# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Qwen 系列会是众多大学实验室新的默认基础模型吗?
斯坦福团队套壳清华大模型的事件不断发酵后,中国模型在世界上开始得到了更多关注。不少人发现,原来中国已经有不少成熟的大模型正在赶超国外。
HuggingFace 平台和社区负责人 Omar Sanseviero 曾表示,AI 社区一直在「忽视」中国机器学习生态系统的工作,他们正在用有趣的大语言模型、视觉大模型、音频和扩散模型做一些令人惊奇的事情,如 Qwen、Yi、DeepSeek、Yuan、WizardLM、ChatGLM、CogVLM、Baichuan、InternLM、OpenBMB、Skywork、ChatTTS、Ernie、HunyuanDiT 等。
今日,阿里云通义千问团队 Qwen2 大模型开源的消息吸引了众多 AI 开发者的目光。Qwen2-72B 性能超过了业界著名的开源模型 Llama3-70B,也超过文心 4.0、豆包 pro、混元 pro 等众多国内闭源大模型。所有人均可在魔搭社区和 Hugging Face 免费下载通义千问最新开源模型。
相比今年 2 月推出的通义千问 Qwen1.5,Qwen2 整体性能实现代际飞跃。而在上海人工智能实验室推出的权威模型测评榜单 OpenCompass 中,此前开源的 Qwen1.5-110B 已领先于文心 4.0 等一众国内闭源模型。可见 Qwen2 的能力更加非凡。
