
Ai陪伴调研整理(20250221)
Ai陪伴调研整理(20250221)其实,这个话题我也不好意思开口,去年7月的时候我就关注过这个 AI情趣娃娃;在具身智能发展成熟时,表情陪伴人形机器人有望成为主流产品形态。表情陪伴人形机器人属情绪陪伴机器人高端领域,指的是硅胶皮肤覆盖,根据仿生学原理模仿人的外观设计、能够与人类进行自然交互的人形机器人。
来自主题: AI技术研报
10466 点击 2025-02-25 09:49
其实,这个话题我也不好意思开口,去年7月的时候我就关注过这个 AI情趣娃娃;在具身智能发展成熟时,表情陪伴人形机器人有望成为主流产品形态。表情陪伴人形机器人属情绪陪伴机器人高端领域,指的是硅胶皮肤覆盖,根据仿生学原理模仿人的外观设计、能够与人类进行自然交互的人形机器人。
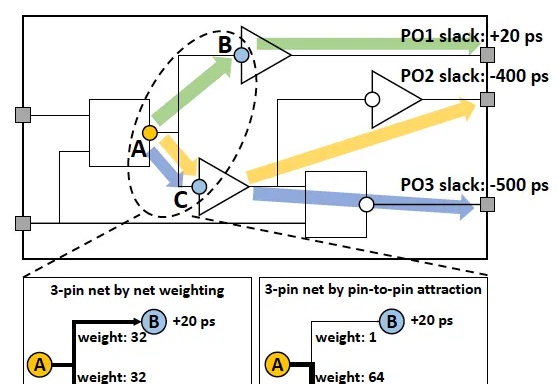
南大AI学院钱超教授团队,荣获EDA顶会2025最佳论文奖!其中,论文一作、四作、五作都是南大人工智能学院的本硕博生。芯片设计领域的传统难题——如何为多达百亿量级晶体管设计最优布局,从此有了一种巧妙的全新方法。
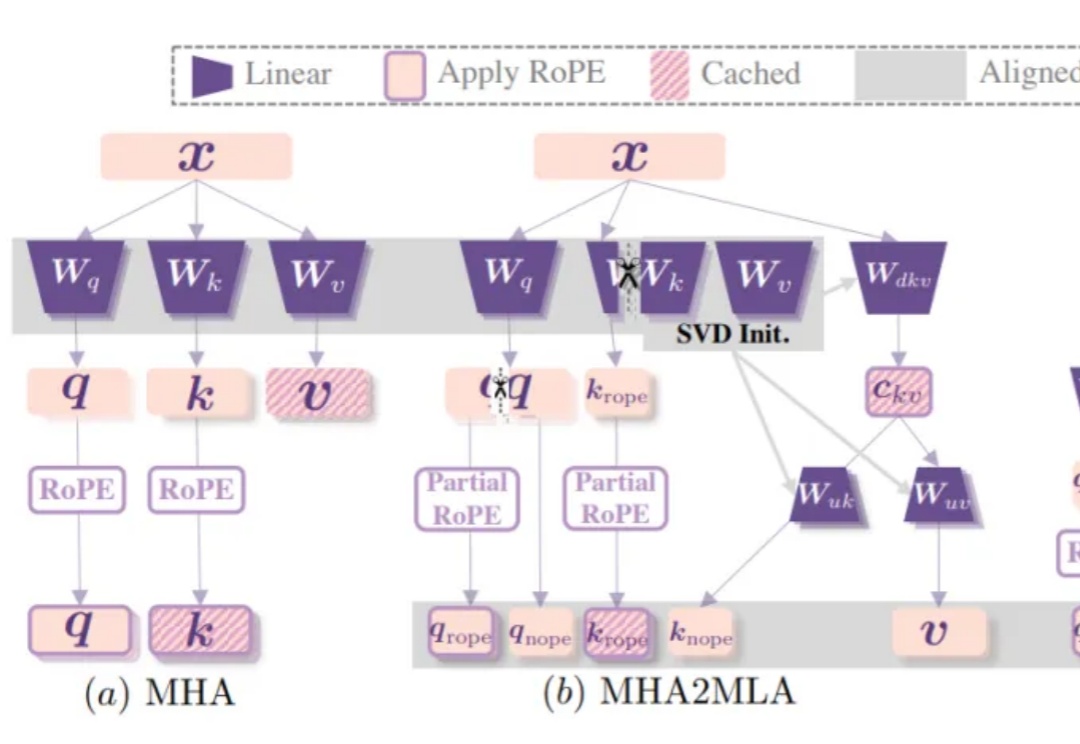
DeepSeek-R1背后关键——多头潜在注意力机制(MLA),现在也能轻松移植到其他模型了!

