# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
高效组合多个大模型“取长补短”新思路,被顶会NeurIPS 2024接收。
名为RouterDC,是一种基于双重对比学习的路由架构,具有参数高效性(小于100M的参数)和计算高效性(不需要对于LLM进行梯度回传)的优势。
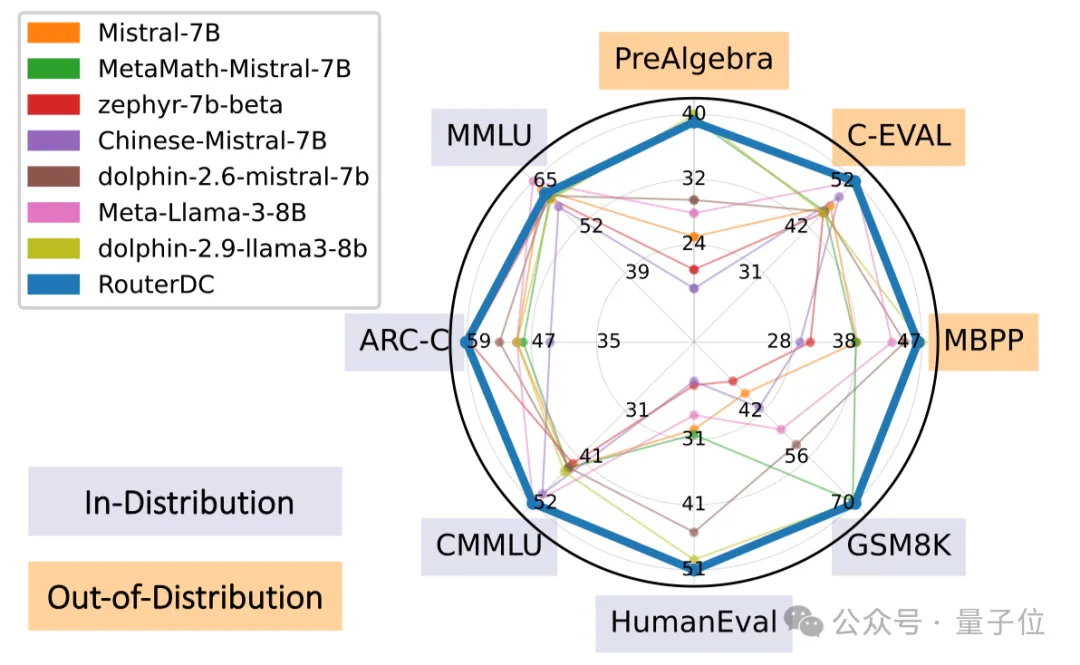
在具有挑战性语言理解、代码生成和数学推理等推理任务实验中,RouterDC在分布内(+2.76%)和分布外(+1.90%)设定下,都远超于现有的routing方法。
众所周知,LLM通常在不同数据集上预训练和微调,导致它们在不同任务上的性能强弱不同。
LLM路由则是一种组合多个LLM的新思路,它通过学习一个路由器(Router)来为每一个请求(query)选择最合适的LLM。在推理时,LLM路由只需要调用所选的LLM进行推理,使其在保持计算高效性的同时利用多个LLM的互补能力。
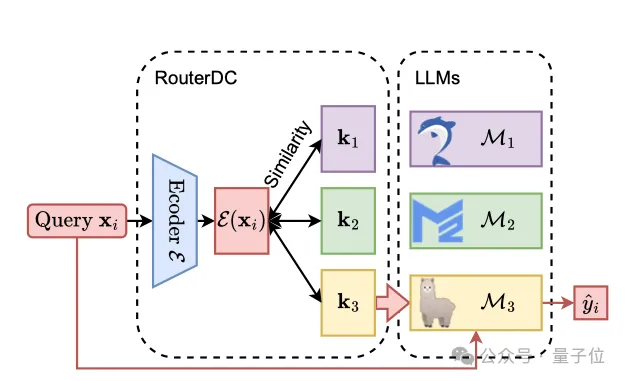
RouterDC这种新方法,包括一个较小的语言模型作为编码器和一系列与候选LLM对应的可学习的LLM embeddings。
