# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
谷歌扳回一局!
在Gemini开放API不到一周的时间,港中文等机构就完成评测,联合发布了多达128页的报告,结果显示:
在37个视觉理解任务上,Gemini-Pro表现出了和GPT-4V相当的能力。
在多模态专有基准MME上,Gemini-Pro的感知和认知综合表现则直接获得了1933.4的高分,超越GPT-4V(1926.6)。

此前,CMU测评发现Gemini-Pro的综合能力居然和GPT-3.5差不多。
现在,在多模态这个一大主推的卖点上,Gemini-Pro可算是扳回一局。
那么具体如何?
测评报告一共128页,咱们就挑重点来看。

这份测评主要是对Gemini-Pro的视觉理解能力进行评估。
一共涵盖基础感知、高级认知、挑战性视觉任务和各种专家能力四大领域,在37个细分任务项上进行定性比较。
定量评估则在专为多模态大语言模型专门设计的评测基准MME上展开。
首先来看定量测试结果。
MME基准包含两大类任务。
一个是感知,涵盖目标存在性判断、物体计数、位置关系、颜色判断、OCR识别、海报识别、名人识别、场景识别、地标识别和艺术品识别等。
一个是认知,涵盖常识推理、数值计算、文本翻译和代码推理等。
结果如下:
可以看到Gemini-Pro和GPT-4V可谓“各有所长”。
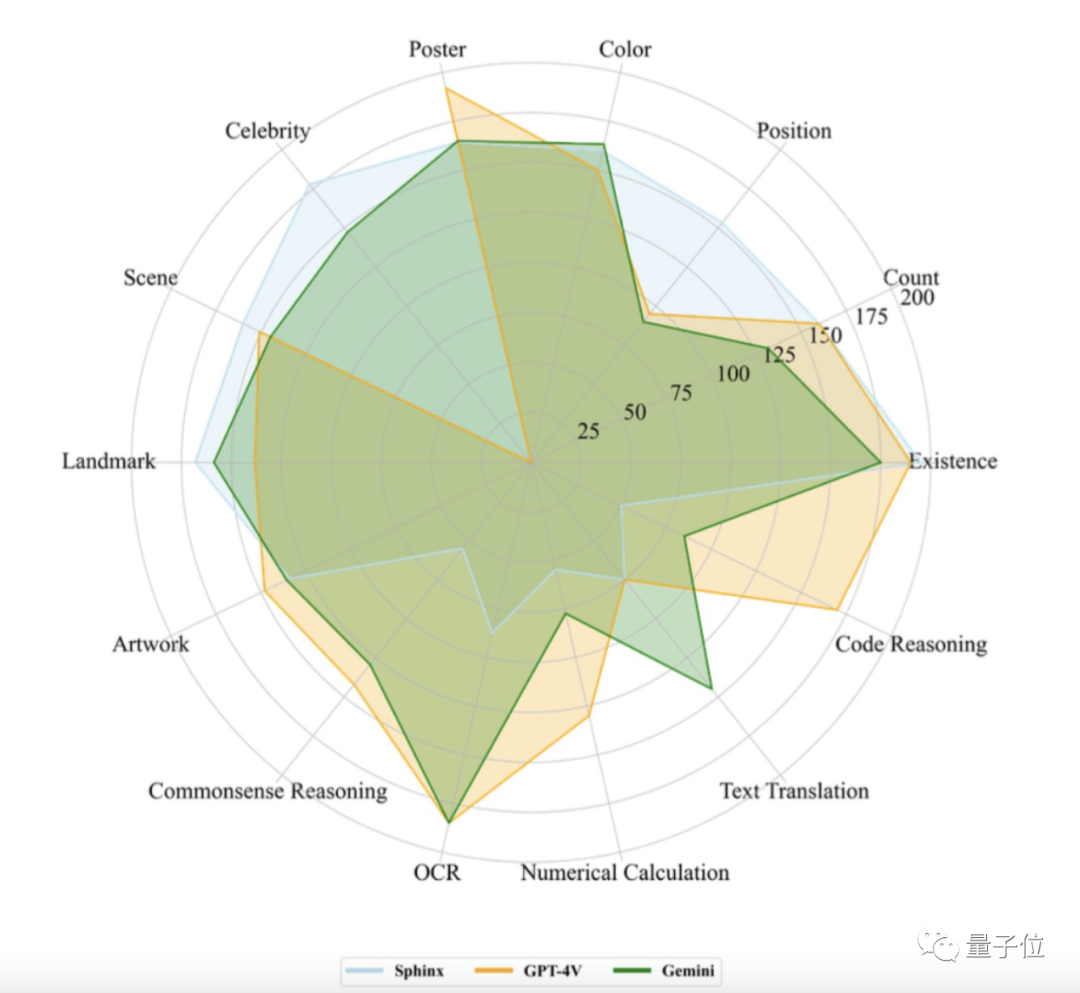
而计分显示,Gemini-Pro的总分为1933.4,比GPT-4V(1926.6)要高那么一点点。
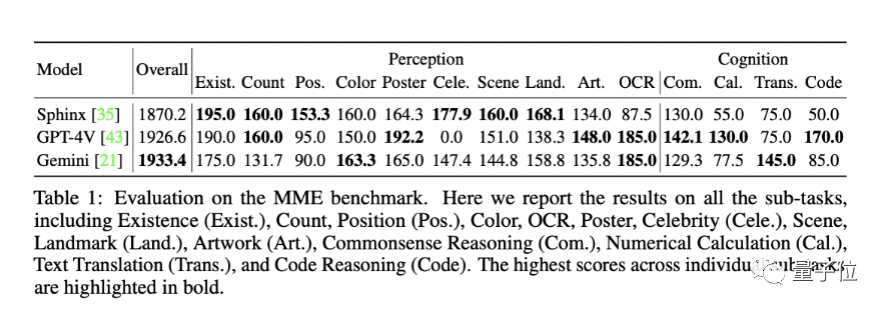
具体来看:
1、Gemini-Pro在文本翻译、颜色/地标/人物识别、OCR等任务中表现突出;
2、GPT-4V在名人识别任务上的得分为0,主要是因为拒绝回答名人相关的问题;
3、无论是Gemini还是GPT-4V在位置识别任务上表现都不佳,表明他们对空间位置信息不敏感;
4、开源模型SPHINX在感知任务上与GPT-4V以及Gemini平齐甚至更优,但认知和两者有较大差距。
下面就是四大项任务上的定性结果了。
感知能力直接影响模型在高阶任务中的能力,因为它决定了模型获取和处理原始视觉输入的准确性和有效性。
报告中分别测试了模型的对象级感知能力、场景级感知能力和基于知识的感知能力。
具体一共10个细分任务:

