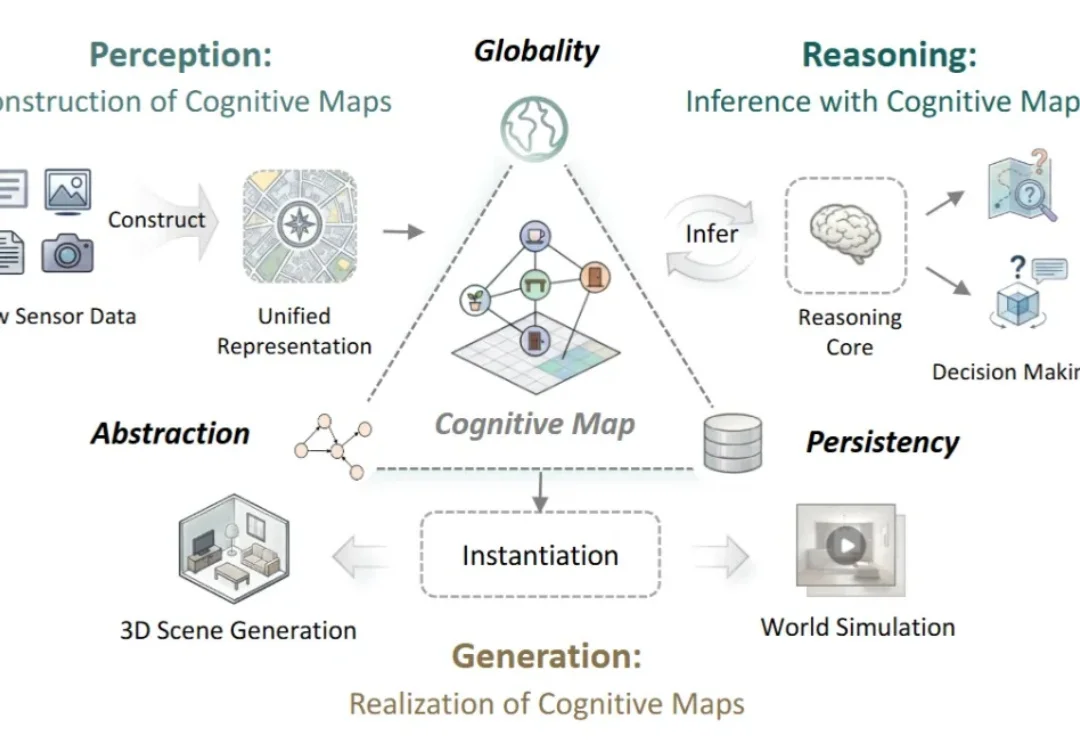
让机器真正理解世界需要一张「认知地图」,中科院发布空间智能综述
让机器真正理解世界需要一张「认知地图」,中科院发布空间智能综述AI 已经能看懂图像、生成场景,甚至在虚拟环境中规划行动。
来自主题: AI技术研报
6423 点击 2026-06-09 14:06
 搜索
搜索
AI 已经能看懂图像、生成场景,甚至在虚拟环境中规划行动。
这两天 Codex 登录的事算是暂时翻篇了。

近年来,文生图模型的能力快速提升。从 Stable Diffusion 到 FLUX、Qwen-Image,扩散模型已经能够生成高质量图像,也能处理越来越复杂的文本提示。
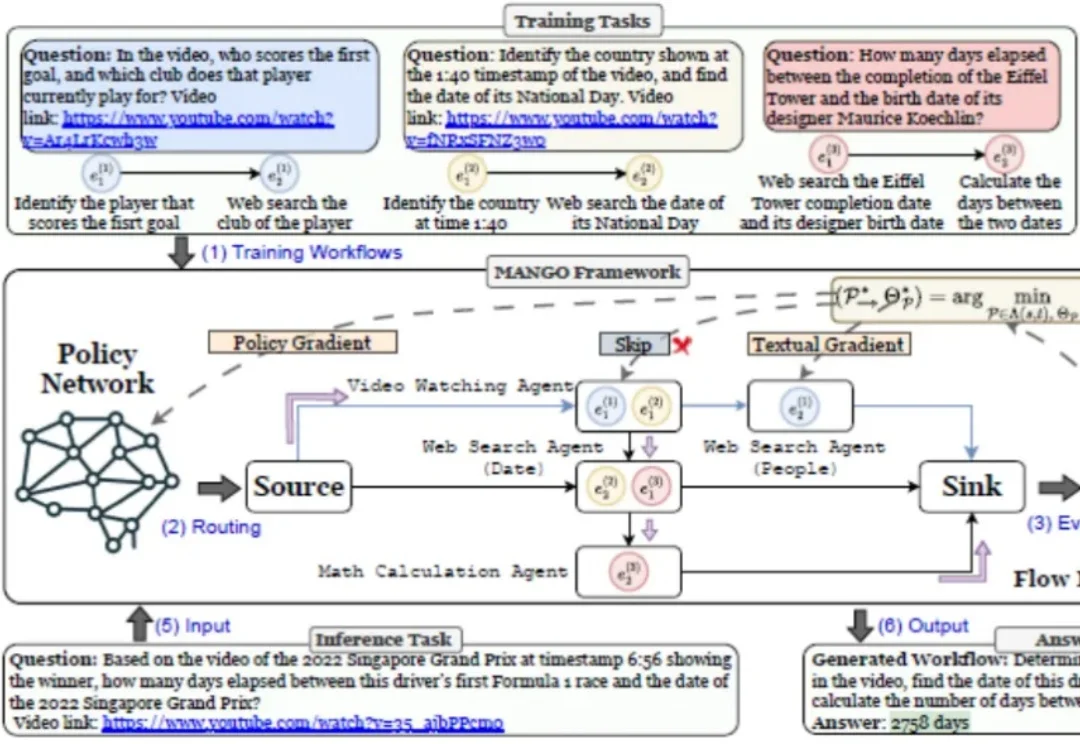