你能想象判别模型也能成为强大的图像合成高手吗?「直接上升合成」(DAS)做到了!它突破传统认知,借助多分辨率优化等创新技术,在图像生成的多个关键任务中表现出色。
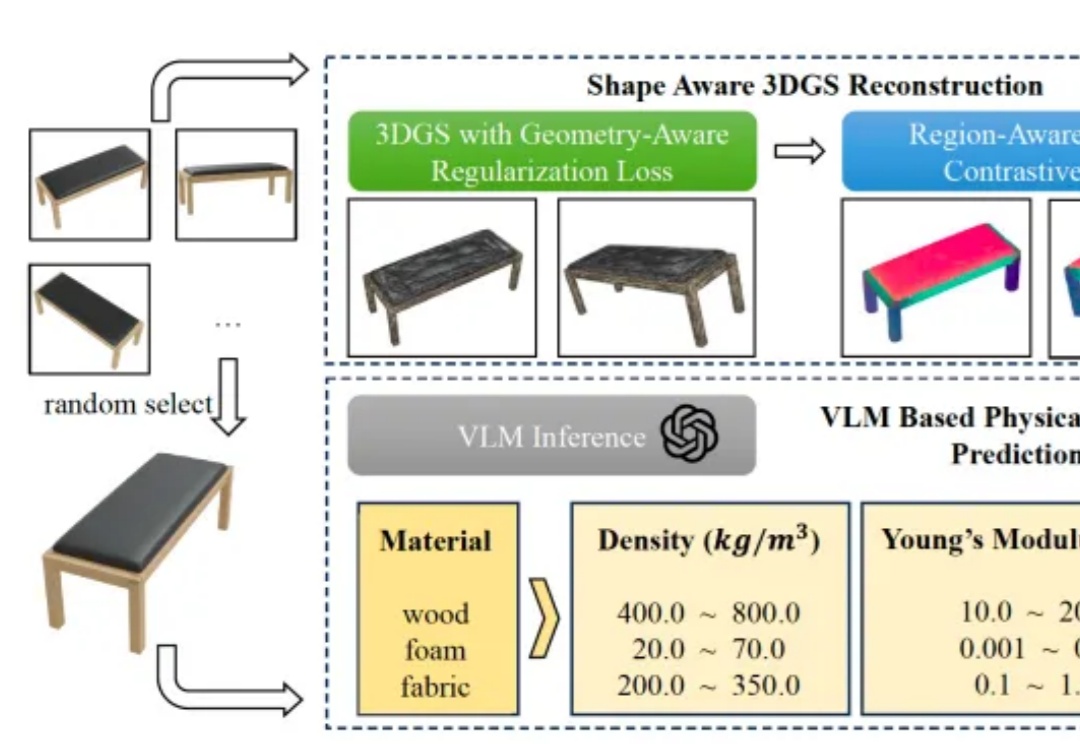
理解物体的物理属性,对机器人执行操作十分重要,但是应该如何实现呢?
