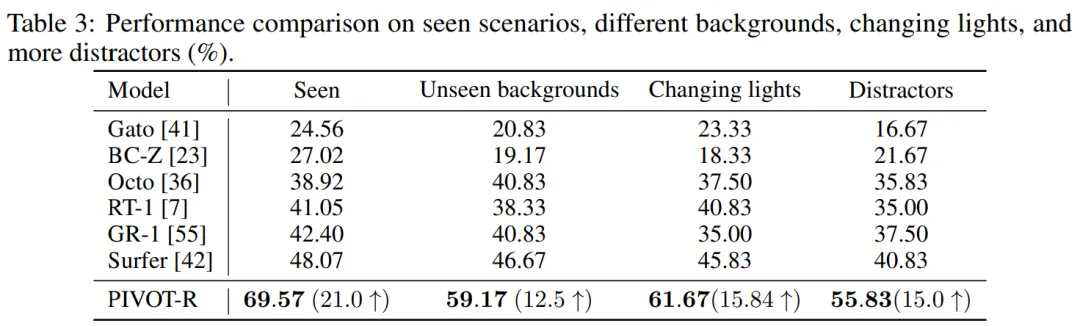
作者也在 SeaWave 上做了泛化性测试,在三种泛化性测试场景下,PIVOT-R 仍保持远高于其他模型的成功率。
研究总结
PIVOT-R 通过引入原语动作驱动的路径点感知,显著提升了机器人在复杂操控任务中的性能。该模型不仅在执行效率上具备优势,还能够更好地应对复杂、多变的环境。该方法在仿真环境和真实环境操纵下表现优异,为机器人学习提供了一个新范式。
文章来自于“机器之心”,作者“机器之心”。




