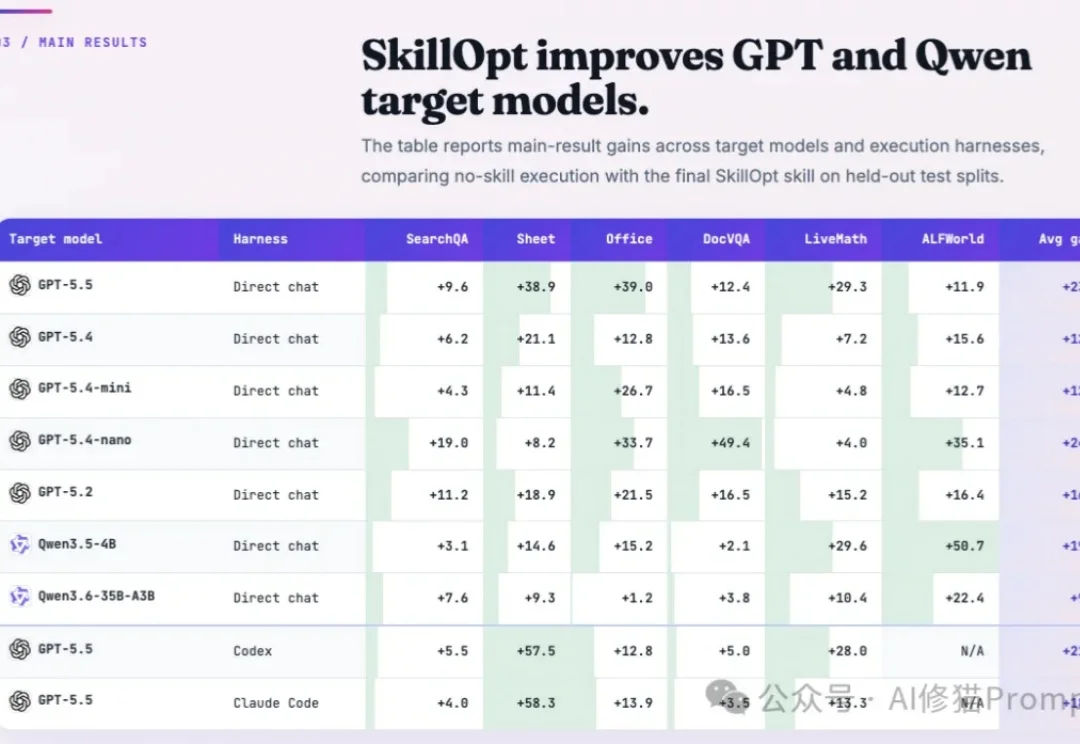
微软最新提出SkillOpt,用训练大模型的方法优化你的Agent Skills
微软最新提出SkillOpt,用训练大模型的方法优化你的Agent Skills训练大模型时,工程师绝对不会指望网络做一次前向传播就能收敛。它需要数据喂养、Batch切分、学习率控制、验证集筛选以及优化器状态的迭代试错。
来自主题: AI技术研报
10226 点击 2026-06-05 09:13
 搜索
搜索
训练大模型时,工程师绝对不会指望网络做一次前向传播就能收敛。它需要数据喂养、Batch切分、学习率控制、验证集筛选以及优化器状态的迭代试错。

刚刚,谷歌扔出Gemma 4 12B大杀器!16G轻薄本就能全离线流畅跑通,性能直逼26B巨兽,全体开发者惊呼太震撼了,平民级本地AI封神之作降临。硬核实测速来看!

