
多图场景用DPO对齐!上海AI实验室等提出新方法,无需人工标注
多图场景用DPO对齐!上海AI实验室等提出新方法,无需人工标注多图像场景也能用DPO方法来对齐了! 由上海交大、上海AI实验室、港中文等带来最新成果MIA-DPO。 这是一个面向大型视觉语言模型的多图像增强的偏好对齐方法。
来自主题: AI技术研报
5947 点击 2024-11-01 20:53
 搜索
搜索
多图像场景也能用DPO方法来对齐了! 由上海交大、上海AI实验室、港中文等带来最新成果MIA-DPO。 这是一个面向大型视觉语言模型的多图像增强的偏好对齐方法。
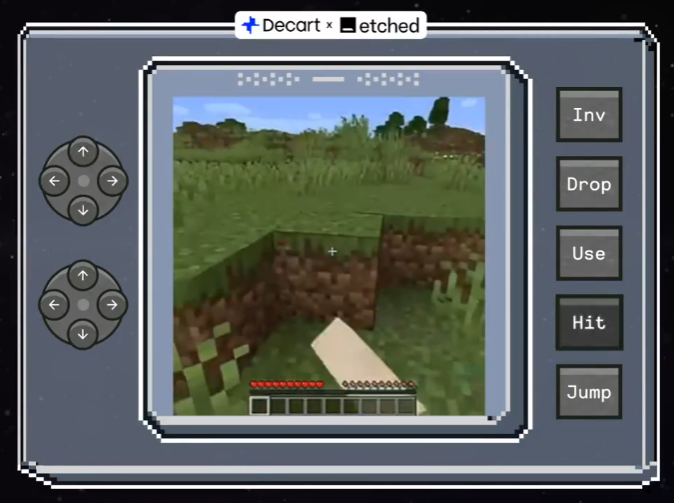
现在,一个大模型就能直接拿来当游戏,还是开放世界的那种! 可以直接根据玩家操作预测下一帧,连游戏引擎都省了。 这个怎么看都像是《我的世界》的界面,就是这款游戏Oasis本尊了。
探索更高效的模型架构, MoE是最具代表性的方向之一。 MoE架构的主要优势是利用稀疏激活的性质,将大模型拆解成若干功能模块,每次计算仅激活其中一小部分,而保持其余模块不被使用,从而大大降低了模型的计算与学习成本,能够在同等计算量的情况下产生性能优势。

CGPO框架通过混合评审机制和约束优化器,有效解决了RLHF在多任务学习中的奖励欺骗和多目标优化问题,显著提升了语言模型在多任务环境中的表现。CGPO的设计为未来多任务学习提供了新的优化路径,有望进一步提升大型语言模型的效能和稳定性。

强化学习(RL)对大模型复杂推理能力提升有关键作用,然而,RL 复杂的计算流程以及现有系统局限性,也给训练和部署带来了挑战。

大模型热,企业落地难?就在刚刚,百川智能推出「1+3」产品矩阵,一站式解决大模型商业化难题。「系列优质通用数据+领域增强训练工具链」,仅需10分钟就能让企业自主成为模型定制增强专家,实现行业最佳的多场景可用率。

对于人类而言,一旦掌握了 “打开瓶盖” 的动作,面对 “拧紧螺丝” 这样的任务通常也能游刃有余,因为这两者依赖于相似的手部动作。然而,对于机器人来说,即使是这样看似简单的任务转换依然充满挑战。例如,换成另一种类型的瓶盖,机器人可能无法成功打开。这表明,目前的机器人方法尚未充分让模型学习到任务的内在执行逻辑,而只是单纯的依赖于数据拟合。
大型语言模型在学习概念时竟然会形成令人惊讶的几何结构,比如代码和数学特征会形成一个「叶(lobe)」,类似于我们在做磁共振功能成像时看到的大脑功能性脑叶。这说明什么呢?

在奖励中减去平均奖励

Unbounded 是由 Google 研发的一个创新的角色模拟生成性无限游戏,它通过采用最新的生成模型技术,突破了传统视频游戏的局限。