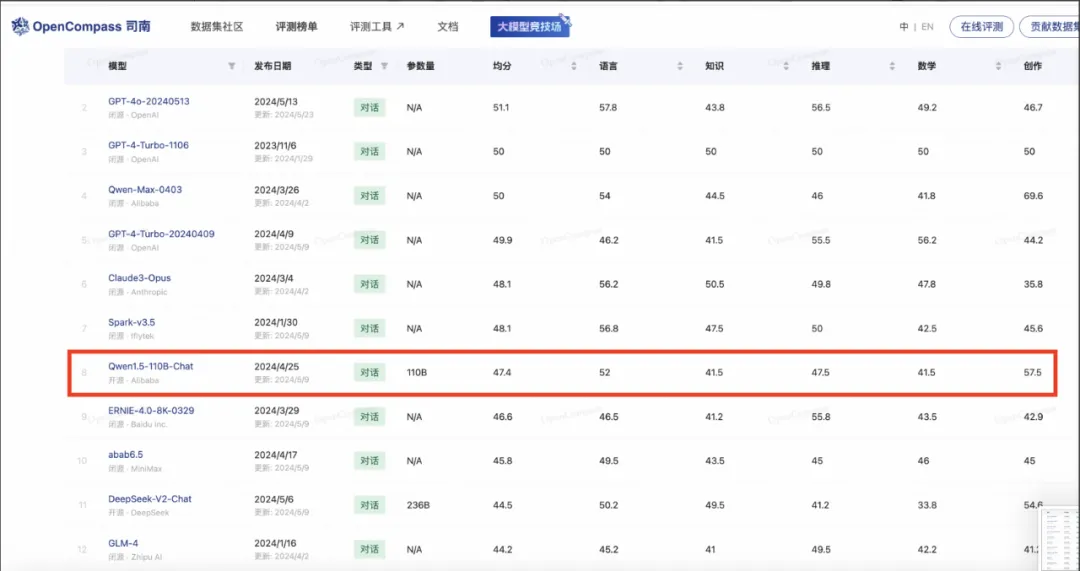
OpenCompass 大模型测评榜单上,此前开源的 Qwen1.5-110B 已领先于文心 4.0 等一众国内闭源模型。
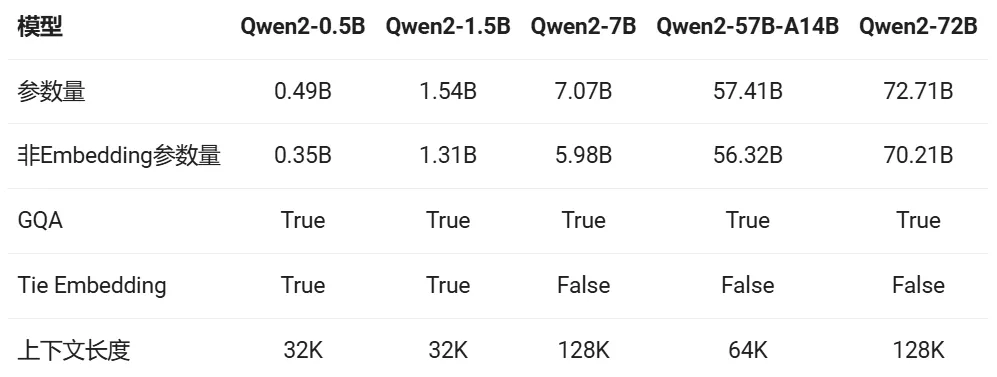
本次 Qwen2 系列包括五种尺寸的基础和指令调优模型,包括 Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B 和 Qwen2-72B。
魔搭社区模型下载地址:
在先前的 Qwen1.5 系列中,只有 32B 和 110B 的模型使用了 GQA(Grouped-Query Attention)。而这一次,Qwen2 系列所有尺寸的模型都使用了 GQA。这让大家能够更加方便地体验到 GQA 带来的推理加速和显存占用降低的优势。针对小尺寸模型,由于 embedding 参数量较大,使用了 Tie Embedding 的方法让输入和输出层共享参数,增加非 embedding 参数的占比。
此外,所有的预训练模型均在 32K tokens 的数据上进行训练,并且研究团队发现其在 128K tokens 时依然能在 PPL 评测中取得不错的表现。然而,对指令微调模型而言,除 PPL 评测之外还需要进行大海捞针等长序列理解实验。在该表中,作者根据大海捞针实测结果,列出了各个指令微调模型所支持的最大上下文长度。而在使用 YARN 这类方法时,Qwen2-7B-Instruct 和 Qwen2-72B-Instruct 均实现了长达 128K tokens 上下文长度的支持。
