# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
能够深入大模型内部的新评测指标来了!
上交大MIFA实验室提出了全新的大模型评估指标Diff-eRank。
不同于传统评测方法,Diff-eRank不研究模型输出,而是选择了分析其背后的隐藏表征。

该方法从信息论和几何的视角,分析大模型的隐藏表征,量化大语言模型在训练前后如何剔除数据中的冗余信息,并以此作为衡量模型性能的指标。
对于多模态大模型,研究团队也设计了基于秩的评估方法,用于衡量不同模态之间的对齐程度。
目前,本工作已被NeurIPS 2024接收。
在进行Diff-eRank的相关工作之前,作者首先提出了这样一个问题——
一个语言模型是如何从海量的训练数据中「学习」到知识的?
对于这个问题,前OpenAI科学家Ilya Sutskever在2023年的演讲中曾经这样说:
大语言模型海量数据中训练时,会逐步消除其表征空间中的冗余信息,使得数据的表征变得更加规整、结构化。
这个过程类似于「去噪」,即模型逐渐剔除数据中的无用信息,同时提取出更重要的模式和特征。
传统的评估方法多集中于模型在下游任务上的表现,例如准确率 (Accuracy) 、交叉熵损失 (Cross-Entropy Loss) 等指标。
但这些方法只关注模型的预测结果与标注标签之间的比较,无法深入探究模型内部的信息处理过程。
换言之,之前并没有研究提出可靠的指标来定义和量化这个「去噪」过程。
在此背景下,研究团队引入了有效秩的概念(Effective Rank,简写为eRank),用于反应大模型表征空间的不确定性或混乱程度。
这是一种基于模型表征的「有效秩」的评估指标,从信息论和几何学的角度分析并量化大语言模型在训练前后如何剔除冗余信息,并以此衡量模型性能。
大模型在训练时去除数据中的冗余信息,eRank减小,模型的表征变得更加结构化和紧凑。
因此,研究团队提出了Diff-eRank,通过分析大语言模型的表征的有效秩在训练前后的变化幅度,来评估大模型的「去噪能力」。
Diff-eRank提供了一个基于模型表征的全新评估方法,并且具有良好的理论基础与可解释性,为理解大模型的工作原理提供了独特的视角。
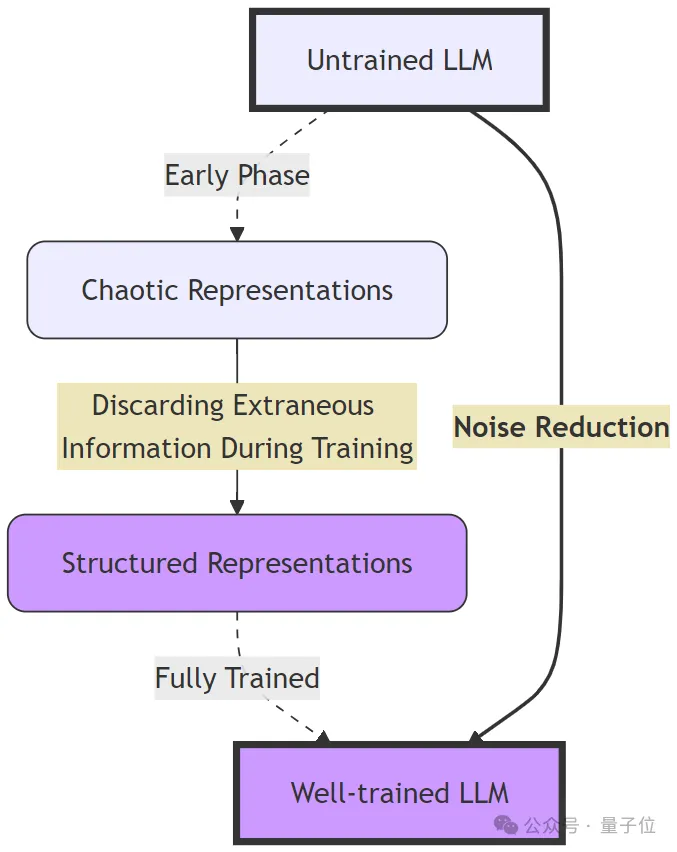
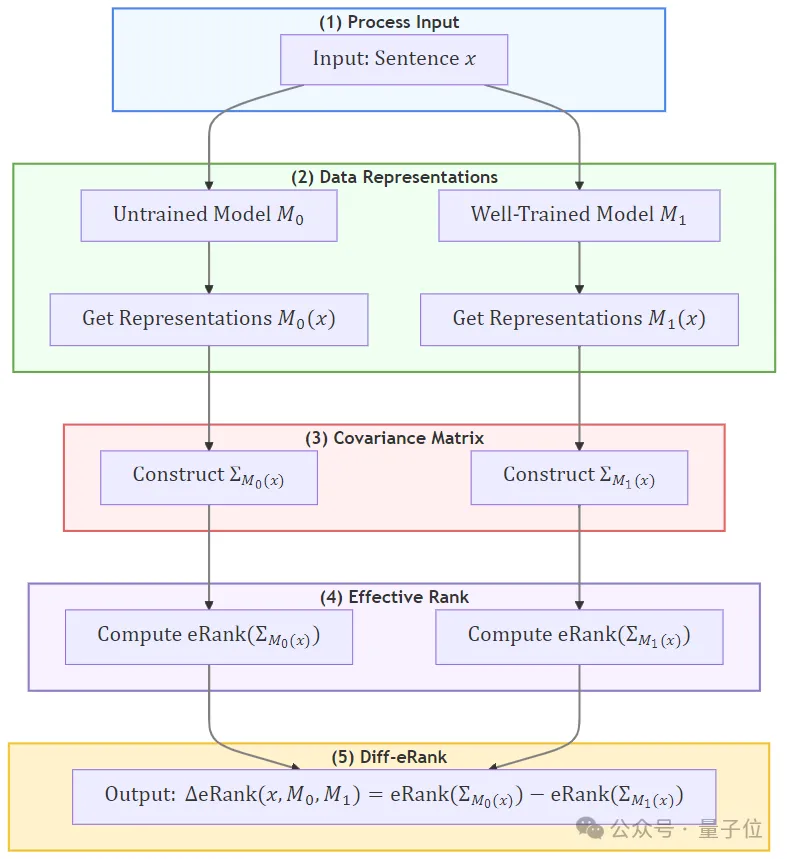
大模型在处理一系列输入时,它会为每个 token 生成一个高维表征。
这些表征通常可以捕捉输入的语义和句法信息。
因此,研究团队考虑分析这些表征来评估大模型的性能。
具体而言,团队选择从几何和信息论的角度研究这些表征的秩。
秩可以衡量它们这些表征的线性相关程度,对应于表征空间的有效维度(即几何结构)。