多智能体协作对于解决复杂问题虽然具有巨大优势,但是其架构本质上易出现错误传播,因为由不正确的工作流生成或单智能体幻觉输出引起的错误会沿着协作链蔓延,影响最终结果。
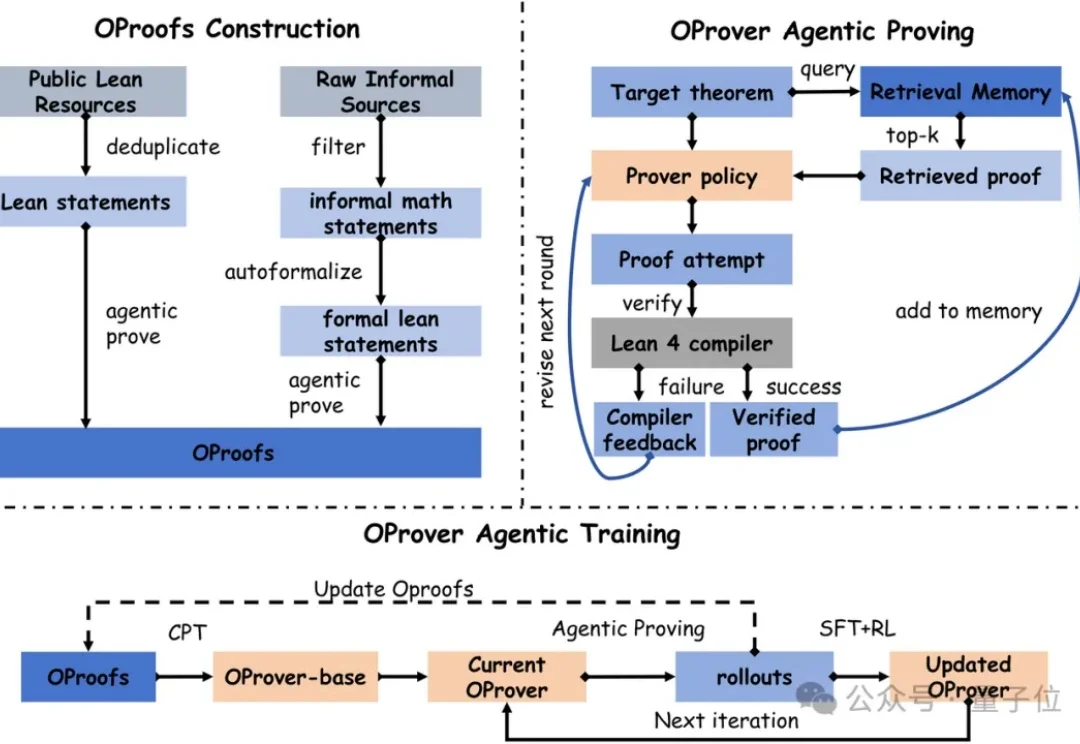
形式化定理证明,一直是LLM公认最严苛的推理试金石,每一步推导都必须通过Lean 4内核的机器验证。

一年前,行业还在为“从自动补全到 Agent”的进化感到兴奋。然而一年过去,我们不难发现单纯靠“Vibe Coding”和“Prompt 调优”,面对非确定性模型带来的风险和成本问题,显然无法撑起企业级软件开发。
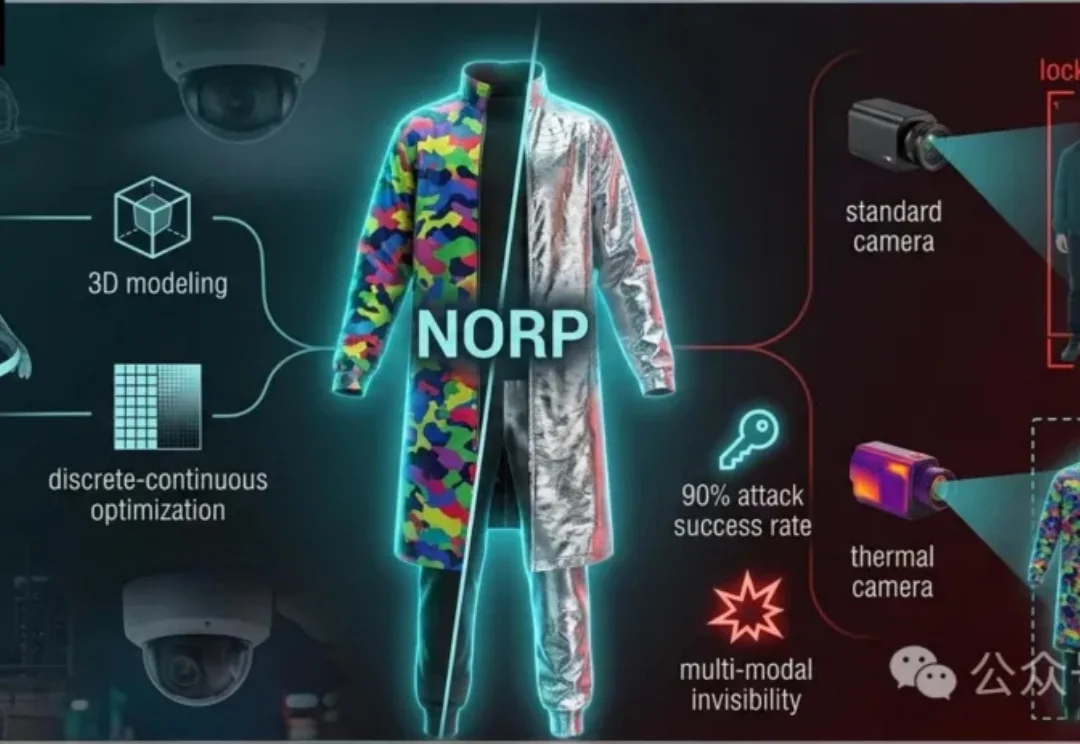