研究团队投入了大量精力研究如何扩展多语言预训练和指令微调数据的规模并提升其质量,从而提升模型的多语言能力。尽管大语言模型本身具有一定的泛化性,他们还是针对性地对除中英文以外的 27 种语言进行了增强,并针对性地优化了多语言场景中常见的语言转换(code switch)问题,使模型当前发生语言转换的概率大幅度降低。使用容易触发语言转换现象的提示词进行测试,观察到 Qwen2 系列模型在此方面能力的显著提升。

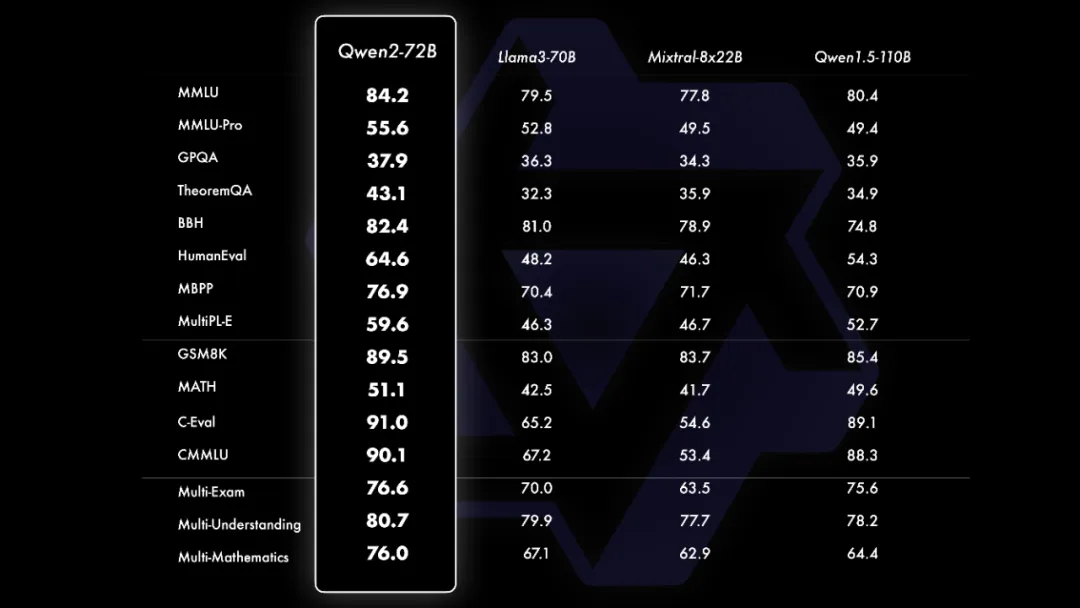
Qwen2-72B 在针对预训练语言模型的评估中,对比当前最优的开源模型,Qwen2-72B 在包括自然语言理解、知识、代码、数学及多语言等多项能力上均显著超越当前领先的模型,如 Llama-3-70B 以及 Qwen1.5 最大的模型 Qwen1.5-110B。这得益于其预训练数据及训练方法的优化。
大规模预训练后,研究团队对模型进行精细的微调,以提升其智能水平,让其表现更接近人类。这个过程进一步提升了代码、数学、推理、指令遵循、多语言理解等能力。微调过程遵循的原则是使训练尽可能规模化的同时并且尽可能减少人工标注。
