
AI时代里的中国故事:从零基础到万亿规模
AI时代里的中国故事:从零基础到万亿规模AI的故事,始于1956年。在那年夏天达特茅斯学院的会议中,人工智能的概念被第一次提出。大洋彼岸的1956年,“向科学进军”的号召发出,为中国的半导体、自动化、计算技术、原子能、电子学、航空和火箭技术等新兴科学技术奠定了基础。
来自主题: AI资讯
3991 点击 2024-10-01 14:21
 搜索
搜索
AI的故事,始于1956年。在那年夏天达特茅斯学院的会议中,人工智能的概念被第一次提出。大洋彼岸的1956年,“向科学进军”的号召发出,为中国的半导体、自动化、计算技术、原子能、电子学、航空和火箭技术等新兴科学技术奠定了基础。
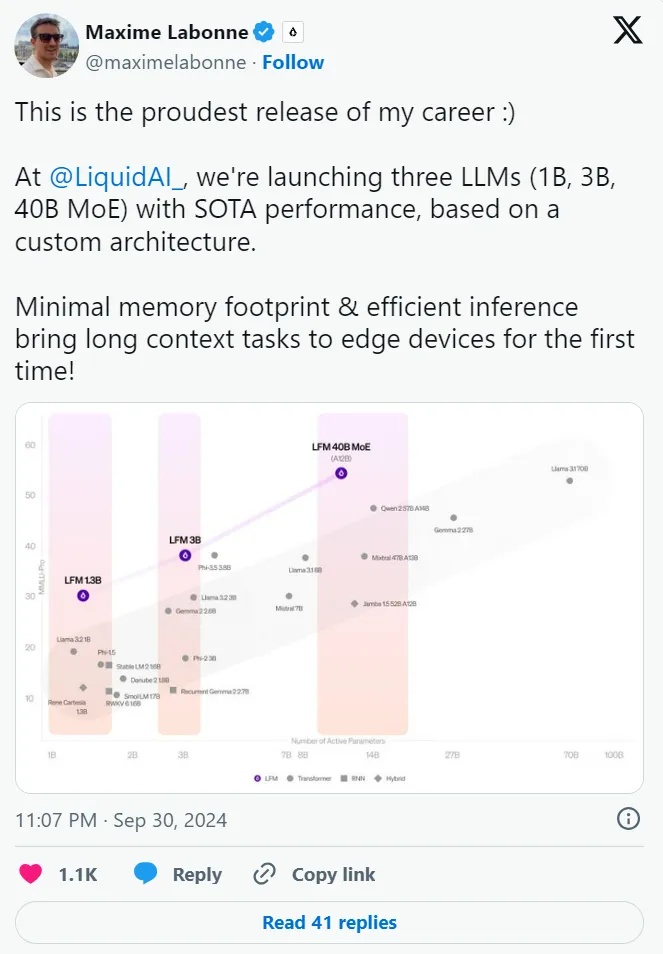
一个受线虫启发的全新架构,三大「杯型」均能实现 SOTA 性能,资源高度受限环境也能部署。移动机器人可能更需要一个虫子的大脑。

AI大模型的加速发展,催化了国产人形机器人陆续走出实验室,让量产成为人形机器人新的关键词。

去年,OpenAI在旧金山举办了一场引发业界轰动的开发者大会(DevDay 2023),推出了一系列新产品和工具,包括支持128K上下文的GPT-4 Turbo,API价格下调,新的Assistants API,具备视觉功能的GPT-4 Turbo,DALL·E 3 API,以及大幅改进的JSON模型,还有命运多舛的GPTs和类App Store平台GPT Store。

这两天有个很神奇的现象,就是有两个从来不碰A股的小伙伴,竟然跑过来问我——“现在上车A股还有机会吗?”

今年2月Sora问世后,放出了几段文生视频的片段,给全世界不小的震撼,仅需要一些提示词描述或者静态图片,Sora就能生成超高画质、堪比电影质感长达1分钟的视频内容。马斯克更是直截了当地说:“GG human(人类认输)。”

大语言模型(Large Language Models, LLMs)的强大能力推动了 LLM Agent 的迅速发展。围绕增强 LLM Agent 的能力,近期相关研究提出了若干关键组件或工作流。然而,如何将核心要素集成到一个统一的框架中,能够进行端到端优化,仍然是一个亟待解决的问题。

近日,北京大学陈宝权教授在第九届计算机图形学与混合现实研讨会(GAMES 2024)上,发表了题为《从图形计算到世界模型》的主旨报告,分享了他从图形仿真角度对世界模型的思考。本文是对陈教授报告的完整整理,以供大家学习。
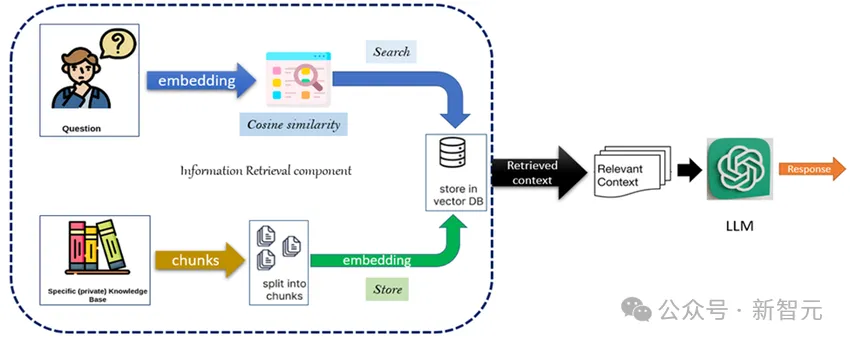
曾几何时,LLM还是憨憨的。 脑子里的知识比较混乱,同时上下文窗口长度也有限。 检索增强生成(RAG)的出现在很大程度上提升了模型的性能。

中科大成果,拿下图学习“世界杯”单项冠军! 由中科大王杰教授团队(MIRA Lab)提出的首个具有最优性保证的大语言模型和图神经网络分离训练框架,在国际顶级图学习标准OGB(Open Graph Benchmark)挑战赛的蛋白质功能预测任务上斩获「第一名」,该纪录从2023年9月27日起保持至今。