对于训练数据中的每个query,首先将候选LLM的预测与真实标签进行比较获得表现最好和最差的LLM,然后构造两个对比损失:
这项研究由来自南方科技大学,香港科技大学的研究团队提出,以下是更为详细的介绍。

Router架构
如图1所示,RouterDC包括一个较小的语言模型(mDeBERTaV3-base)作为编码器ε,和一系列的与候选LLM对应的可学习LLM嵌入kT。对于每个query xi,RouterDC生成对于T个LLMs的选择概率如下:
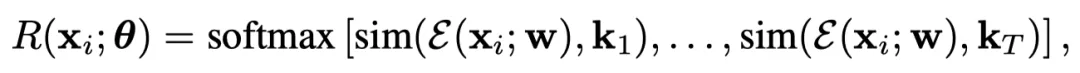
其中,sim(·,·)表示cosine相似度。
sample-LLM对比损失
为了训练router,研究者将query的样本嵌入和在其上表现最好的K+个LLM对应嵌入拉进,和在其上表现最差的K-个LLM对应嵌入拉远。因此,样本-LLM对比损失可以表示为:
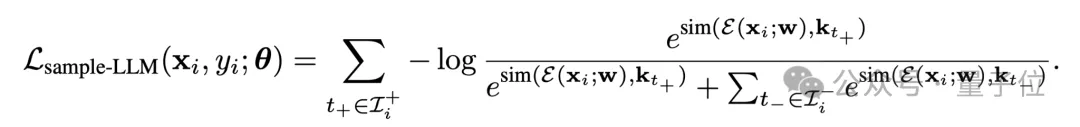
sample-sample对比损失
研究者通过实验发现,在routing问题中只使用样本-LLM对比损失并不稳定,使得相似的query可能具有不相似的嵌入。
