Harness is the New Dataset:模型智能提升的下一个关键方向
Harness is the New Dataset:模型智能提升的下一个关键方向最近,harness engineering 又成了继 prompt engineering、context engineering 之后新一代的 buzzword。
来自主题: AI技术研报
8255 点击 2026-03-30 09:55
 搜索
搜索
最近,harness engineering 又成了继 prompt engineering、context engineering 之后新一代的 buzzword。

新一代代码模型的训练动态已与旧模型截然不同,主流强化学习方法和数据集在其上几乎“失效”。
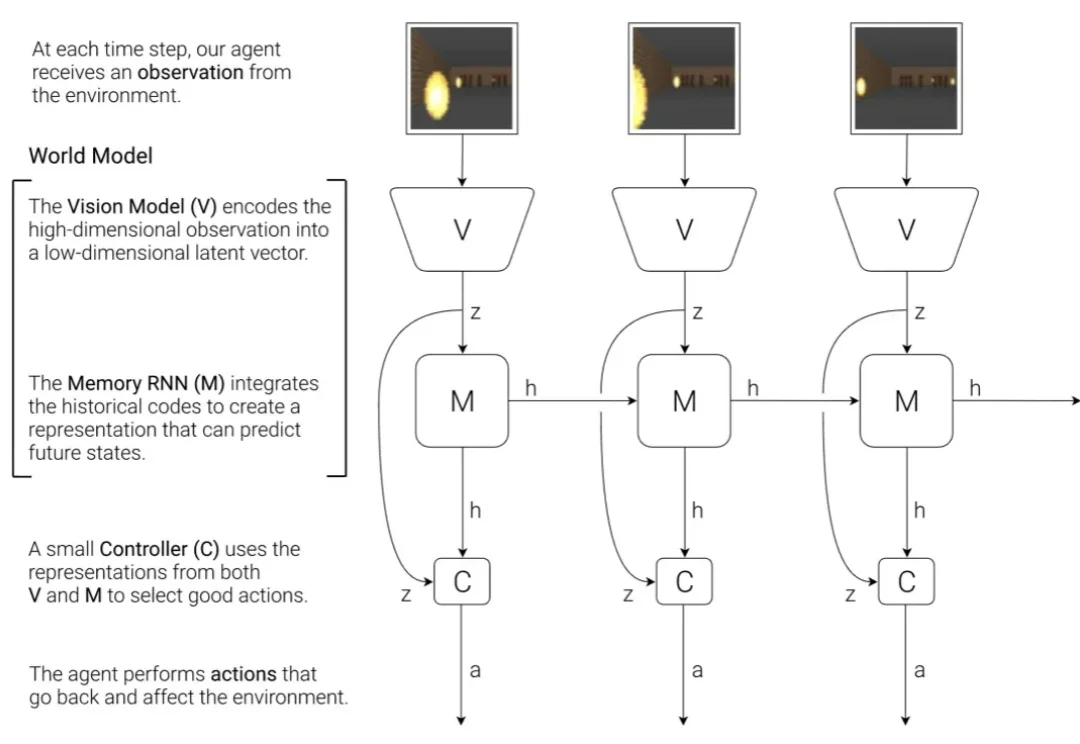
当世界模型越来越大,真正制约它走向「内部模拟器」的,未必是表征能力,而可能是动力学建模。
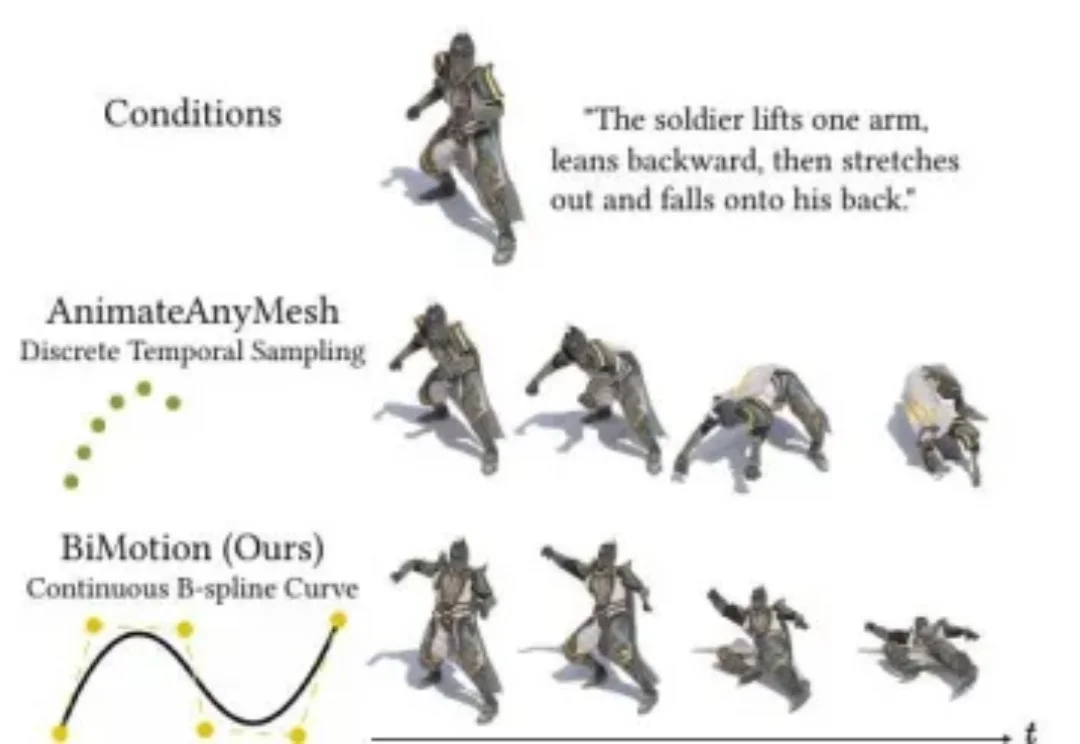