清华大学提出一种新型物理对抗方法,利用特殊服装同时干扰可见光和热成像检测。这种服装通过非重叠设计和三维建模优化,可有效躲避RGB-T检测器,促进系统安全性研究。

过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。
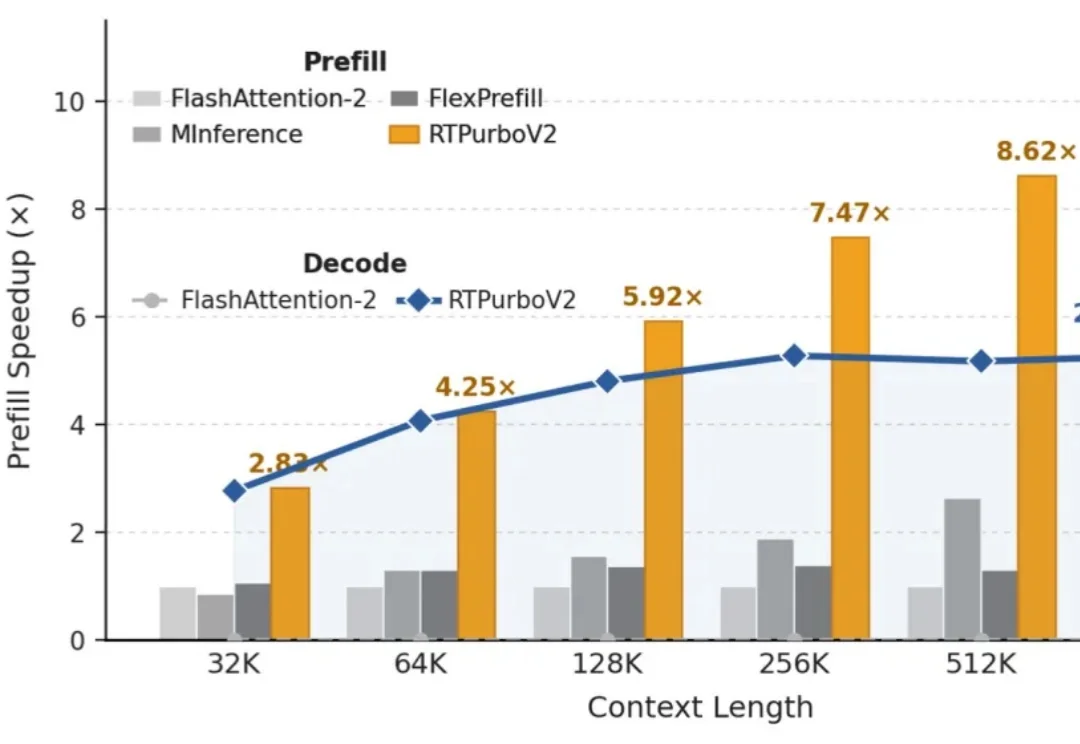
“Full Attention 正在被遗忘”

2K 图像 210ms 解码,4K 细节直接生成,传统「解码 + 超分」流水线可能要被重写了。

不扩上下文窗口、不换骨干架构、不做全参数微调 —— 只需要一个 8×8 的在线状态矩阵,就能让冻结的 Transformer 拥有真正的长期记忆。

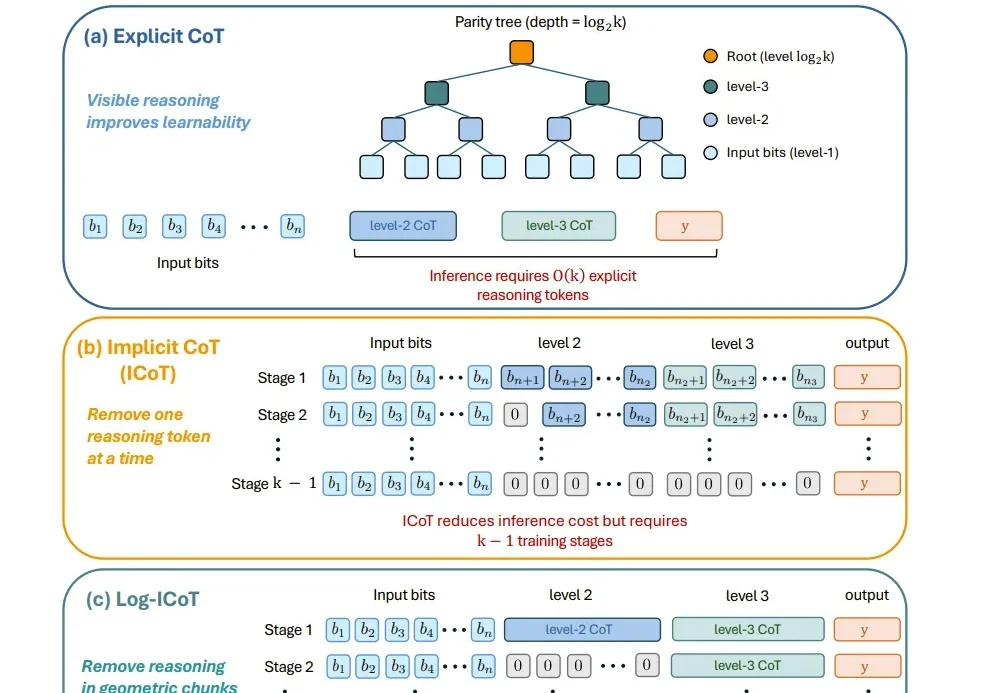
大模型开始进入理论计算机科学最核心的问题之一:算法设计。