为了提升训练的鲁棒性,训练样本被聚类成不同的组,从而在训练中拉近同一个组内的样本,拉远不同组的样本。和样本-LLM对比损失类似,样本-样本对比损失可以公式化为:
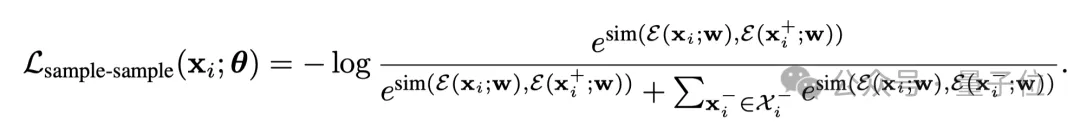
训练及推理
最终的优化目标为最小化样本-LLM对比损失和样本-样本对比损失的结合:
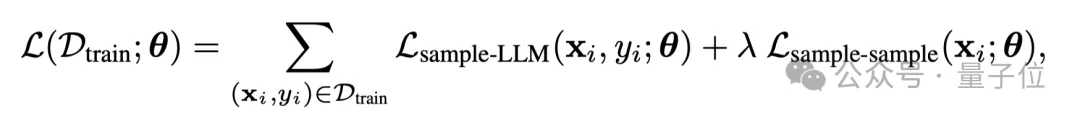
推理时,每个测试query只需要通过训练好的router选取概率最大的LLM,并使用选择的LLM对query进行回答。
RouterDC在训练时不需要任何经过LLM的梯度回传,并且在推理时只需要调用进行一次LLM,同时具有训练和推理的高效性。
主要结果
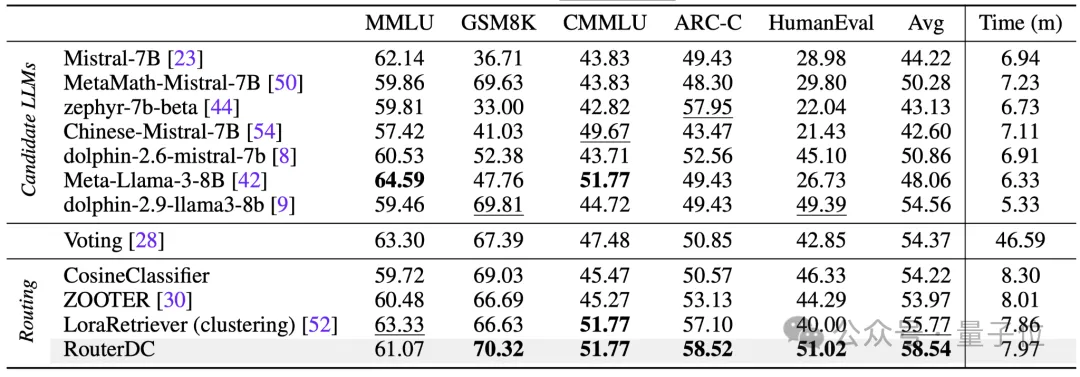
RouterDC在分布内数据集的测试准确率结果如表1所示。可以发现:
RouterDC显著好于最优的单个模型,平均具有3.98%性能提升。在单个任务的层面,RouterDC在三个任务上相比表现最优的单个模型取得了准确率的提升,其中GSM8K提升了0.51%,ARC-C提升了0.57%,HumanEval提升了1.63%。