当你希望 AI 将 "士兵举起手臂,向后倾身,然后身体向前扑倒" 这段文字转化为一段 3D 角色动画,现有大多数方法给出的答案是:一段摇摇晃晃、语义残缺的短片段。这并非模型能力不足,问题的根源在于将运动表达为逐帧离散序列这一根本性的设计决策。
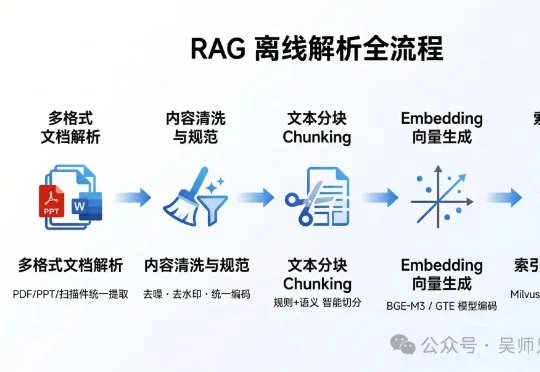
大家好,我是吴师兄。 之前有个学员面阿里的 NLP 岗,简历上写着"搭建了基于 RAG 的企业知识问答系统"。面试官翻着简历问: "你们知识库有多少文档?什么格式?" 他说:"大概 5000 份,PD
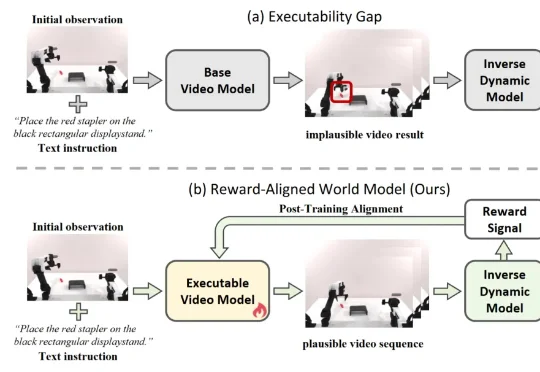
近期,利用视频生成模型为机器人构建 “世界模型”,已成为具身智能领域的热门技术路线。给定当前观测和自然语言指令,这类模型能够先 “想象” 出未来的视觉轨迹,再由逆动力学模型(IDM)将生成画面解码为机器人动作,从而形成 “先预测、后执行” 的解耦式规划范式。由于兼具较强的可解释性与开放场景泛化潜力,这一路线正在受到学术界和工业界的广泛关注。