北大彭宇新团队提出「美学照片重构」新任务,从摄影教学视频中自动构建数据集AesRecon,并开发两阶段模型AesFormer,通过优化构图、视角与人物姿态,提升照片的美感与艺术表现力。

在具身智能最难的泛化问题上,他们连续拿出顶会级成果,并把它们沉淀进其创新 VLOA 大模型,推动机器人迈向广阔现实。

一道悬了12年没人证出来的物理猜想,诺贝尔物理学奖得主Giorgio Parisi把它交给了Claude,模型几乎自己推出了完整证明。
过去一年,AI 推理模型的使用成本让不少开发者叫苦。
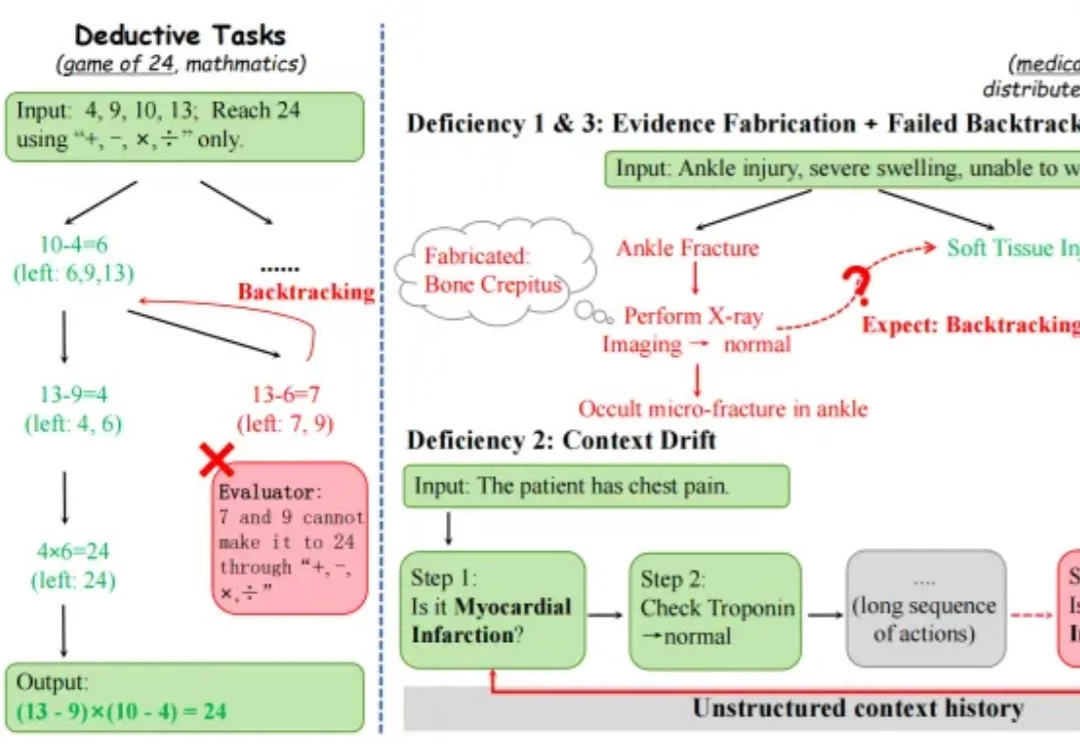
近年来,大语言模型在数学、代码等任务上的表现不断刷新上限,但到了医疗诊断、故障排查这类真实世界任务里,真正困难的是让多个智能体在不确定的动态环境中持续协作推理。