和现有路由方法CosineClassifier以及ZOOTER对比,RouterDC在所有任务上都具有更好的表现。和LoraRetriever对比,RouterDC具有平均2.77%的准确率提升。
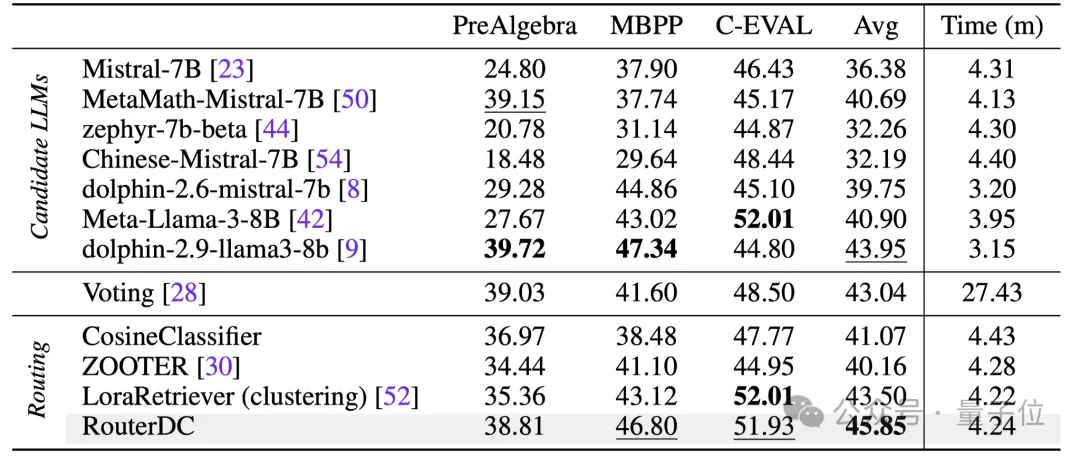
为了评估RouterDC的泛化能力,表2展示了RouterDC在三个分布外数据集(PreAlgebra,MBPP,C-EVAL)的测试准确率。
可以看出,RouterDC再次达到最高的测试准确率,显著超过表现最佳的单个LLM(dolphin-2.9-llama3-8b)1.9%。
sample-sample损失的作用
为了探究样本-样本损失的作用,图3展示了在是否有样本-样本损失的条件下训练和测试准确率曲线。可以看出,RouterDC(w/o Lsample-sample)有明显的震荡现象,而RouterDC则稳定得多。
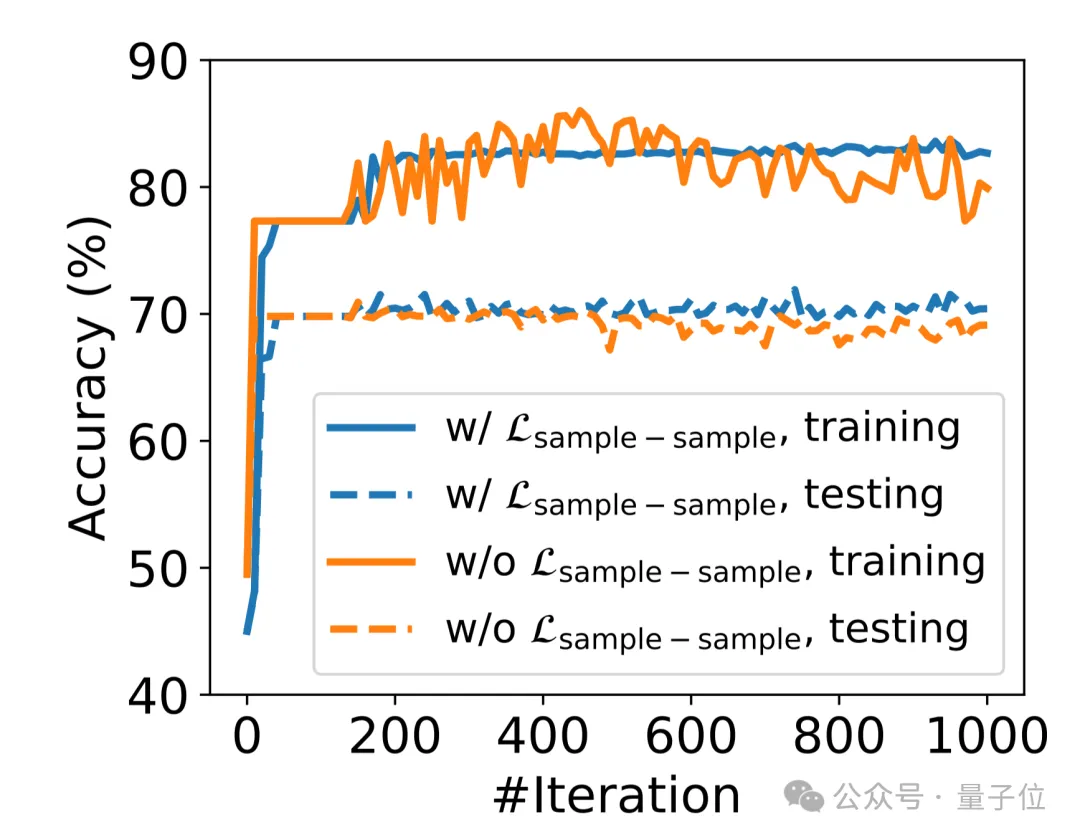
图2:RouterDC在GSM8K任务上的训练和测试准确率曲线