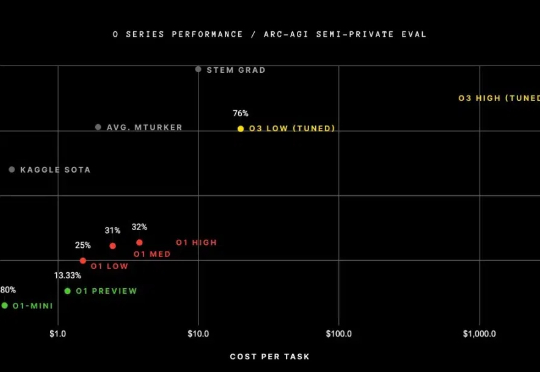
自 OpenAI 发布 o1-mini 模型以来,推理模型就一直是 AI 社区的热门话题,而春节前面世的开放式推理模型 DeepSeek-R1 更是让推理模型的热度达到了前所未有的高峰。
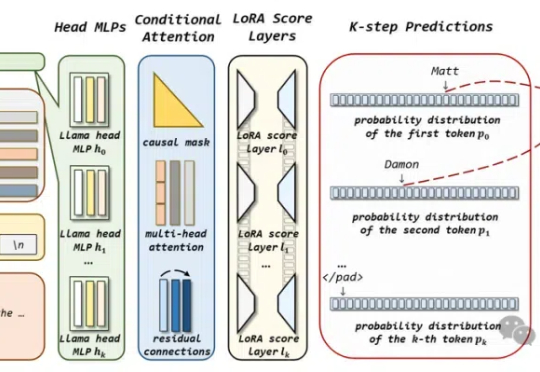
如何让大模型感知知识图谱知识?

省一半算力跑出2倍效果,月之暗面开源优化器Muon,同预算下全面领先。

国内芯片设计研究团队,刚刚在国际学术顶会上获奖了。

最近,扩散模型在生成模型领域异军突起,凭借其独特的生成机制在图像生成方面大放异彩,尤其在处理高维复杂数据时优势明显。然而,尽管扩散模型在图像生成任务中表现优异,但在图像目标移除任务中仍然面临诸多挑战。现有方法在移除前景目标后,可能会留下残影或伪影,难以实现与背景的自然融合。
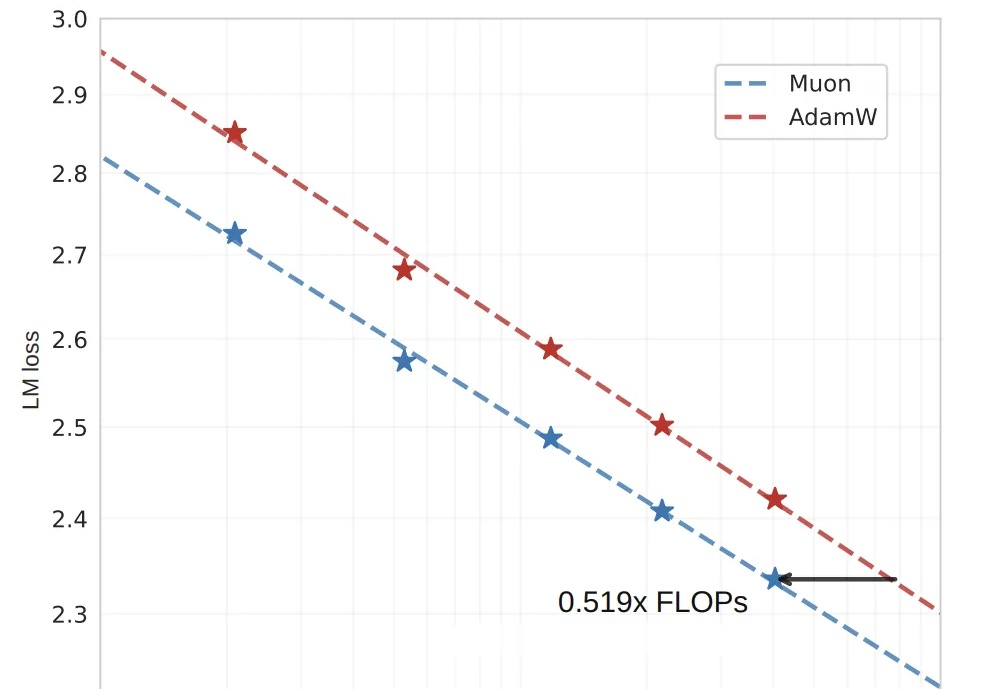
算力需求比AdamW直降48%,OpenAI技术人员提出的训练优化算法Muon,被月之暗面团队又推进了一步!