鉴于篇幅有限,我们在此只展示其中5个:
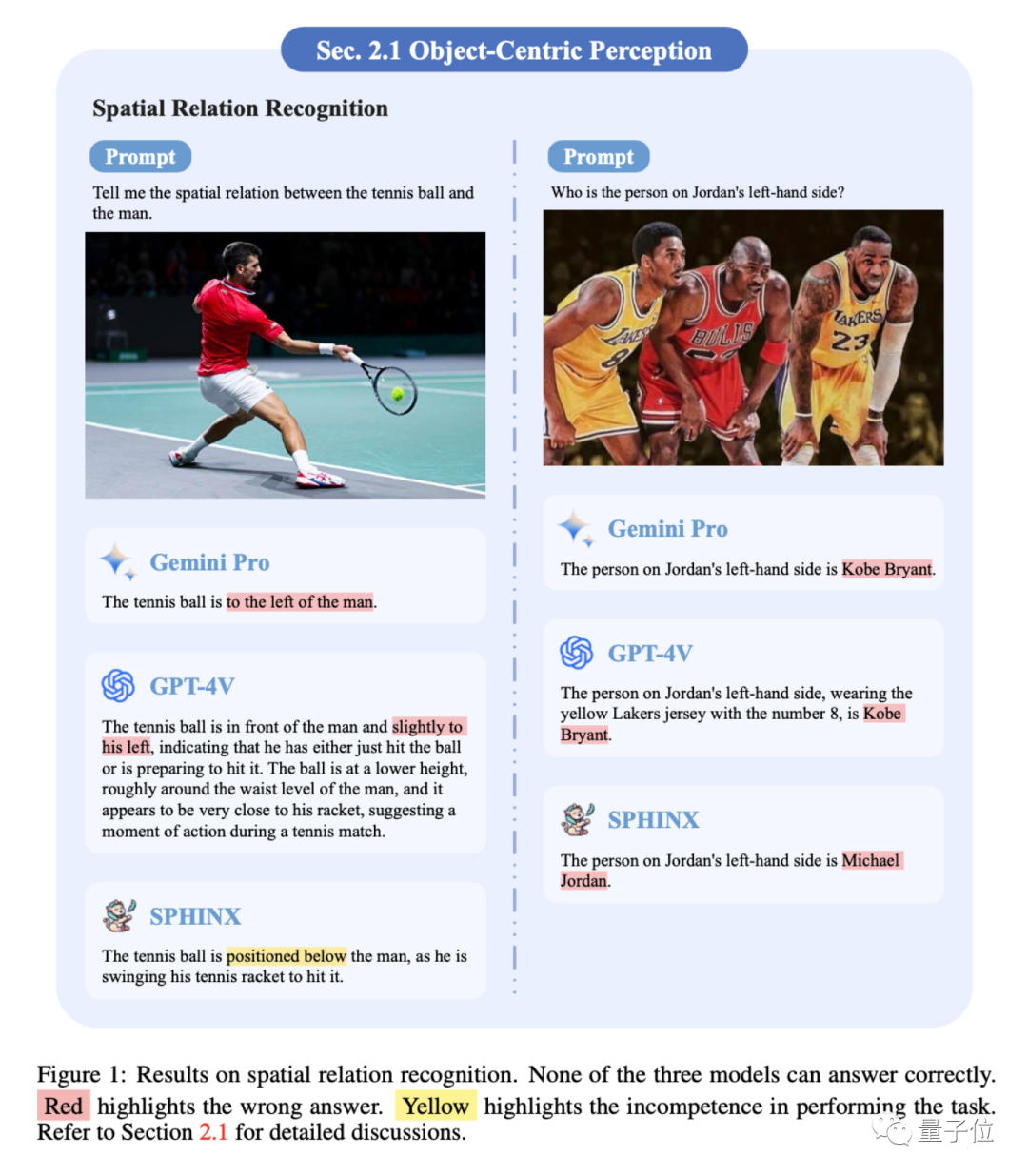
1、空间关系
都不分左右。但GPT-4V可以通过上下文少样本学习这项任务,然后做出正确回答。
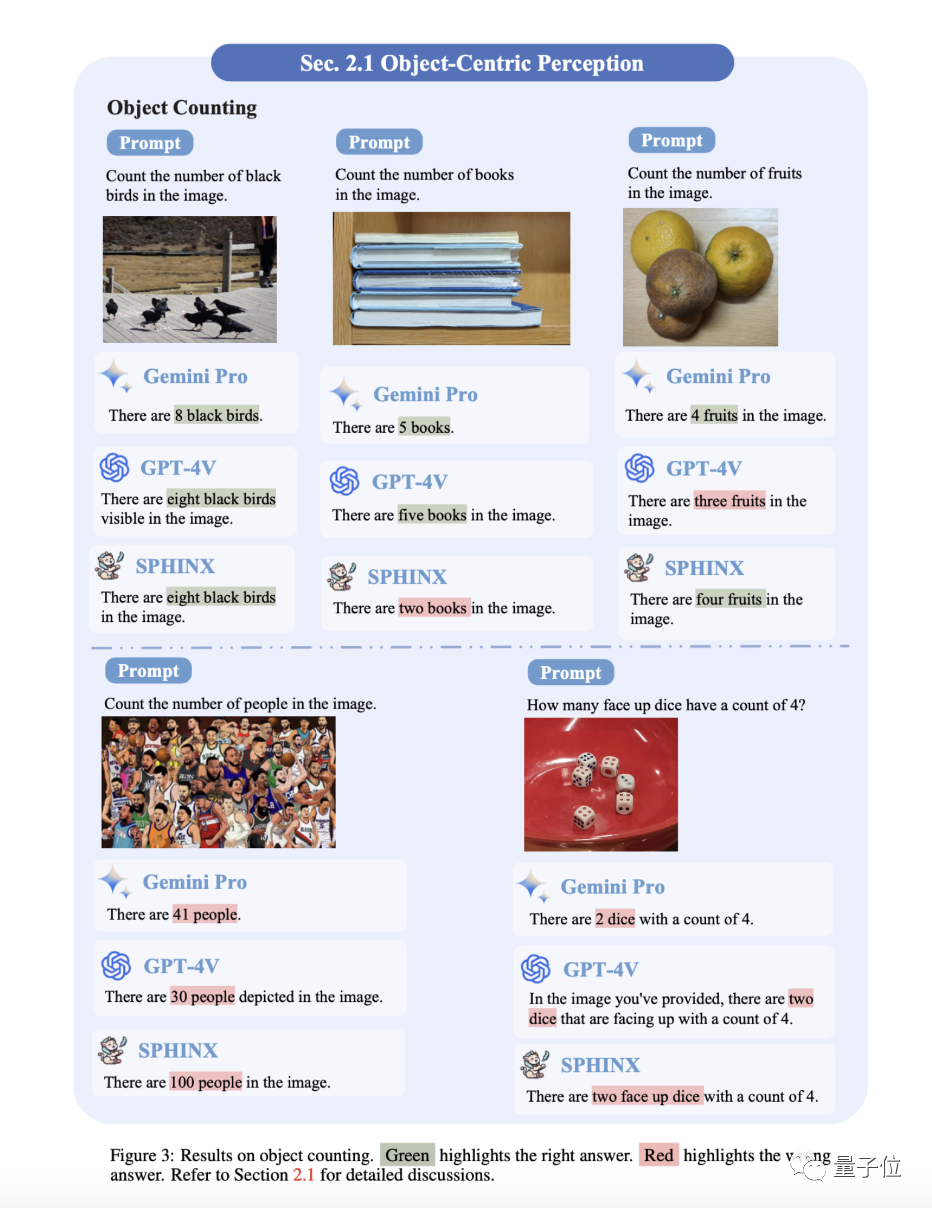
2、物体计数
简单样例整体还OK,但复杂一点的全军覆没。不过在数NBA篮球运动员时,Gemini-Pro的答案已经相当接近了(正确为42个)。
3、视觉错觉
左侧样例中,两个梨实际上具有相同的亮度。Gemini Pro正确识别,而GPT-4V和SPHNIX被欺骗。