研究团队探索了如何采用多种自动方法以获取高质量、可靠、有创造力的指令和偏好数据,其中包括针对数学的拒绝采样、针对代码和指令遵循的代码执行反馈、针对创意写作的回译、针对角色扮演的 scalable oversight 等。在训练方面,开发团队结合了有监督微调、反馈模型训练以及在线 DPO 等方法,还采用了在线模型合并的方法减少对齐税。
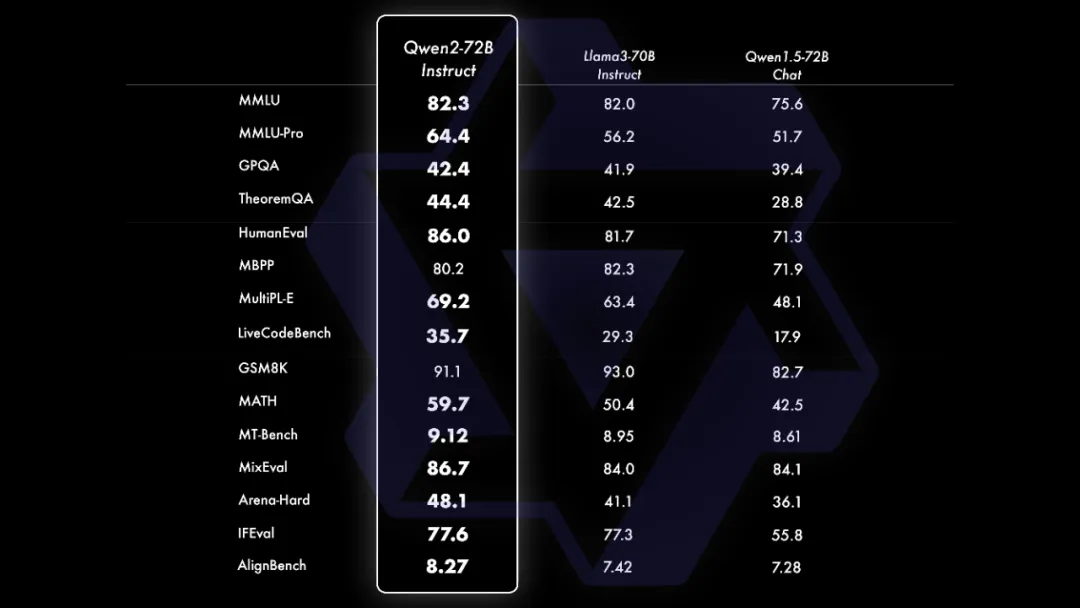
Qwen2-72B-Instruct 在 16 个基准测试中的表现优异,在提升基础能力以及对齐人类价值观这两方面取得了较好的平衡。相比 Qwen1.5 的 72B 模型,Qwen2-72B-Instruct 在所有评测中均大幅超越,并且取得了匹敌 Llama-3-70B-Instruct 的表现。而在小模型方面,Qwen2 系列模型基本能够超越同等规模的最优开源模型甚至更大规模的模型。相比近期推出的业界最优模型,Qwen2-7B-Instruct 依然能在多个评测上取得显著的优势,尤其是代码及中文理解上。
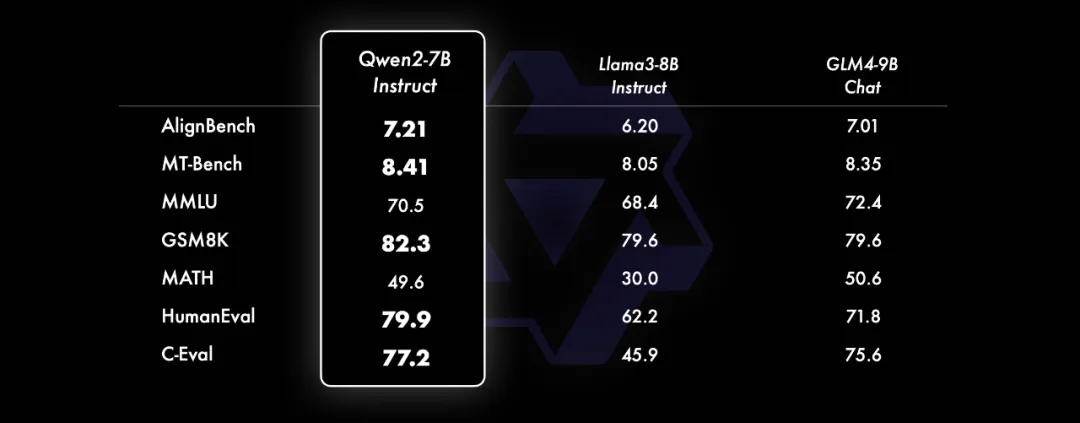
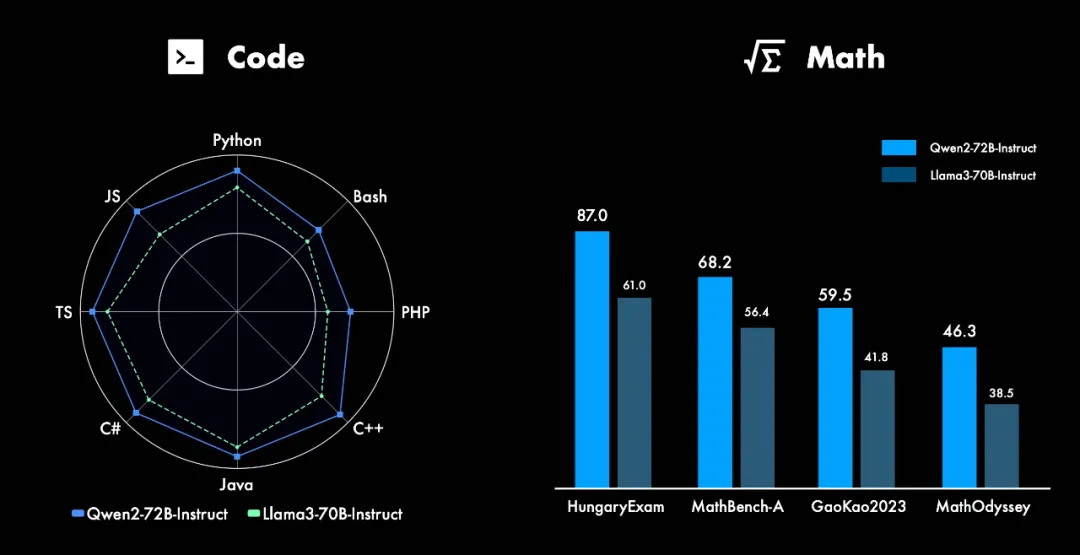
在代码方面,Qwen2 的研发中融入了 CodeQwen1.5 的成功经验,实现了在多种编程语言上的显著效果提升。而在数学方面,大规模且高质量的数据帮助 Qwen2-72B-Instruct 实现了数学解题能力的飞升。