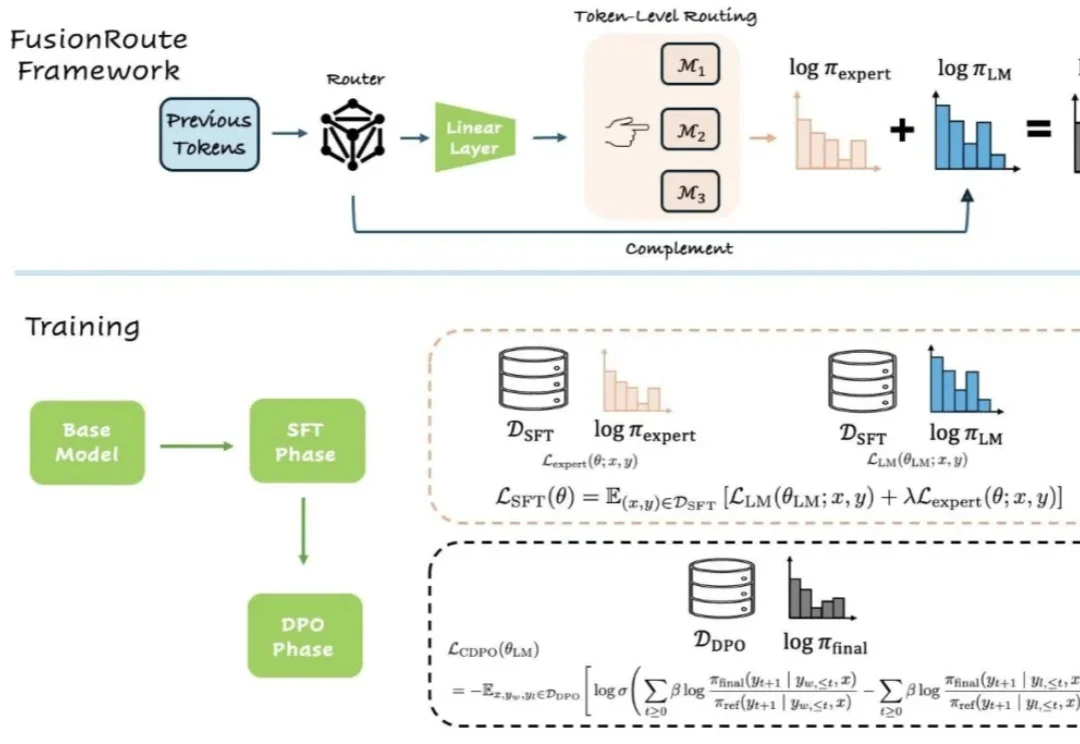
近年来,大语言模型能力的提升,已不再仅仅依赖于更大的模型规模或更多的训练数据。越来越多的研究开始探索另一条路径:通过多个专家模型的协作来完成生成任务。
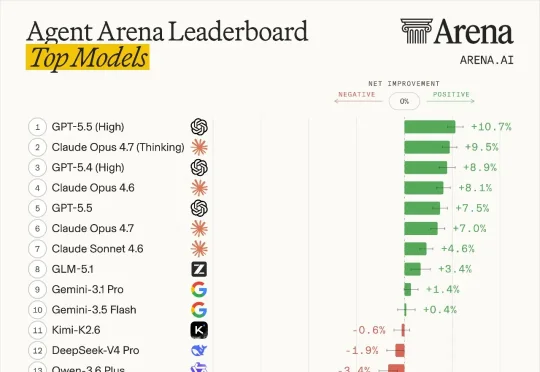
6月4日,Arena.ai发布Agent Arena排行榜,用373,431次真实会话的数据,给18个主流模型的Agent能力排了个座次。先看总榜。Agent Arena的排名依据是“净改进”(Net Improvement),用因果推断方法算出每个模型相对于随机基线的性能提升幅度。正值代表比随机选择更好,负值说明不如随机。