随着AI工具越来越普及,类似Deep Researh这样的工具越来越好用,科学研究成果呈现爆炸式增长。以arXiv为例,仅2024年10月就收到超过24,000篇论文提交。
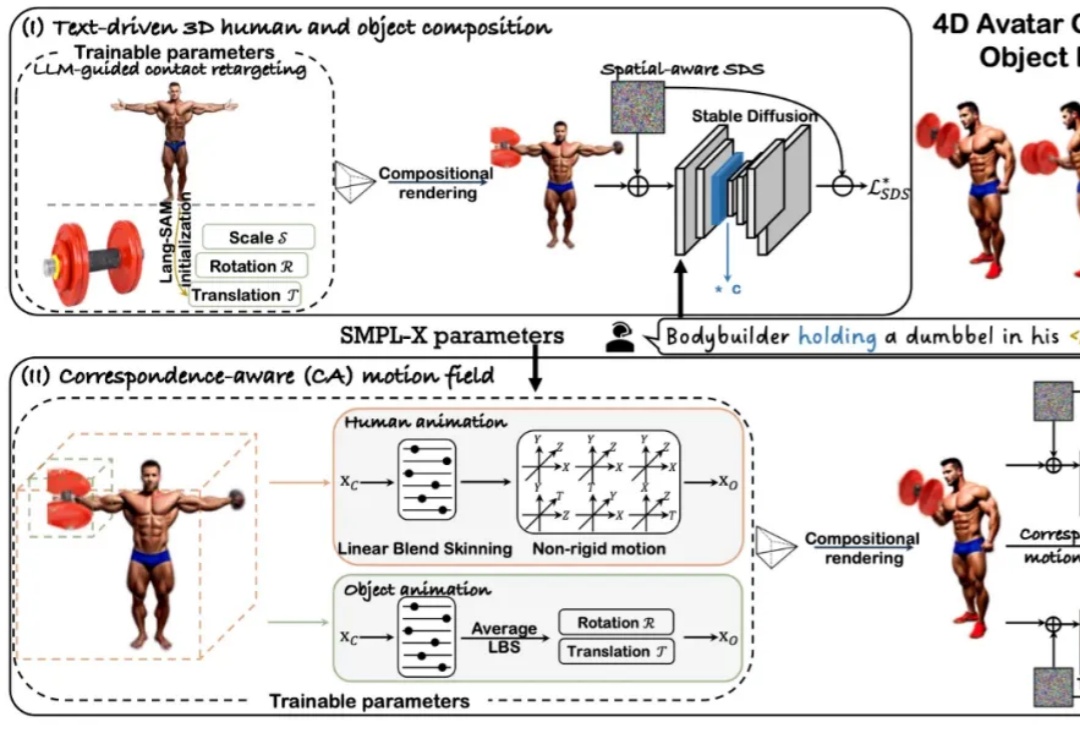
近年来,随着扩散模型和 Transformer 技术的快速发展,4D 人体 - 物体交互(HOI)的生成与驱动效果取得了显著进展。然而,当前主流方法仍依赖 SMPL [1] 这一人体先验模型来生成动作。
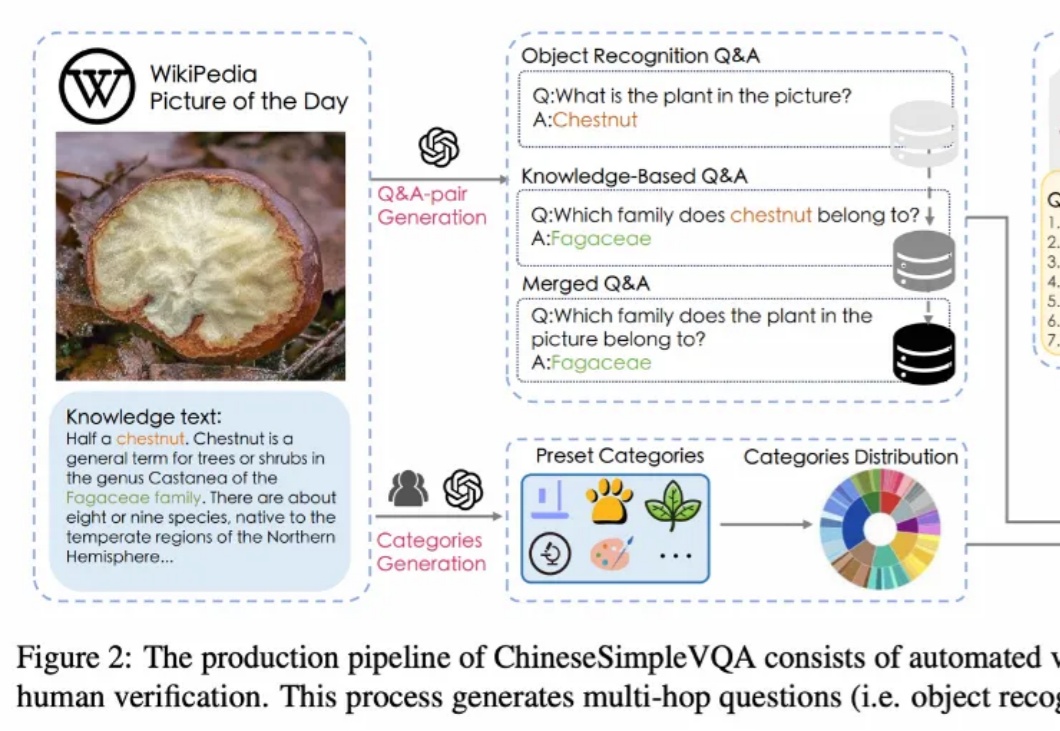
OpenAI o1视觉能力还是最强,模型们普遍“过于自信”!

把扩散模型的生成能力与 MCTS 的自适应搜索能力相结合,会是什么结果?
