# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
自2022年底ChatGPT发布以来,我们真正看到了大模型的威力,也引发了技术圈种种畅想。有相当一部分观点认为,大模型是一种工业革命级的产物,相信更多的人会和笔者一样,认为大模型是一个操作系统级的产品,会彻底地改变,甚至颠覆现有的,我们使用机器的方式。诚然现在的大模型仍旧是算力杀手,想要让它真达到操作系统的使用规模,可能在硬件上、推理架构上还有一段路要走,但其前景是显而易见的。
所以我们看到,自2023年年初起,各家大模型粉墨登场,卷能力,卷榜单,卷价格,卷参数,让人不禁想问,然后呢?从市场情况上看,大模型应用仍旧处于极早期的阶段,而从产品形态上来看,哪怕是步入了智能体的时代,大模型依然被限制在那个聊天框里面,使用起来仍是相对低效的,对用户来讲仍旧是不那么方便的,自然用户使用的方式也被限制住了。
即便如此,我仍然坚持认为,大模型应当是操作系统,那么,就让我讲讲现状,开开脑洞,畅想一下未来应当是什么样子的。
去年,笔者读了一本名为《跨越鸿沟》的书,里面讲了技术采用的生命周期 ,名为鸿沟理论。这一理论将用户分为5类,分别为:创新者、早期采用者、早期大众、后期大众、落后者。
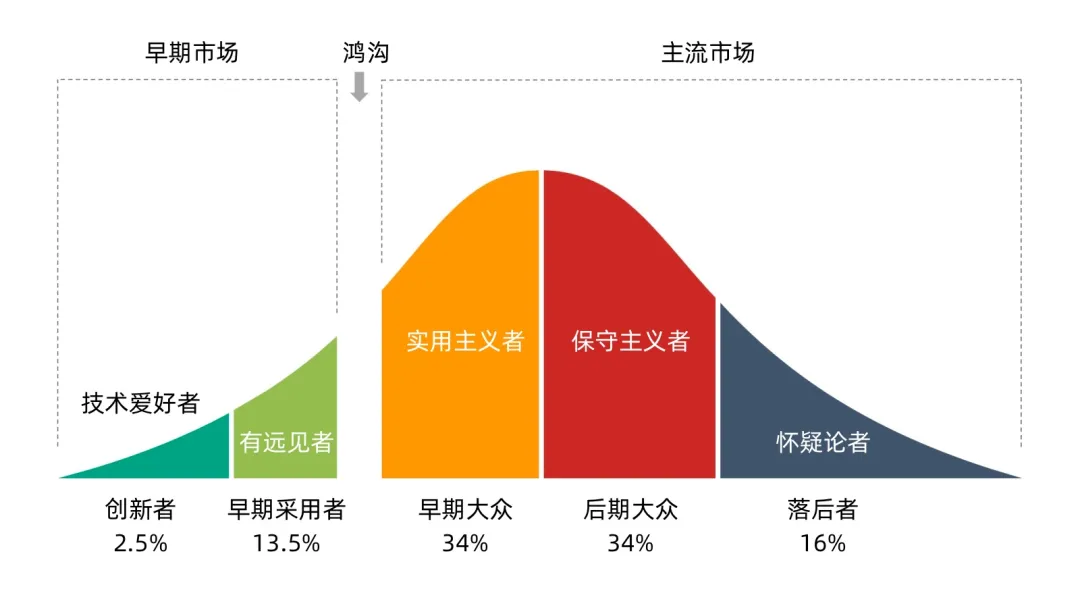
创新者热衷于一切比较新潮的技术,他们非常愿意尝试新鲜的事物,同时也对新技术的缺陷有着最大的包容,甚至愿意同技术开发者共同讨论优化这一技术。早期采用者则比创新者谨慎一些,他们如果相信这一技术未来会成为主流,早晚要拥抱它,才会去使用这个新技术,甚至为了新的特性,哪怕技术不够完善,也愿意用它去取代一些已有的东西,并提出这一技术应当怎么优化,成为一个好用的产品,所以他们也被称作有远见者。
这两批用户虽然很容易被吸引到,但也显然,相对于整个主流市场,他们的占比是很少的。
无论看当前用户的性质,使用的场景,还是单纯看数据,当前的大模型产品一定是处于极早期的,笔者判断,甚至可能没有突破到早期使用者。而主要原因,笔者认为就是当前的产品形态是相对低效的,或者说,当前大模型的产品形态、使用场景,远远达不到“操作系统级产品”的预期。
实际上,很多技术也是死在了前两批用户身上,从早期采用者到早期大众,实则是非常困难的。早期大众也被称作实用主义者,他们的特点是,新的技术形成的产品,得比现有的产品好用,让他们感觉到完成某一个任务变得更加方便,他们才会采用。而很多技术,从创新者和早期采用者那里得到的经验,极有可能是不适用于早期大众的。所以这一阶段,叫做“鸿沟”。
例如,笔者认为,大模型当前较主流的使用形态,即聊天框,是低效的,不符合大部分用户的使用习惯。或许我们应当去进一步探索,大模型怎么能真正渗透到日常的生活中。
顺带一提,正因当前大模型所处于的这一阶段,笔者认为,目前做大规模的投流一定是意义不大的,甚至可能损伤在早期大众用户中的第一印象。
算法圈的人一直说,自然语言是皇冠,搞定了自然语言,就搞定了人工智能。从原理上讲,自然语言里面的信息量是非常大的,毕竟这是我们为了描述这个世界,创造出来的符号化的表示了。但是又由于我们自身的不确定性,世界的不确定性,则注定自然语言本身也是不确定的,即我们是无法将自然语言转换成一套逻辑表示的。虽然,语言学的专家们提出了一种理想化的模型,起初是很简洁的,当然也就有了大量的反例,为了兼容现实情况,这种逻辑语言模型也变得无比的臃肿,无论形式上还是功能上都难以使用。
但是我们需要借助机器来做的,又大多是确定性的事情,哪怕现在有一些系统(例如人脸识别),没有达到100%的确定性,但是它能够快速识别很多张人脸,比人快,还比人准,记忆还比人强,那么其确定性就是高于人工的,实则还是对确定性的追求。这就意味着,机器需要的语言,或者指令,也应当是确定性的。起初,我们使用指令,或者代码来让机器完成工作,后来,进一步地,我们使用图形化界面,借助鼠标、键盘、触摸屏来让机器完成工作。