近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。
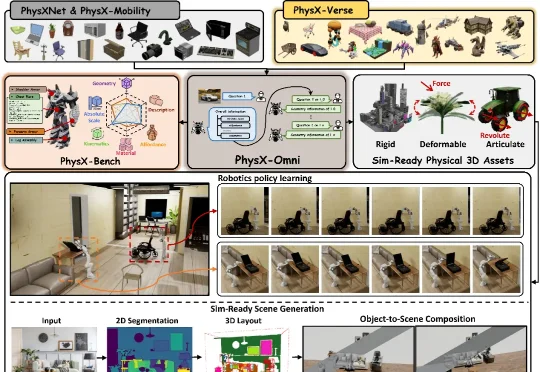
该论文第一作者为曹子昂,研究方向主要聚焦于 3D AIGC、Physical AI 与具身智能。论文主要合作者包括来自南洋理工大学的李海天、姚润茂、洪方舟、陈昭熹,以及大晓机器人的刘英豪和潘亮。通讯作者为南洋理工大学刘子纬教授。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,

早在 2023 年大模型快速发展期,哈工大张民教授立知大模型团队已开展多模态大模型驱动的视频内容创作智能体研究,并全球首发开源了电影制作智能体 FilmAgent 与动画片生成智能体 Anim-Director,受到国内外智能体研究者与文艺创作者的广泛关注。