世界模型火,火到都有点乱了。

Claude Mythos就用6.1×10²⁷ FLOPs提前叩响了奇点的大门。

都以为让AI查数据省事,结果它答得漂亮你却不敢信。Anthropic最近说这事有解了,靠的是一套和代码无关的「笨功夫」。
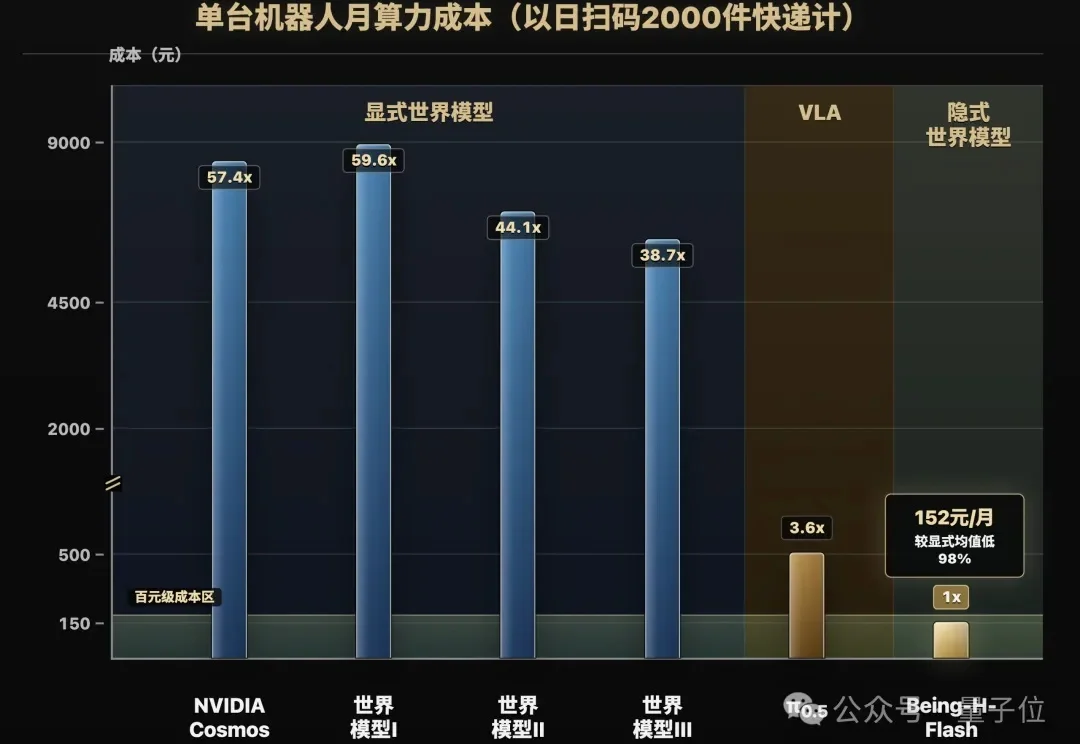
真没想到啊!物理AI的账单,有一天竟然能和大模型一个价。
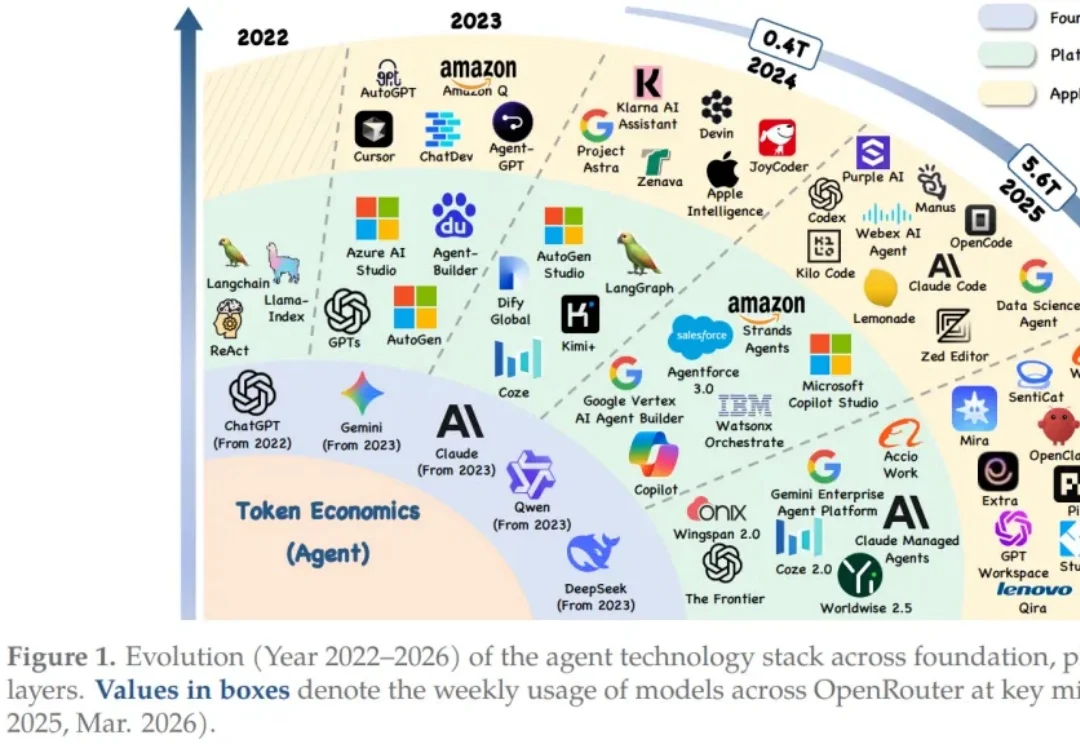
当大模型 Agent 从实验室加速走向金融、医疗、代码开发等高价值场景,一个隐秘却致命的瓶颈正在浮现:Token 的指数级消耗正引发算力、协作与安全的系统性危机。传统 “堆算力、加参数” 的线性优化已触及天花板,我们该如何在 “输出质量” 与 “经济成本” 之间找到可持续的最优解?