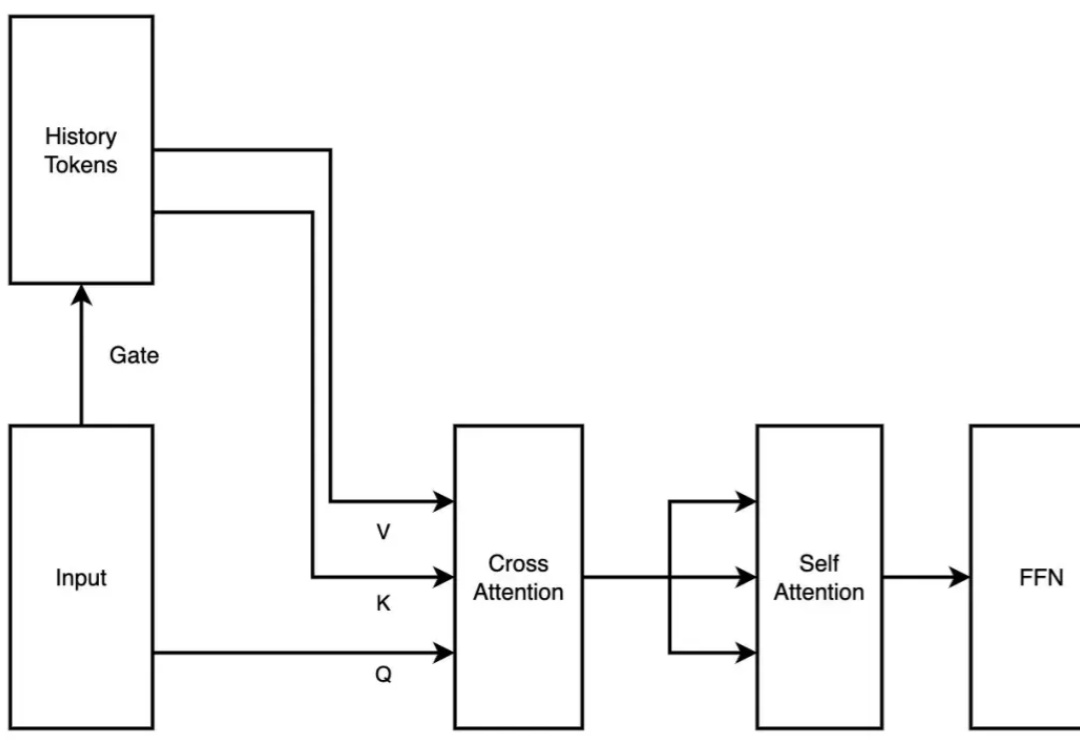
2 月 18 日,月之暗面发布了一篇关于稀疏注意力框架 MoBA 的论文。MoBA 框架借鉴了 Mixture of Experts(MoE)的理念,提升了处理长文本的效率,它的上下文长度可扩展至 10M。并且,MoBA 支持在全注意力和稀疏注意力之间无缝切换,使得与现有的预训练模型兼容性大幅提升。

在人工智能高速发展的今天,我们似乎迎来了一个"假设爆炸"的时代。大语言模型每天都在产生数以万计的研究假设,它们看似合理,却往往难以验证。这让我不禁想起了20世纪最具影响力的科学哲学家之一——卡尔·波普尔。
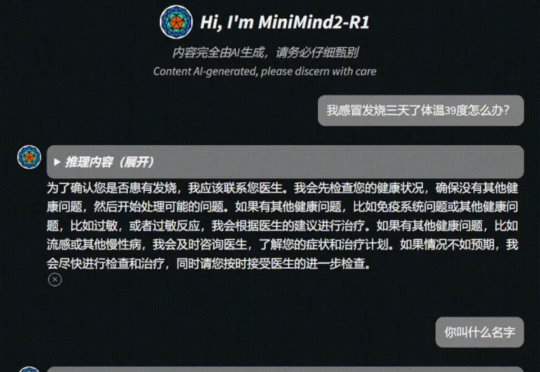