图3(a)可视化了使用RouterDC(w/o Lsample-sample)提取的训练样本的TSNE特征,可以看到,属于不同任务的训练样本粗略地混合在一起。而在结合Lsample-sample之后,训练样本有了清晰的聚类结构(如图3(b)所示)。
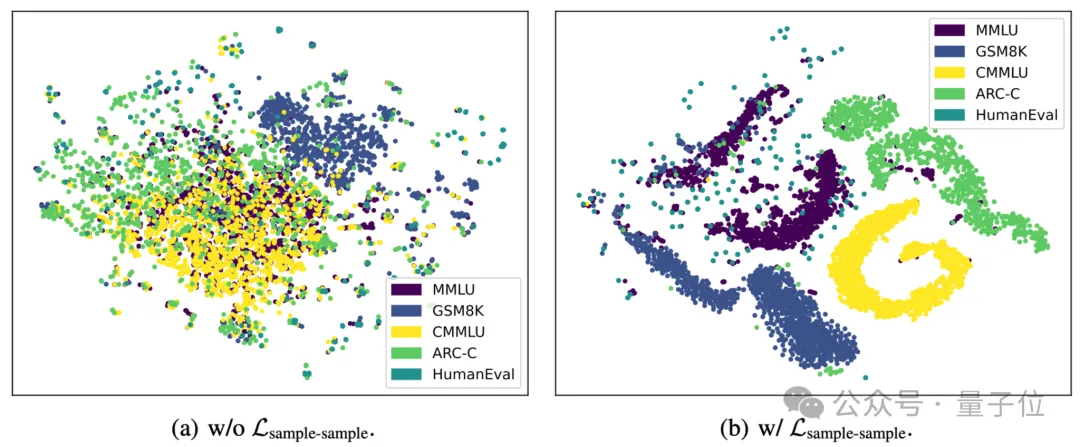
图3:学习到的router所提取出训练样本embedding的t-SNE可视化
RouterDC具有成本高效性
由于价格(cost)同样是一个评估LLM的重要指标,研究者通过RouterBench上的两个任务的实验来格外考虑cost的影响。如图16所示,RouterDC相比于CosineClassifier和ZOOTER更加的成本高效。
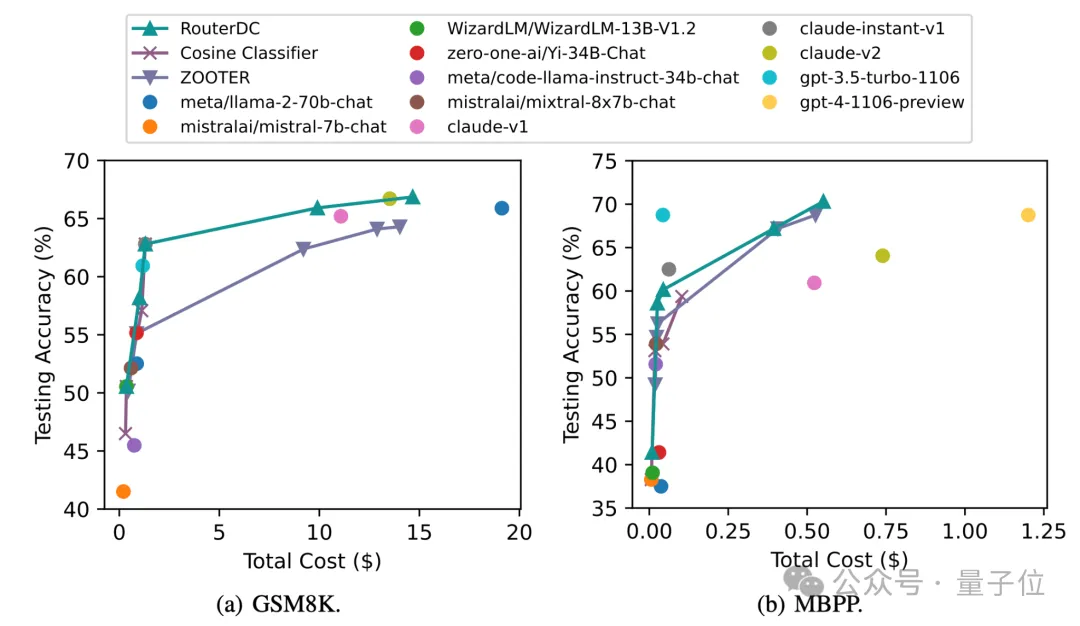
图4:在RouterBench上使用不同的Cost获取的测试准确率
论文地址:https://arxiv.org/abs/2409.19886
代码地址:https://github.com/shuhao02/RouterDC
文章来自于“量子位”,作者“RouterDC团队”。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
