# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
团队的共同一作林之秋(Zhiqiu Lin)是卡内基梅隆大学的博士研究生,由Deva Ramanan教授指导,专注于视觉-语言大模型的自动评估与优化。团队的马紫晛(Zixian Ma)是华盛顿大学的博士研究生,由Ranjay Krishna教授指导,专注于视觉-语言大模型的评测以及与人的交互。
在诸如 MME、MMBench、MMMU 和 ScienceQA 等复杂的视觉问答(VQA)基准上,GPT-4o、Qwen2-VL 等视觉语言模型已经取得了显著进展。然而,这些模型真的理解自然图像吗?
近日,卡内基梅隆大学与华盛顿大学的研究团队推出了 NaturalBench,这是一项发表于 NeurIPS'24 的以视觉为核心的 VQA 基准。它通过自然图像上的简单问题——即自然对抗样本(Natural Adversarial Samples)——对视觉语言模型发起严峻挑战。

视觉语言模型(VLMs),如 GPT-4o、BLIP-3、LLaVA-OneVision、Llama3.2-Vision、Molmo 和 Qwen2-VL,在 MMMU 和 MME 等复杂视觉问答(VQA)基准上表现出色。这些基准涵盖了大学课程、常识推理、图表理解,以及数学、编程、物理和时序预测等任务。
然而,研究团队发现,这些模型在应对自然图像中的简单问题时仍存在不足。下图展示了人类能轻松解答的 VQA 示例,但即使是最先进的模型也常会出错,研究团队将这些问题称为「自然对抗样本」。

模型之所以能在以往流行的 VQA 基准上表现出色,主要依赖于其过度的语言偏见(Language Bias)。为证明这一点,研究团队展示了六大基准中的一些问题,即使不查看图像也能作答。
例如,模型可以通过语言先验(Language Prior)回答诸如「马萨诸塞州的首府是什么?」(「波士顿」)和「图片中有黑色长颈鹿吗?」(「否」)这样的问题,而无需依赖图像信息。
为了解决这一问题,NaturalBench 设计了配对任务,将两幅图片与两个相反答案的问题匹配,以避免模型可以凭「盲猜」侥幸答对。