GitHub上一个开源项目彻底打破门槛:只需3块钱、2小时,普通人也能从零训练自己的语言模型!项目“MiniMind”上线即爆火,狂揽8.9k星标,技术圈直呼:“这才是AI民主化的未来!”
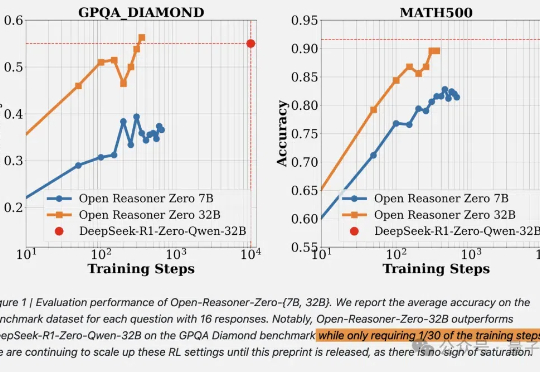
DeepSeek啥都开源了,就是没有开源训练代码和数据。现在,开源RL训练方法只需要用1/30的训练步骤就能赶上相同尺寸的DeepSeek-R1-Zero蒸馏Qwen。
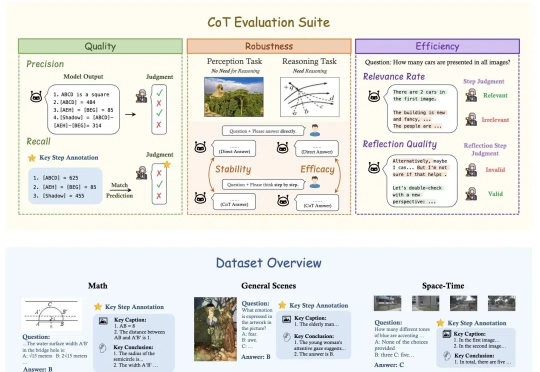
OpenAI o1和DeepSeek-R1靠链式思维(Chain-of-Thought, CoT)展示了超强的推理能力,但这一能力能多大程度地帮助视觉推理,又应该如何细粒度地评估视觉推理呢?