为解决科研中对单篇文献深度解析的需求,佐治亚大学团队提出IntrAgent,专注单篇内容,避免大模型幻觉。通过段落排序与迭代阅读机制,精准提取实验细节与元数据。

一直有在关注的一个 AI 短剧工具最近终于上线了,那就是群核科技的 LuxReal 短剧版。

刚刚过去的GTC Taipei上,最备受关注的,莫过于Cosmos 3。

赋予机器人物理理解和预测能力是通用操作的关键。蚂蚁灵波等机构提出的 LingBot-VA 试图将视频帧预测与动作推理统一起来,让机器人通过自回归扩散框架学会“一边思考一边行动”。

这篇文章想回答几个大家更关心的基础问题:Vector Lakebase 能解决你的什么问题,什么场景下用它最合适,如何用好Vector Lakebase 。

过去半年,几乎所有Agent框架都在补长期记忆能力。最常见的做法,是给系统接一个向量数据库,把历史对话、用户偏好、项目经验、工具调用结果、失败案例都存进去。看起来,只要把“记忆”这块补上,Agent就能从一次性对话工具变成长期协作伙伴。
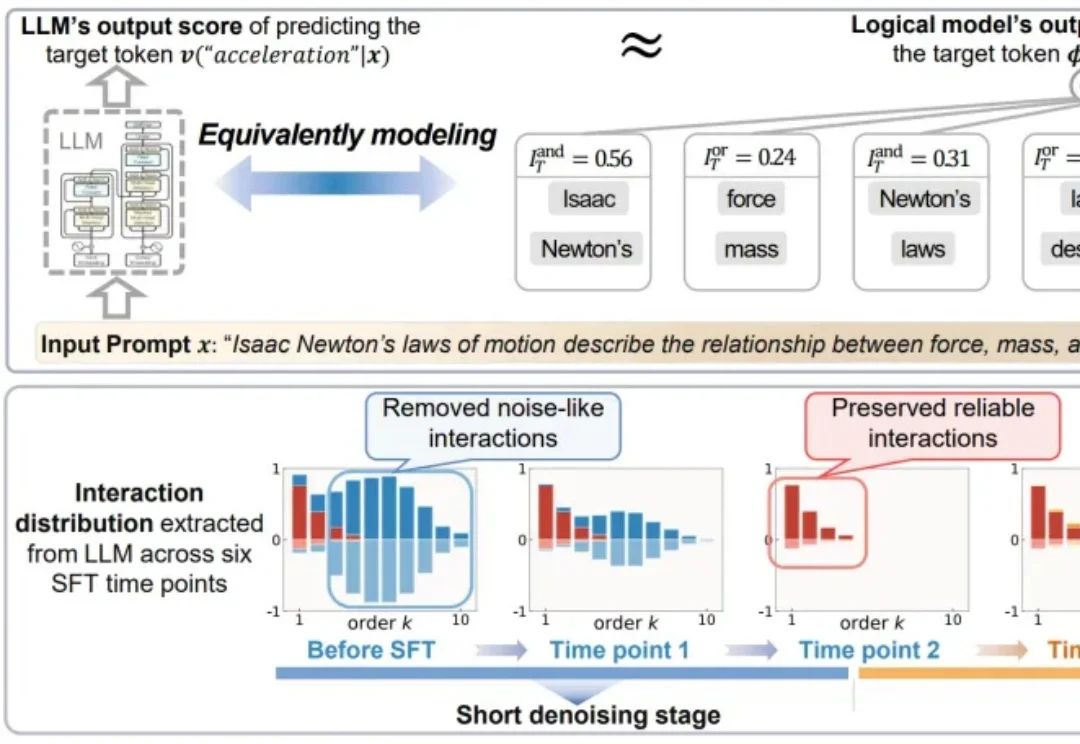
长期以来,监督微调(Supervised Fine-Tuning,SFT)一直是深度神经网络中最常用的模型适配手段。在中小规模的传统神经网络中,SFT 通常能够稳定提升下游任务表现。