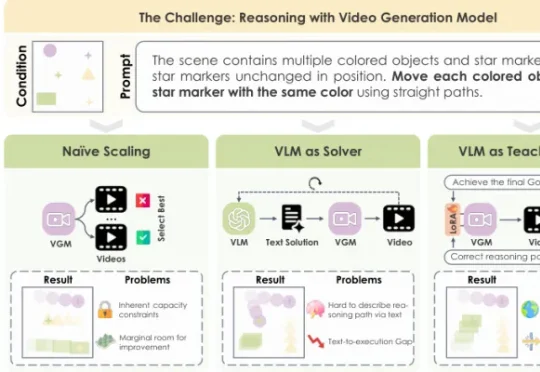
怎么让VGM学会按规则推理?过去主要有两条路。两条路,一个不动模型,一个只写文字,都没真正解决“执行”问题。为此,城大×快手可灵提出了第三条路:VLM-as-Teacher。
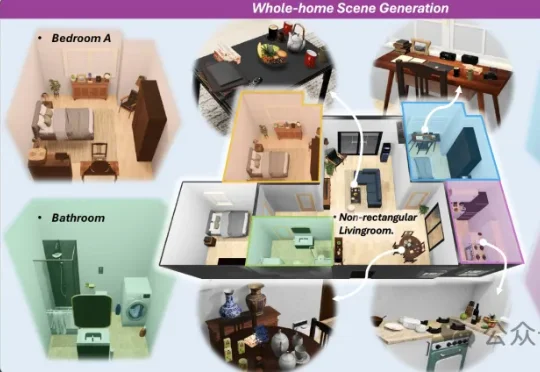
一觉睡醒,具身智能公司竟然也开始搞房地产了?!刚刚,大晓机器人联合港中文MMLab发布了一个新项目——Kairos-Homeworld,全球首个实现全屋三维生成与物体级全交互的统一框架。
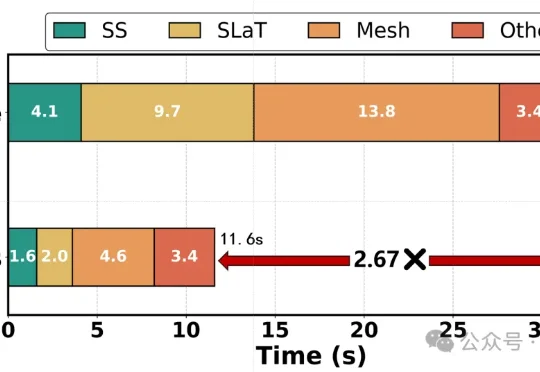