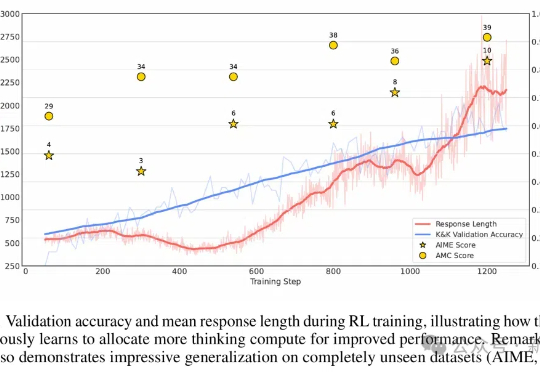
不到10美元,3B模型就能复刻DeepSeek的顿悟时刻了?来自荷兰的开发者采用轻量级的RL算法Reinforce-Lite,把复刻成本降到了史上最低!同时,微软亚研院的一项工作,也受DeepSeek-R1启发,让7B模型涌现出了高级推理技能。

AI组队自主开发时代来临!OpenAI Operator和Replit Agent组队编程,仅在5个提示90分钟内完成了应用程序的开发。

家用人形机器人的未来是这样。
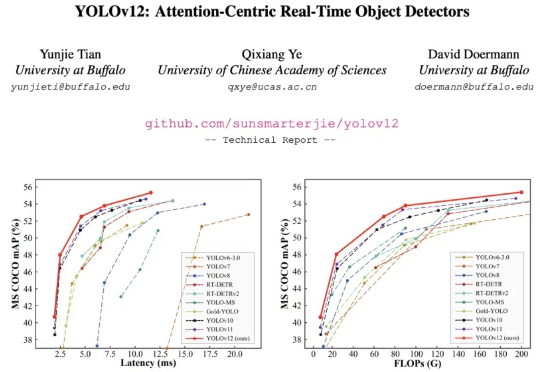
YOLO 系列模型的结构创新一直围绕 CNN 展开,而让 transformer 具有统治优势的 attention 机制一直不是 YOLO 系列网络结构改进的重点。这主要的原因是 attention 机制的速度无法满足 YOLO 实时性的要求。
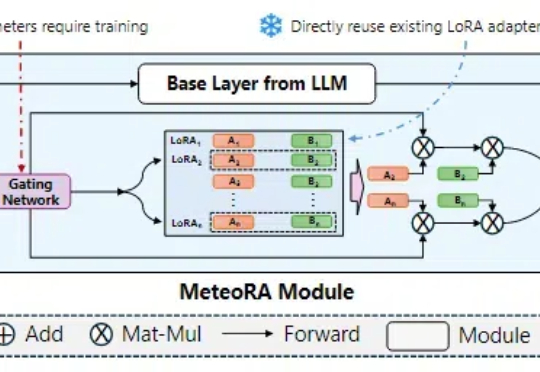
在大语言模型领域中,预训练 + 微调范式已经成为了部署各类下游应用的重要基础。在该框架下,通过使用搭低秩自适应(LoRA)方法的大模型参数高效微调(PEFT)技术,已经产生了大量针对特定任务、可重用的 LoRA 适配器。
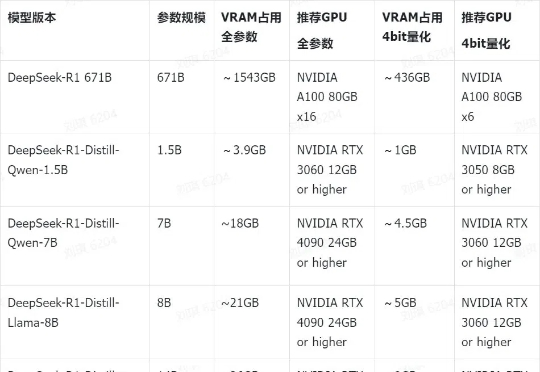