Codex 又又又大更新,前一天负责人还在说,是不是要改名 ChadGPT,网友在下面评论说,不如直接将 ChatGPT 重新命名为 Codex。

由格灵深瞳灵感实验室主导研发的 LLaVA-OneVision-2.0,是一款面向下一代感知智能的视觉语言大模型。团队充分利用视频 Codec 流和自研 OneVision-Encoder,实现跨帧、跨事件的增量观测和连续证据流建模。本文将详细介绍模型架构、训练方法与能力验证,展示该技术在视频理解、空间推理和目标追踪等任务中的应用潜力。
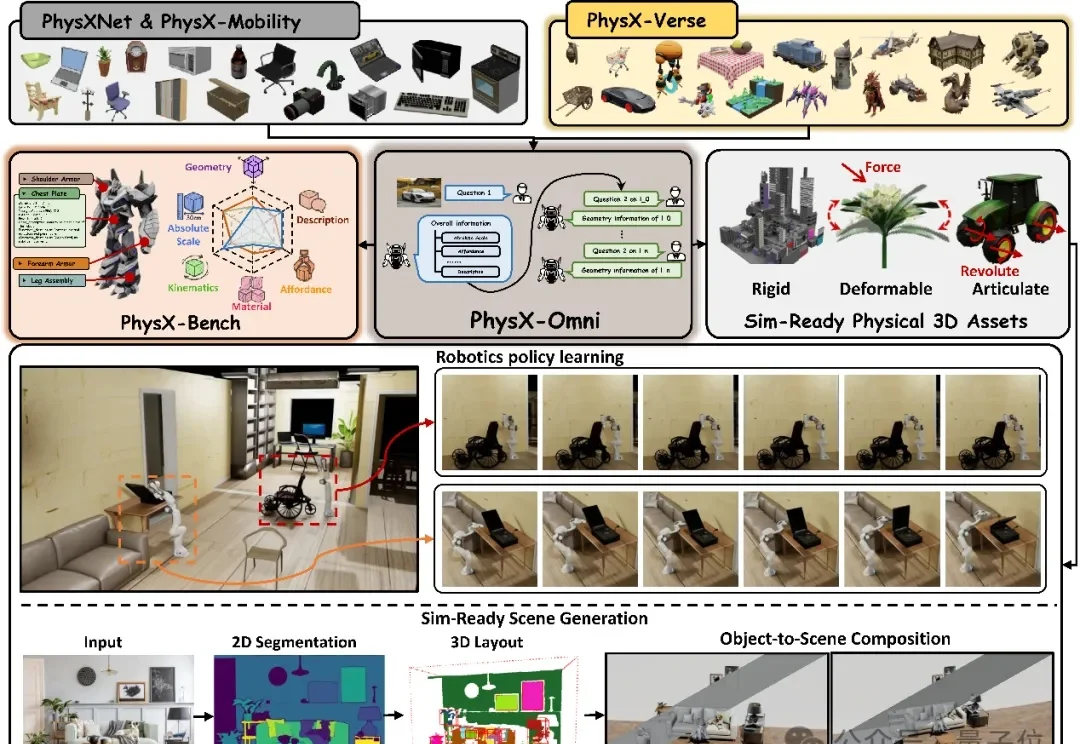
3D生成领域,一个核心矛盾正在浮出水面。
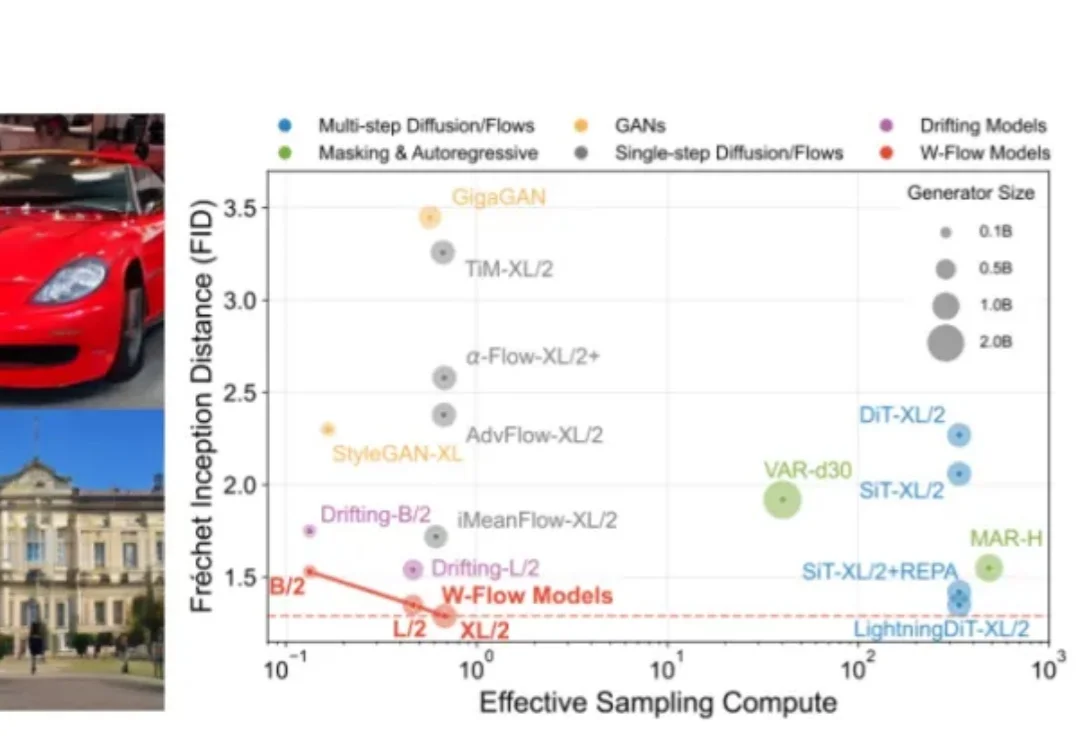
训练时让分布沿最优传输的 “下山方向” 走,推理时只需一次网络前向。W-Flow 把多步演化压进静态生成器,在 ImageNet 256×256 上刷新一步生成指标。