移动互联网为什么能够崛起,笔者认为,在绝大多数用户任务上,它有着不亚于PC的性能,但携带方便,随时随地可用,并且,触摸屏上多元的交互在一定程度上也比键盘鼠标更加方便(虽然有时候精确程度不如鼠标),上手成本还低得多,总之,它让用户在生活中变得更加的方便了,所以大部分用户接受了它。
那么我们回过头来看大模型,大模型最大的价值就是,它搞定了自然语言问题啊!它架设起了人与机器交流的桥梁,它能够将自然语言转换成为机器语言,这意味着,我们可能不必去适应机器的交互语言,而是让机器来适应我们的使用方式。当然,可能有的朋友会有疑问,推来推去,不还是说我要和机器直接说话吗?那聊天框不还是一个直观的方式吗?
不是的,自然语言是我们描述这个世界的方式,那么我们很多日常行为所带来的意图,是否都可以用自然语言来表示呢?那么,大模型最为这样一个中枢,是可以大大简化我们和机器的交互的。更进一步想,一个充分学习了我的习惯的大模型,是不是能更好地充当我的个人助理,我可以不需要设置确定的指令,只是我说要干什么,它就能够帮我处理好很多事情,达到我的意图。
可能还有的朋友要问,现在大模型达到了那个能力吗?
其实我们想想,我上面开的这两个脑洞,实际上都是多阶段的,每一阶段其实都是很简单的命令,现在的大模型理解这种简单的命令,笔者是相当有信心的。真正有考验的,其实是记忆能力,以及对已有记忆的注意力,也就是说,我需要的是过往交互中哪一轮的信息,大模型是需要能够精准识别的。
事实上,人和人交流的时候,应当是不会写那么“不是人话”的复杂指令的,或者那么一长串的prompt,因为人也听不懂,也记不住(短时记忆空间根本没法支撑那些信息量,肯定得反复澄清),更多的还是一步一步培训,让人形成习惯,为什么到了比人弱一些的大模型(确切说,大模型的确在文本的阅读能力和“短时记忆”能力上一定程度是超过人的,但是理解能力嘛……),就一定要一轮就让模型精准完成需求呢?
所谓“重构,而不是整合”,我想应当是包含这种意思,也指明了大模型优化的方向。
所以回过头来看,大模型为什么非得像人呢?为什么要执着于做一些人在做的,非常终端的事情呢(比如画图、做视频)?为什么要参加高考呢?为什么要卷考卷呢?为什么要做数学题呢?为什么要搞那些形式逻辑呢(这本身就不是非确定性问题,大模型是搞不定的,人类其实不借助工具也无法搞定)?以及,为什么要做人形的机器人呢?
当然,前面笔者一直说聊天框是低效的,但它不是没有价值的,它是我们直接和大模型交互的媒介,就如同操作系统的终端,我们可以通过它直接让大模型去执行一些指令,去观察它的能力。
最后就聊到了对当前agent现状的思考。我认为agent是基于大模型原始形态,向下一步的早期探索,其试图将一些用户任务标准化,将用户的需求转换成一个自动化的指令序列,来完成一些事情。并且agent这种形式应当是实现笔者上文所开的那些脑洞的必经之路,就如同在终端中调试代码一样(人人都是程序员,应该也是这个意思)。
不过,这也意味着,agent目前的探索不应当被当前用户的使用场景所裹挟,而是应当扩展到更加广大的领域,所以写这样一篇东西,笔者也是希望,能够扩大agent的范围,最终真的能催生出AI原生这个广大的生态。
去年OpenAI DevDay上,发布了GPT Store,当时笔者的言论是,他们的这个发布,看上去是让竞争对手们松了一口气的,因为它只是在预期内发布了那么一个东西,或者说它需要搞出来什么事情,但没有什么横空出世。这或许意味着,ChatGPT真的是一个意外的产物,而我们作为后来者,不能因为OpenAI是领头羊,就被它的开发思路裹挟了。现在或许也验证了笔者当初的想法。
我是真心希望,我们能够作为大模型产品的领头羊,创造出下一个奇迹。
文章来自于微信公众号“夕小瑶科技说”,作者“Severus”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