此外,秩还与这些表征所包含的信息量有关:较低的秩代表信息已被结构化或压缩。
因此,作者通过分析大模型表征的秩来进行模型评估。


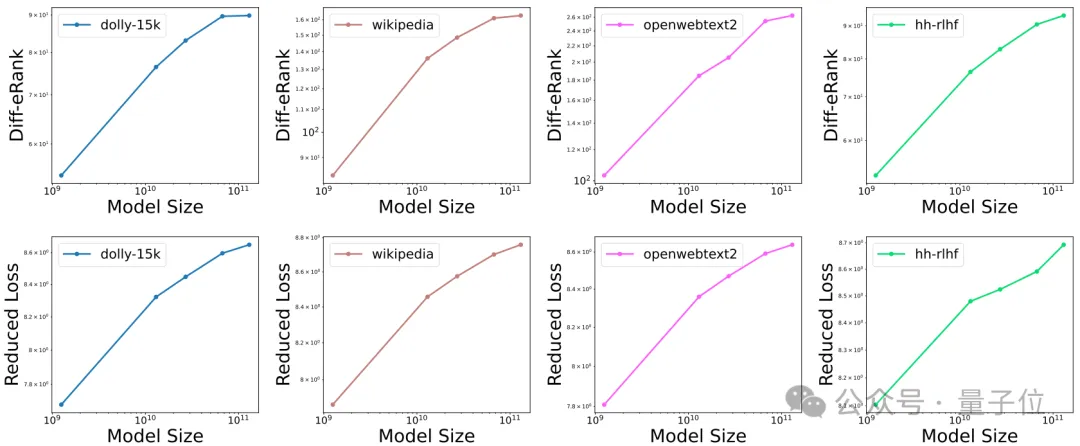
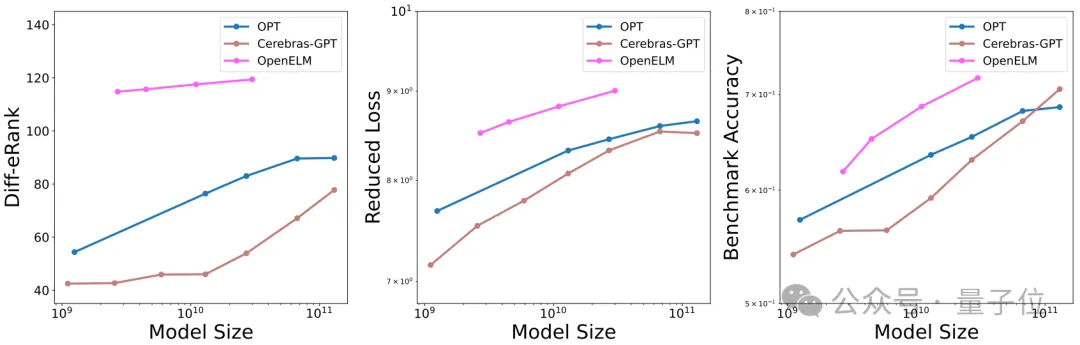
研究团队使用OPT模型家族,在多个数据集上计算了Diff-eRank。
由于损失(Loss)是最常用于观测预训练模型的指标,因此团队采用模型在训练前后交叉熵损失的减小量 (Reduced Loss) 作为对比。
作者在不同类型的数据集(如Wikipedia、openwebtext2、dolly-15k和hh-rlhf)上使用Diff-eRank和Reduced Loss对OPT模型家族进行了评估。
实验结果发现,Diff-eRank和Reduced Loss都随着模型规模的扩大而上升。
这一趋势说明更大规模的模型在信息压缩和冗余消除方面表现得更加出色。
这也体现了Diff-eRank可以从「去噪」角度为语言模型提供新的评估方法。
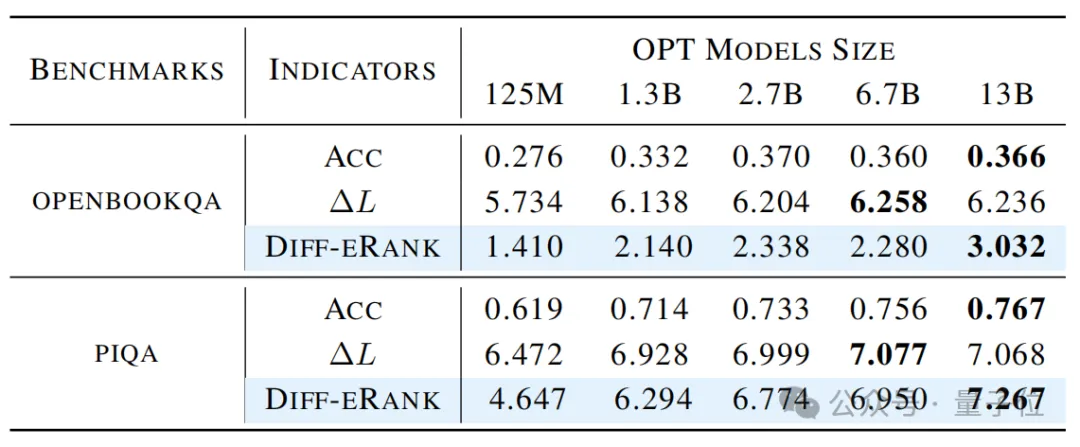
为了进一步验证Diff-eRank的有效性,作者在基准测试数据集上,引入准确率作为比较指标。
实验结果如下图显示,这三个指标在测试集上基本都在模型规模增加时变大。