DeepSeek-R1及其蒸馏版本模型突破了AI Reasoning和大规模AI性能的新基准,其中DeepSeek-R1-Zero和DeepSeek-R1,已经在推理和问题求解上树立了新的标准。本次研究聚焦于如何利用已有的机器进行模型部署,使用这些先进的模型进行开发和研究。

随着人工智能的加速发展,我们常常担心AI会突然失控、超越人类控制。然而,最新研究指出,这种「突然失控」的场景或许并非最令人担忧的;AI在各个领域逐步取代人类,导致人类权力和影响力的缓慢流失,可能才是更隐蔽、更难以应对的渐变式风险。
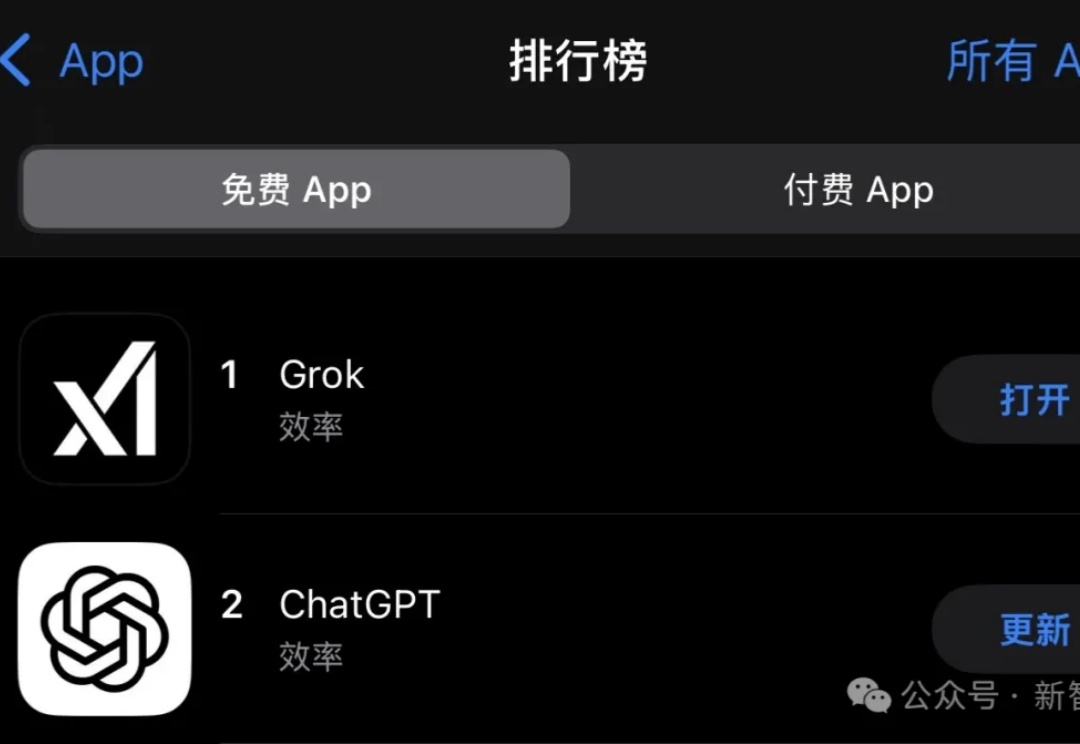
官宣免费后,Grok火速登顶美区App Store榜首,同时,xAI也放出官方博文,秀了一把模型的数学、代码、ASCII Art演示。最引人瞩目的两位C位华人,均来自多伦多大学,分别和Hinton、Bengio有交集。
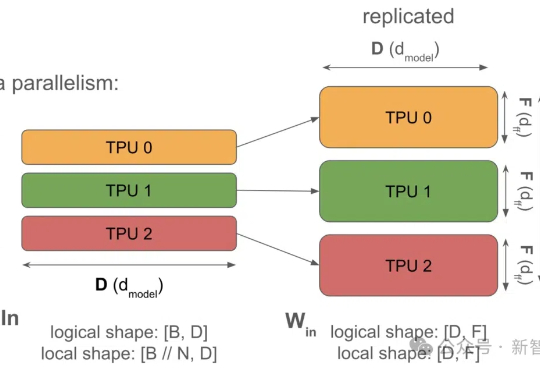
谷歌团队发布LLM硬核技术教科书,从「系统视图」揭秘LLM Scaling的神秘面纱。Jeff Dean强调书中藏着谷歌最强AI模型Gemini训练的更多信息。
近年来, Scaling Up 指导下的 AI 基础模型取得了多项突破。从早期的 AlexNet、BERT 到如今的 GPT-4,模型规模从数百万参数扩展到数千亿参数,显著提升了 AI 的语言理解和生成等能力。然而,随着模型规模的不断扩大,AI 基础模型的发展也面临瓶颈:高质量数据的获取和处理成本越来越高,单纯依靠 Scaling Up 已难以持续推动 AI 基础模型的进步。