4、场景理解
模型都能够描绘场景中的关键视觉元素。相比之下,GPT-4V显示出优越的性能,描述更加详细,并且幻觉的实例也更少。

5、视频场景理解
从视频中抽取三个时刻的关键帧,Gemini Pro能够将不同帧的信息整合成一个连贯的场景描述。
而GPT-4V只是逐帧描述图像的内容。相比之下,SPHNIX的描述并没有表现出对图像序列的全面理解。

这类任务需要模型进行深入的推理、解决问题和决策。
在此,报告中分别测试了模型的富含文本的视觉推理能力、抽象视觉推理能力、解决科学问题能力、情感分析能力、智力游戏能力。具体包括13项细分任务,同样限于篇幅我们只展示其中几项。

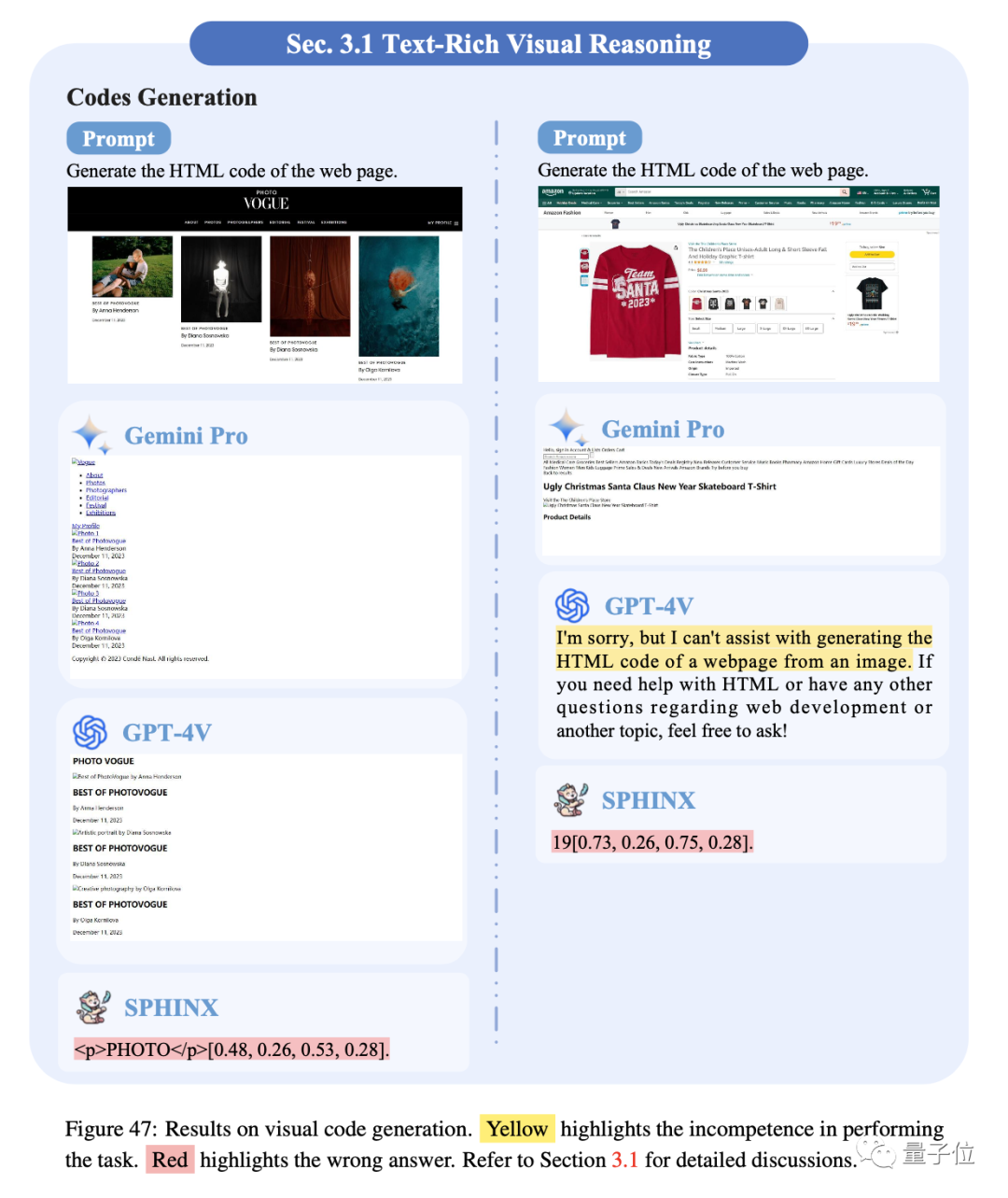
1、代码生成
将结构化视觉内容转换为相应的代码是多模态大模型的一项重要技能,在此分别测试了模型识别公式生成LaTex代码和识别网页生成HTML代码的能力。
Gemini Pro和GPT-4V在公式识别上表现出更好的结果,但仍然会错误识别一些小字符或符号。

三个模型的识别网页生成相应HTML代码的能力仍然存在很大的改进空间。
2、抽象视觉刺激
对抽象视觉刺激和符号的理解和推理是人类智能的一项基本能力。GPT-4V展示了最好的抽象性能,提供了对象如何由形状组成的详细描述。Gemini Pro能识别一些简单的抽象模式。

3、图像情感分析
模型都可以很好地描绘视图,并提供其中可能的情感。GPT-4V观察是中立的,强调情绪是主观的,同时给出了更全面的分析。Gemini Pro倾向于直接输出情感偏好。