硅心科技(aiXcoder)发布了一款专为「代码变更应用」场景设计的高性能、轻量级模型 aiX-apply-4B。基准测试结果显示,在 20 多种主流编程语言及 Markdown 等多类型文件格式的测试中,aiX-apply-4B 的平均准确率达到 93.8%,超越 Qwen3-4B 基座模型 62.6% 的准确度
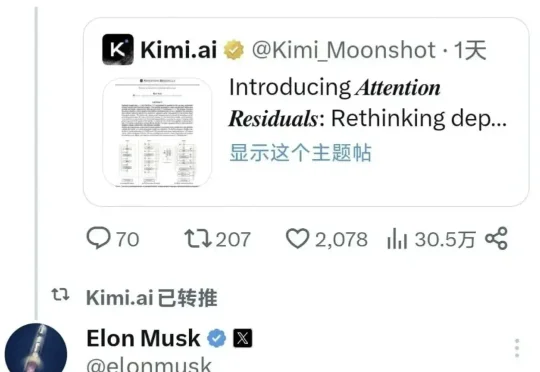
前几天,一篇来自Kimi的论文「ATTENTION RESIDUALS」在 AI 圈引发了激烈讨论——马斯克罕见地发出评价:"Impressive work from Kimi"。同时,两位前Openai大佬也同样发出了高度评价,OpenAI 「推理模型之父」Jerry Tworek表示“深度学习2.0时代即将到来”。
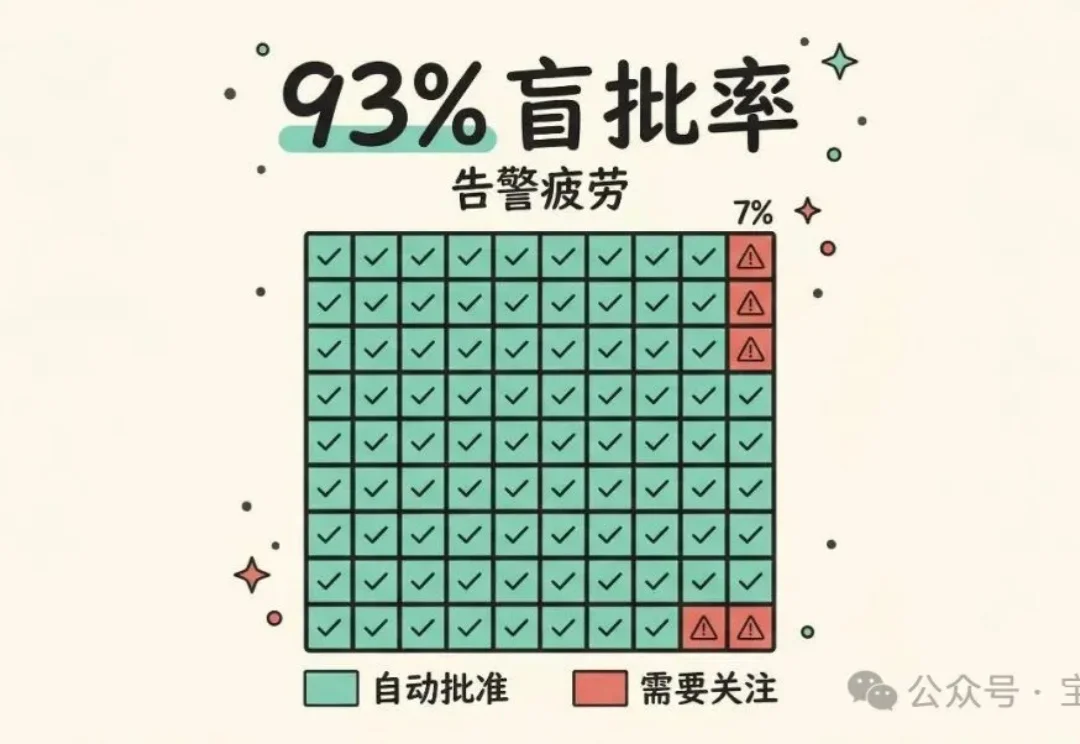
用 Claude Code 写代码的人都熟悉一个场景:Claude 每执行一个命令、每改一个文件,都要你点一次“同意”。Anthropic 的数据显示,用户 93% 的操作都会批准。也就是说,这个“安全审批”环节,绝大多数时候只是一个条件反射。

能无限进步的「超级智能体」来了!