而且与Loss相比,Diff-eRank与准确率的趋势更加一致,说明Diff-eRank可以有效地用于评估语言模型。
除了OPT之外,作者还用Cerebras-GPT和OpenELM家族进行了实验。
下图的实验结果体现 Diff-eRank 在不同模型家族中,都随着模型规模的上升而增加,并与 Reduced Loss 和基准测试准确率趋势相关,体现了 Diff-eRank 对不同模型家族的稳定性。
Diff-eRank背后的思想还可以拓展用于多模态大模型的评估。
例如,在视觉-语言多模态大模型中,可以通过借助表征的有效秩分析视觉和语言表征的匹配程度来衡量模型的模态对齐性能。
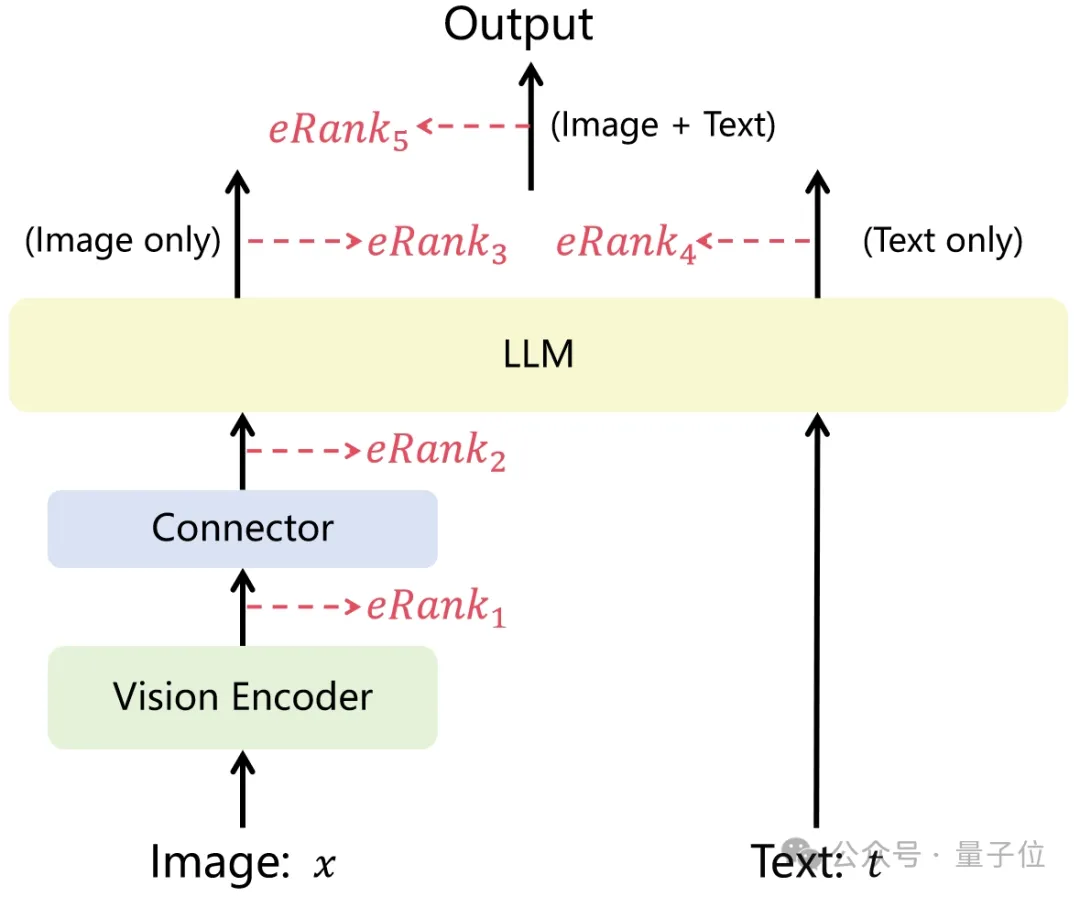
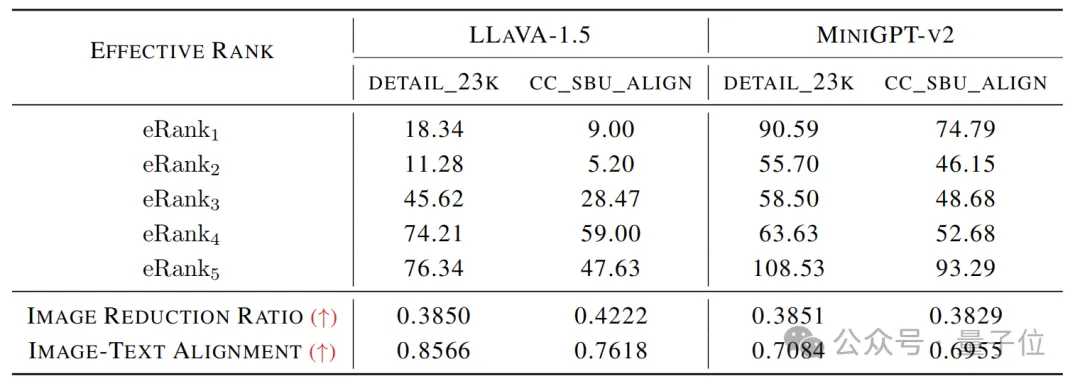
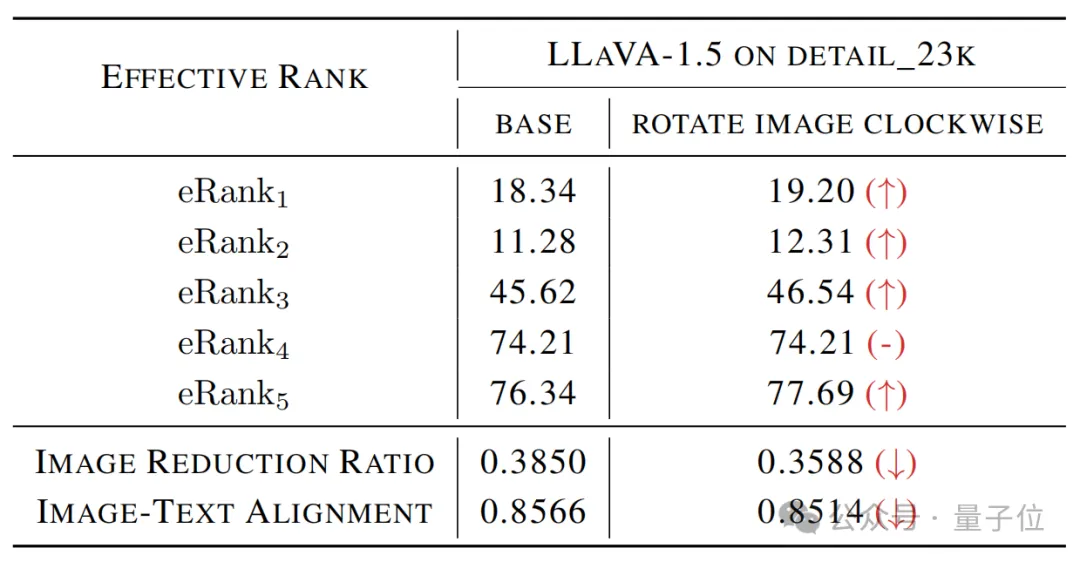
对于多模态实验,作者选择了两个最有名的开源多模态大模型:LLaVA-1.5和MiniGPT4-v2。
这两个多模态大模型都使用了一个简单的连接器来对齐视觉编码器与大语言模型。
作者在detail_23k和cc_sbu_align这两个高质量的多模态指令数据集上进行实验。
这些数据集中的每条数据都是由图像、指令和响应组成的三元组。
实验中,作者将每个三元组的指令和响应拼接作为文本输入。


Diff-eRank作为一种全新的评估指标,提供了一个独特的理论视角去理解和分析大模型的一种工作原理。
Diff-eRank不仅有助于评估大模型的「数据去噪」能力,还可能为模型压缩(如剪枝、量化、蒸馏等)等技术的发展提供新的视角。
比如,Diff-eRank或许有助于识别模型中哪些部分可以在不显著损失信息的情况下进行压缩。
作者期待,未来更多的研究者可以进一步拓展Diff-eRank的应用。

MIFA实验室全称Machine Intelligence Foundations and Applications Laboratory,即机器智能基础与应用实验室,隶属于上海交大清源研究院,负责人为黄维然副教授。
目前,MIFA 实验室和多所知名高校、国家实验室、三甲医院以及业界大厂保持着紧密的学术合作与交流关系。
本文共同第一作者为上交大MIFA实验室的博士生魏来和清华大学的博士生谭智泉,通讯作者为上海交通大学黄维然副教授,共同作者包括来自William and Mary的王晋东助理教授。
论文地址:
https://arxiv.org/abs/2401.17139
代码:
https://github.com/waltonfuture/Diff-eRank
文章来自于微信公众号 “量子位”



