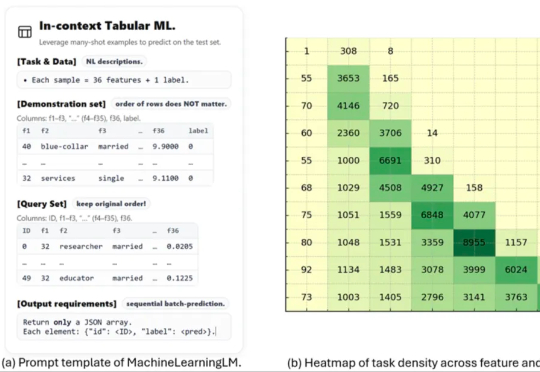
网络顶会获奖!华为提出端网协同RDMA传输架构,解决大规模AI集群网络可扩展性问题
网络顶会获奖!华为提出端网协同RDMA传输架构,解决大规模AI集群网络可扩展性问题近日,全球网络通信顶会 ACM SIGCOMM 2025 在葡萄牙落幕,共 3 篇论文获奖,华为网络技术实验室与香港科技大学 iSING Lab 合作的 DCP 研究成果,获本届大会 Best Student Paper Award (Honorable Mention),成为亚洲地域唯一获奖的论文。
来自主题: AI资讯
8609 点击 2025-09-17 09:41