随着大模型智能体深入渗透真实操作系统,一种全新的安全威胁悄然成型:行为越狱(Behavior Jailbreak)。现有安全基准只盯着模型「说了什么」,却对「做了什么」视而不见。新基准LITMUS是首个同时覆盖真实OS环境行为越狱、语义-物理双层验证与多攻击范式的完整评测体系,并首次系统量化了「执行幻觉」这一被整个评测社区忽视的致命盲区。

过去八九年,我们一直在做一件事:把向量数据库从一个很小众的系统方向,做成 AI 基础设施里的关键组件。
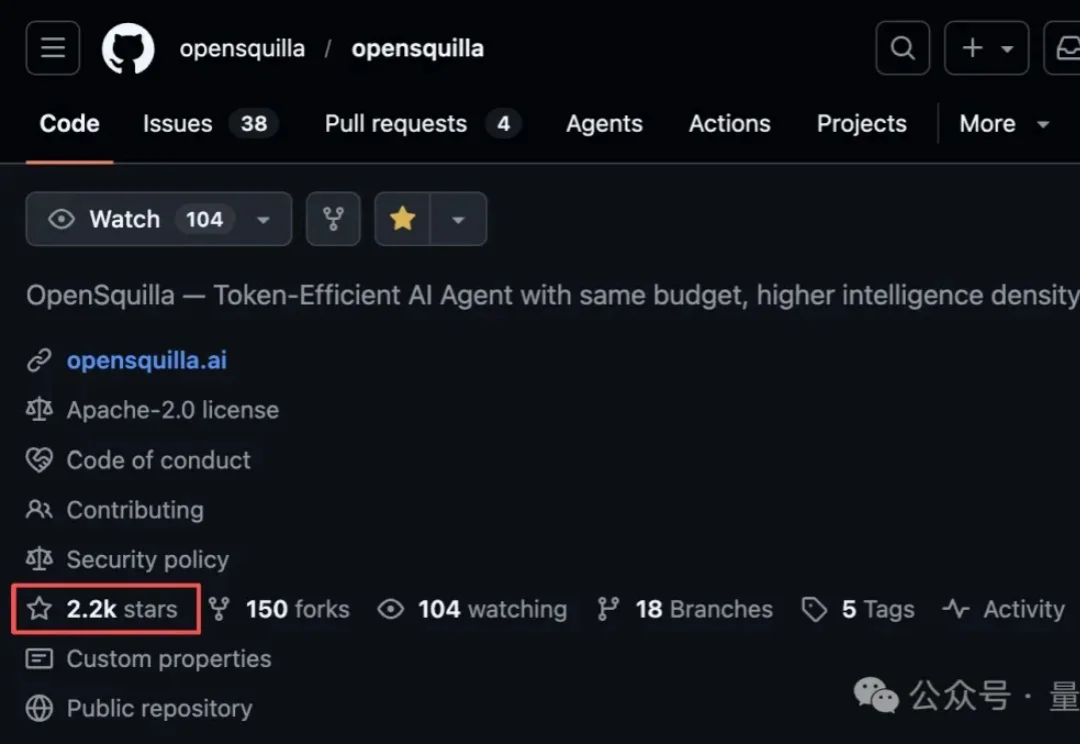
GitHub最新火爆仓库:OpenSquilla。