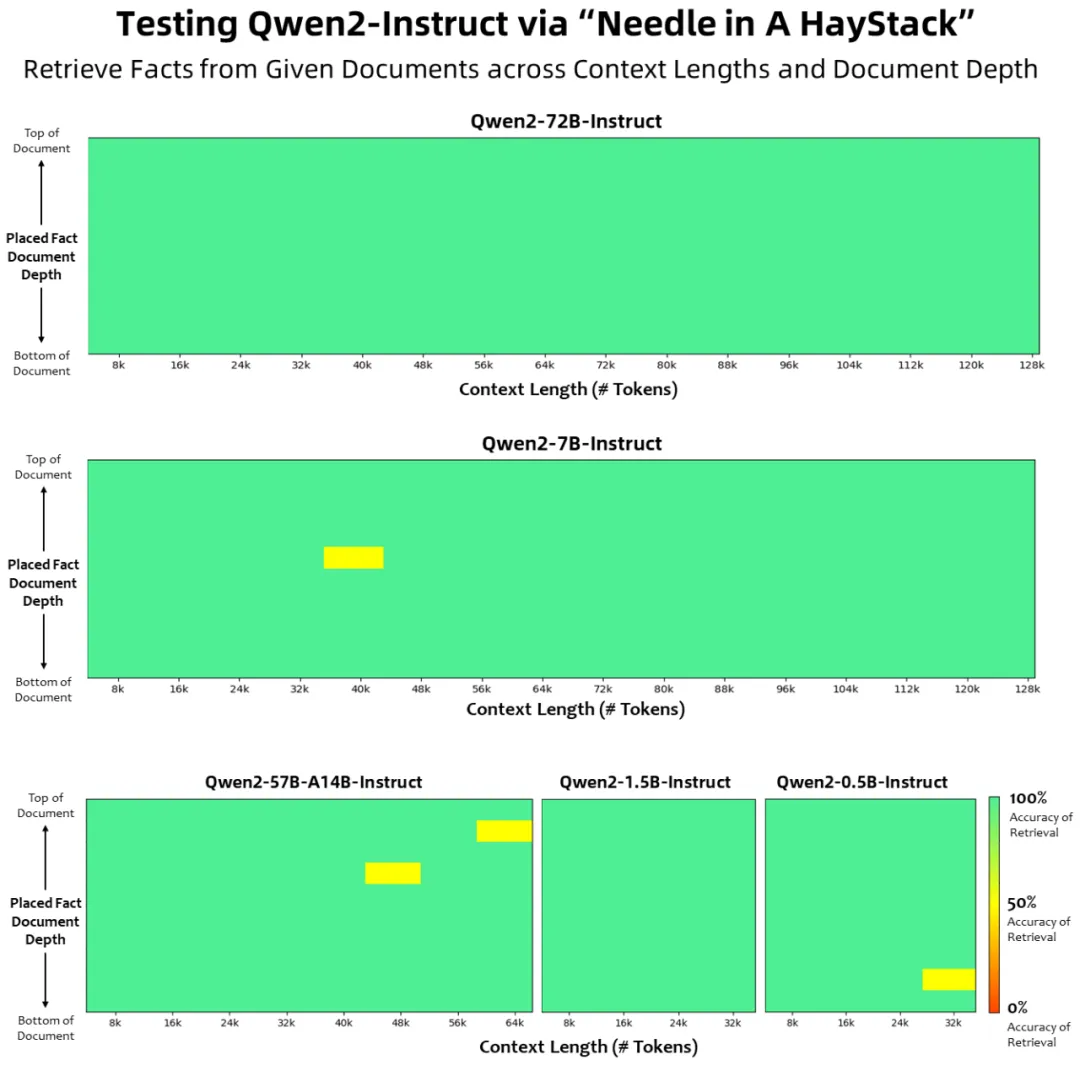
Qwen2 系列中的所有 Instruct 模型,均在 32k 上下文长度上进行训练,并通过 YARN 或 Dual Chunk Attention 等技术扩展至更长的上下文长度。下图展示了其在 Needle in a Haystack 测试集上的结果。值得注意的是,Qwen2-72B-Instruct 能够完美处理 128k 上下文长度内的信息抽取任务
此外,Qwen2 系列中的其他模型的表现也十分突出:Qwen2-7B-Instruct 几乎完美地处理长达 128k 的上下文;Qwen2-57B-A14B-Instruct 则能处理 64k 的上下文长度;而该系列中的两个较小模型则支持 32k 的上下文长度。
自 2023 年 8 月开源以来,通义千问不仅在国内开源社区中影响巨大,更是在全球开源社区中占据重要的位置。今日,Qwen2 系列模型的 API 第一时间登陆阿里云百炼平台。在 Llama 开源生态之外,全球开发者现在拥有了更多的选择。
参考链接:
https://qwenlm.github.io/blog/qwen2/
https://x.com/JustinLin610/status/1798747072319074347
文章来自于微信公众号 “机器之心”,作者 “大盘鸡”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