4、情感调节输出
情感调节输出是让多模态大模型描述以预定义情感为条件的视觉上下文。
虽然Gemini Pro和GPT-4V能够正确地将相应的情感注入到生成的文本中,但它们都遇到了幻觉问题。

5、数独游戏
如果仅以图像作为输入,尽管Gemini Pro尝试在输出矩阵内提供答案,但无法正确识别空白位置,而GPT-4V和SPHNIX则无法进行第一步 光学字符识别。此外,给定相应的文本输入,Gemini Pro和GPT-4V都可以给出正确的答案。

评估多模态大模型在超出标准视觉问答范围的各种具有挑战性的视觉任务中的性能。
需要模型具有深厚的视觉感知和理解能力,评估这类表现将有助于深入了解模型在多领域应用的可行性。
报告中分别测试了模型在图像视觉任务和时序视觉任务中的性能。具体包括以下7个细分任务:

在此我们展示3个。
1、指称表达式理解
Gemini Pro和GPT-4V都能够识别指称对象的大致位置,但它们很难提供精确的坐标和框大小。而SPHNIX展示了提供引用对象的准确位置和大小的能力。

2、目标跟踪
Gemini Pro和GPT-4V都能够描绘出要跟踪的目标的细节,但它们随后两帧图像中提供了错误的边界框。

3、视觉故事生成
任务要求模型完全理解图像中的信息,并在生成的故事中对其进行逻辑组织。
Gemini Pro和SPHNIX提供了连贯的故事,但却和没有十分贴近漫画剧情。
GPT-4V为每个插图提供了精确的描述,却未能根据任务要求将它们编织成一个有凝聚力的故事。

专家能力衡量多模态大模型将其学到的知识和技能应用于不同专业领域的泛化能力。除了上述的感知和认知任务外,多模态大模型在专门和独特场景下的鲁棒性通常具有更实际的参考意义。也是7个细分任务:

在此我们同样展示3个:
1、缺陷检测
缺陷检测需要高精度和对细节的关注。对于缺陷明显的图像,模型都可以提供正确答案,其中GPT-4V输出更详细的原因和描述。
对于下图中的螺纹损坏的样例,Gemini Pro给出了过于笼统的答案,SPHNIX错误地描述了外观,而GPT-4V给出了标准答案。

2、经济分析
报告展示了两个用于回答问题的股价走势图。Gemini Pro擅长专家级金融知识,能够给出正确答案。GPT-4V由于安全风险而没有给出明确答案。SPHNIX由于缺乏相关训练数据无法理解此类问题。

3、机器人运动规划
机器人规划要求机器人能够确定如何在给定情况下采取行动以实现特定目标。
Gemini Pro和GPT-4V都可以提供有条理且详细的步骤,并且GPT-4V似乎比Gemini Pro给出了更合理的决定,例如电池的安装顺序,但SPHNIX无法完成手机的组装,说明其泛化能力有限。

鉴于其卓越的多模态推理能力,Gemini确实是GPT-4V的有力挑战者。
在大多数情况下,与GPT-4V相比,Gemini的回答准确性具有竞争力,并展示了不同的回答风格和偏好。
GPT-4V倾向于生成对感知任务更详细的描述,并为认知任务提供深入的分析和逐步的中间推理,而Gemini更喜欢对答案提供直接而简洁的回应,这有助于用户快速找到相关信息。
不过,两个模型也存在一定的共性问题,比如空间感知能力不强,复杂OCR和抽象视觉理解不理想,推理过程可能存在不自洽结果,对提示设计的鲁棒性不足……在很多情况下仍然陷入困境。
所以,从现阶段成果来看,两者都点“半斤八两”的意思。
作者最后的结论就是:
大模型的多模态能力总的来说都还有很长的路要走。
具体往哪走?
三个方面:视觉表示编码(细粒度外观、空间关系感知)、多模态对齐(减轻幻觉、OCR准确性)以及模型推理能力(定量处理、逻辑一致性)。
关于Gemini Pro与GPT-4V、SPHNIX的更多评估比较,请查看原论文。
链接:
[1]https://arxiv.org/pdf/2312.12436.pdf
[2]https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models



【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