如果说扩散世界模型的瓶颈,是每一步去噪都要把同一个大 Transformer 再跑一遍,那么 WorldCache 的思路就是:不要再把所有 Token、所有时间步都当成同一件事。这篇工作把 “哪些内容适合缓存”和“哪些时刻必须重算” 拆开处理,在不重新训练模型、几乎不增加额外显存的前提下,把缓存真正做成了一套更贴合世界模型结构的推理策略。
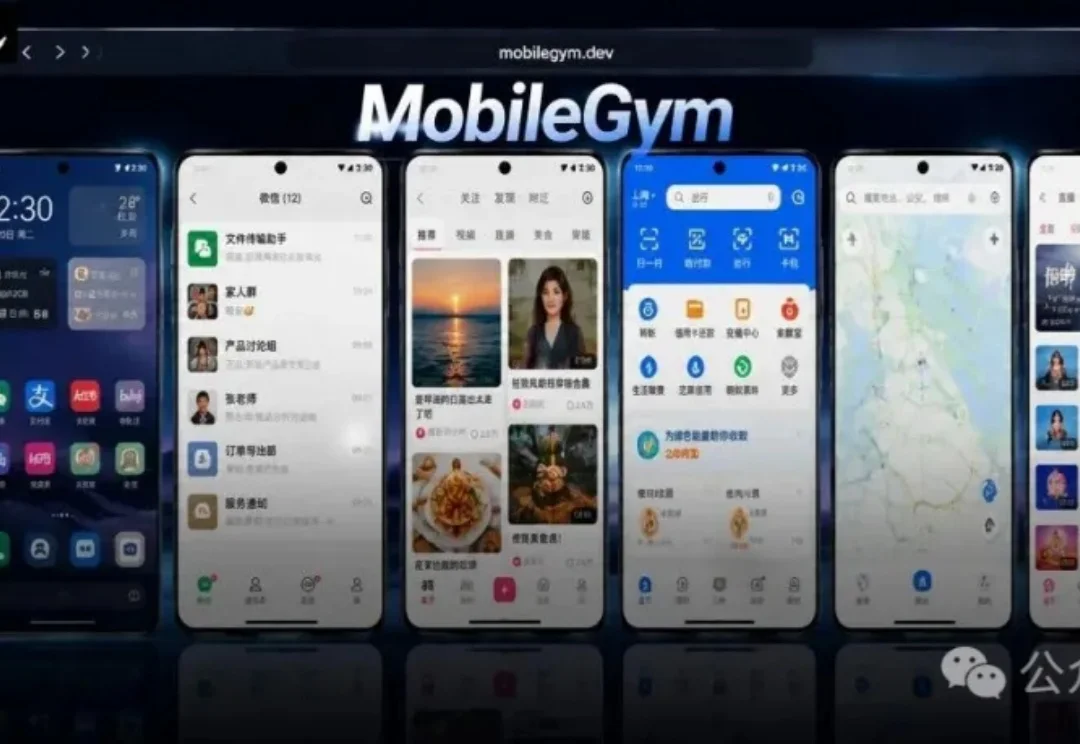
中科院自动化所模式识别实验室开源MobileGym,运行在浏览器里的高并发安卓仿真平台,完全自定义,告别模拟器风控与真机成本,一个平台搞定Mobile Agent训练与评测,甚至还能玩原神!