来自中国科学院计算技术研究所、ETH Zurich等机构的研究者提出了Fast-SAM3D。该方法直接面向SAM3D的推理链路做训练无关加速,在最大程度保持重建质量的同时,将单对象生成提速最高2.67倍,场景生成提速最高2.01倍。
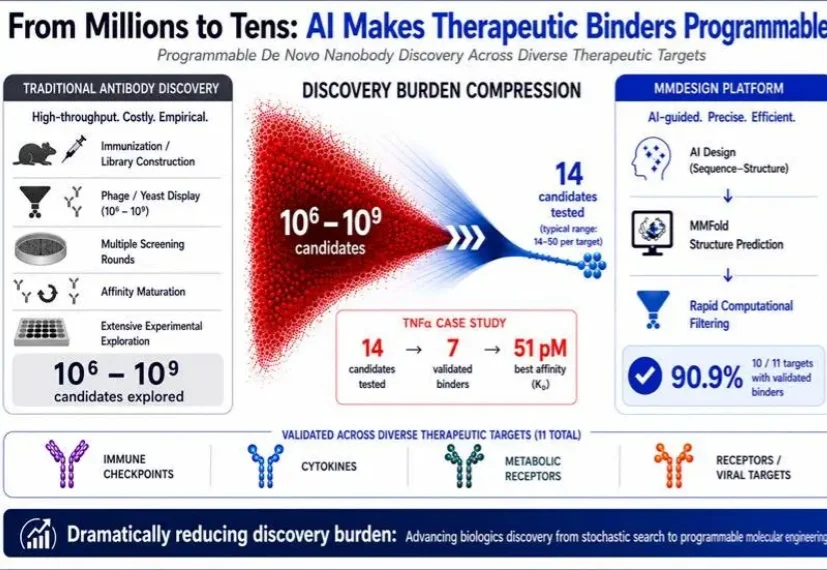
今日,分子之心正式对外发布全新的AI生物药从头设计平台——MMDesign。
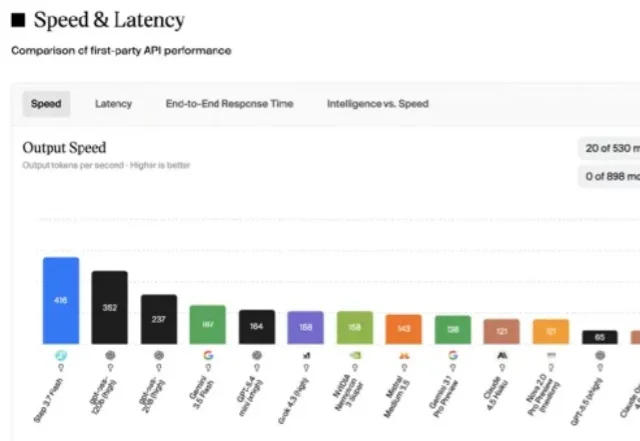
OpenRouter Trending榜单冷不丁窜出一匹国产黑马,热度暴涨稳居全球第二。

长上下文模型越来越能“记”,但真正让它们跑到线上时,最先顶不住的往往不是算力,而是KV Cache。

我们今天以 PDF 写论文的方式,已经持续了三百多年。然而论文其实是把一段混乱反复、充满试错的真实研究,讲成一个干净利落、足以服人的完美故事。