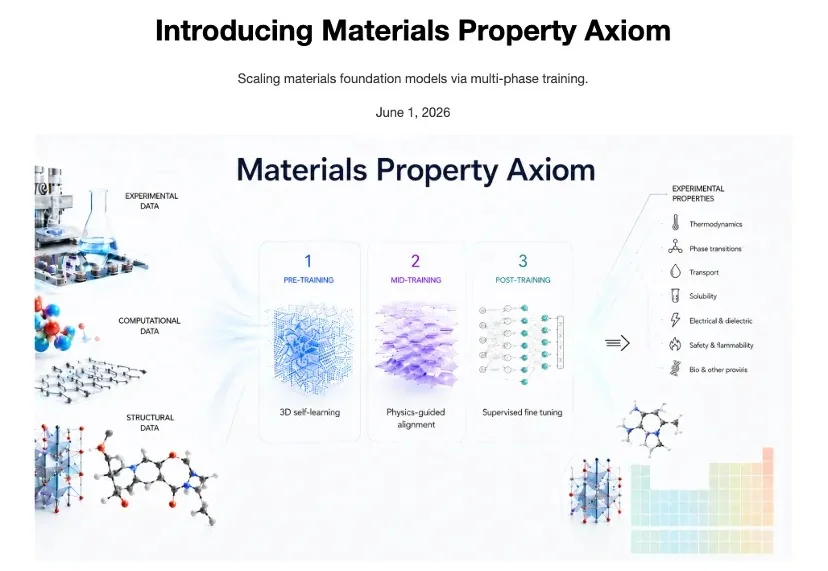
今年,我们正在打开 AI 自我进化的大门,按下了通往 AGI 的加速键。
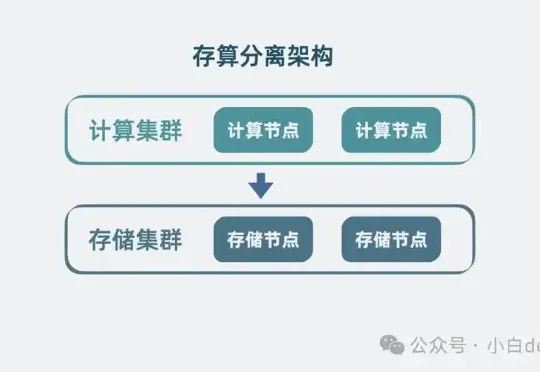
一个有灵魂,有记忆的 Agent,一次任务的生命周期包括以下步骤
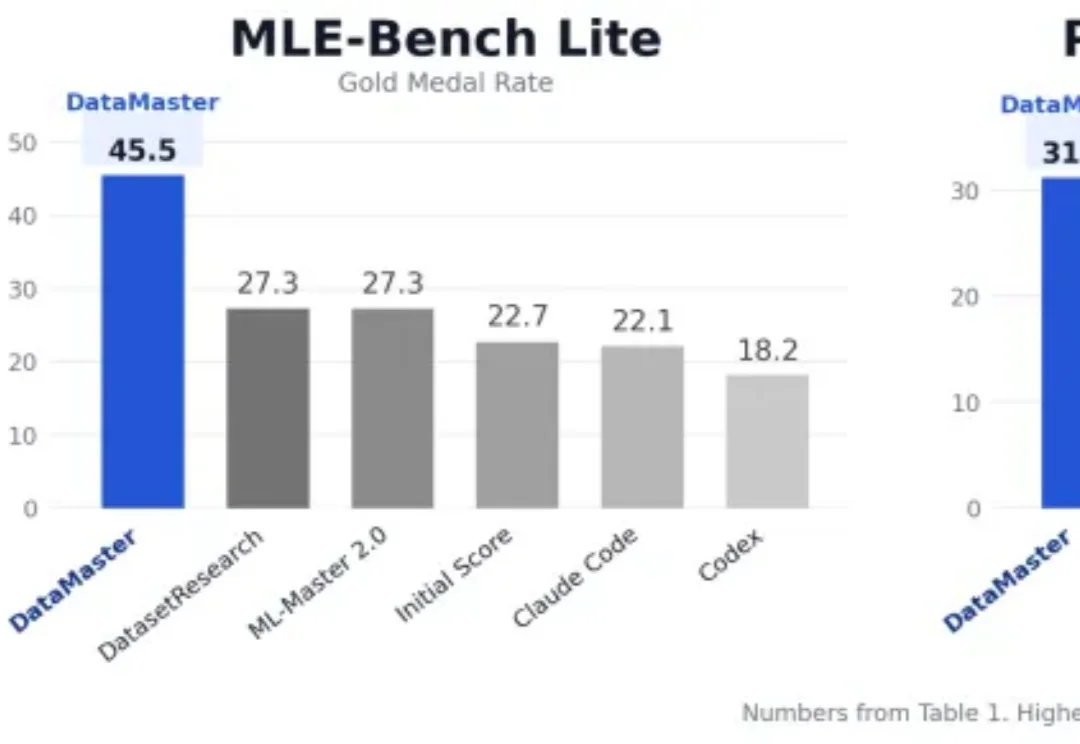
过去,AI 研发基本是一条由人主导的流水线。
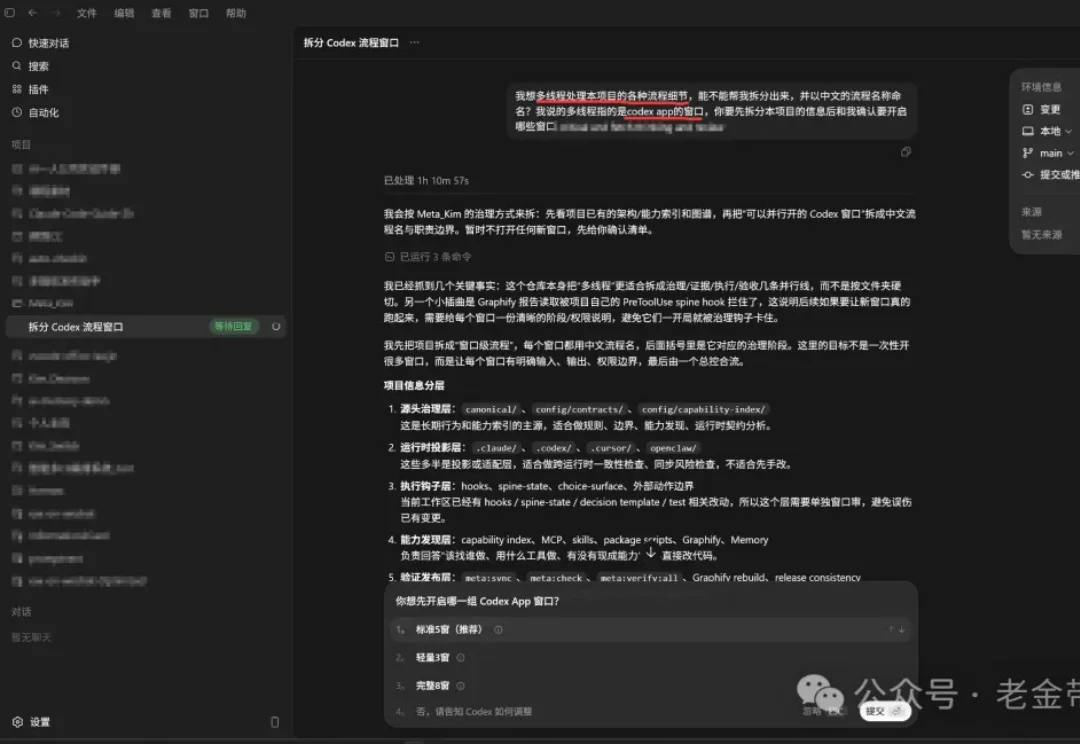
昨儿发了 Coze 3.0 的介绍说明,很多小伙伴看起来都没仔细看。

从 LLM 的超长文本处理、视频生成模型的以假乱真、Agent 自主规划与执行的日趋成熟,到 VLA、世界模型等开始进入物理世界,AI 正在不断拓宽其能力边界。

最近,前沿实验室 Mind Lab 密集发布了一系列关于 LoRA 与 PEFT(高效微调)的研究结果,似乎描绘出了另一条大模型「持续学习」的路径。在 Mind Lab 的视角中,PEFT 不再是对大模型全参数后训练的一种廉价平替,更是实现从 “基础模型” 向 “可持续学习智能体” 过渡的核心架构机制。

在具身智能训练中,“把计算全部塞进GPU”似乎成了唯一的提速密码,机器人运控并行训练的框架,IsaacLab、MuJoCoPlayground、mjlab都默认遵循这一范式,这些系统都牢牢绑定在NVIDIA生态中。