NaturalBench 通过一个简单的流程从 Flickr30K 等图文数据集中构建,具体步骤如下:
1. 找出 CLIP 无法正确匹配的图文对。
2. 使用 ChatGPT 为每个图文对生成相反答案的问题。
通过避免对图像或问题进行非自然干扰,NaturalBench 生成了自然的对抗样本。这些样本基于自然图像提出的问题,人类可以轻松理解并回答,但对模型来说却极具挑战性。
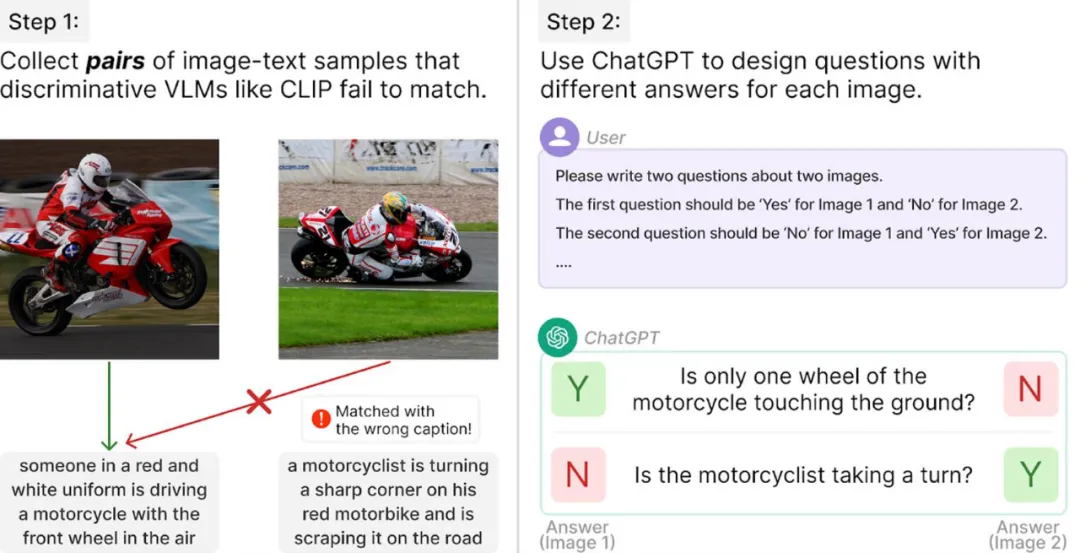
通过该流程及人工质检,研究团队最终收集了 10,000 个高质量 VQA 样本,用于可靠评估视觉语言模型。
基于 NaturalBench 中「两张图片 + 两个问题」配对的格式,研究团队提出了更可靠的视觉为中心评估指标 ——Group Accuracy (G-Acc)。只有当模型正确回答一个样本中的所有四个(图片、问题)组合时,才能得一分。
研究人员发现了以下重要的实验结论:
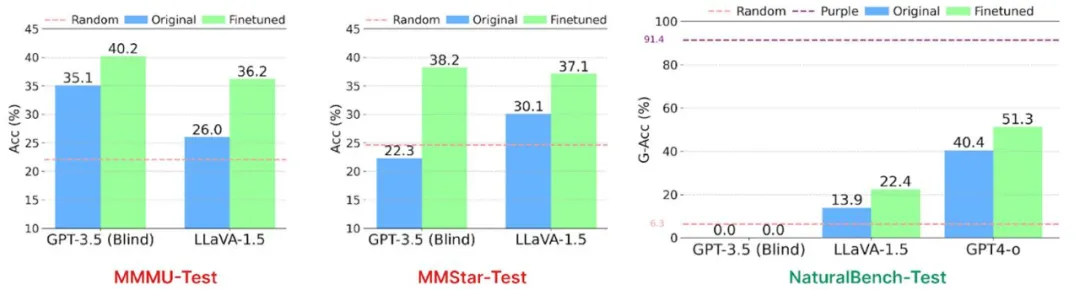
1、先前的 VQA 基准存在盲猜问题:流行的 VQA 基准,(如 MME 和 ScienceQA)可以通过微调不具视觉能力的 GPT-3.5 来解决,其表现甚至超过了经过视觉微调的 LLaVA-1.5。然而,在 NaturalBench 上,这种「盲猜」模型只能得到零分!
这表明,当前的视觉语言模型可能在视觉问答任务上依赖强大的语言盲猜能力「浑水摸鱼」。
2、当前开源模型的表现有限:研究团队对 53 个视觉语言模型进行了测试,结果显示,大多数开源模型(如 BLIP-3、Cambrian-1、LLaVA-OneVision、Llama3.2-Vision、Molmo 和 Qwen2-VL)的得分仅比随机水平高 10%-20%。即使是经过视觉微调的 GPT-4o,其表现仍比人类低 50%。
这表明,目前的视觉语言模型在自然图像的视觉理解能力上还有巨大提升空间。

研究人员对提升视觉语言模型的方向进行了探讨,并发现两个重点:
1、让大模型不再「盲选」:大多数模型失败的关键在于,无论图像内容如何,它们总是盲目选择相同的选项。在 GPT-4o 出错的问题中,超过 80% 是因为模型在任何图像下都选择了同一答案(如「是」)。研究人员发现,纠正这一倾向后,模型性能可提升两到三倍!
研究团队采用了一种基于评分的评估方式(VQAScore),通过调整同一问题下两个不同选项的得分差,确保模型在回答「是」和「否」时的比例保持一致。仅凭这一简单调整,像 GPT-4o 这样的强大模型的表现几乎翻了两倍!
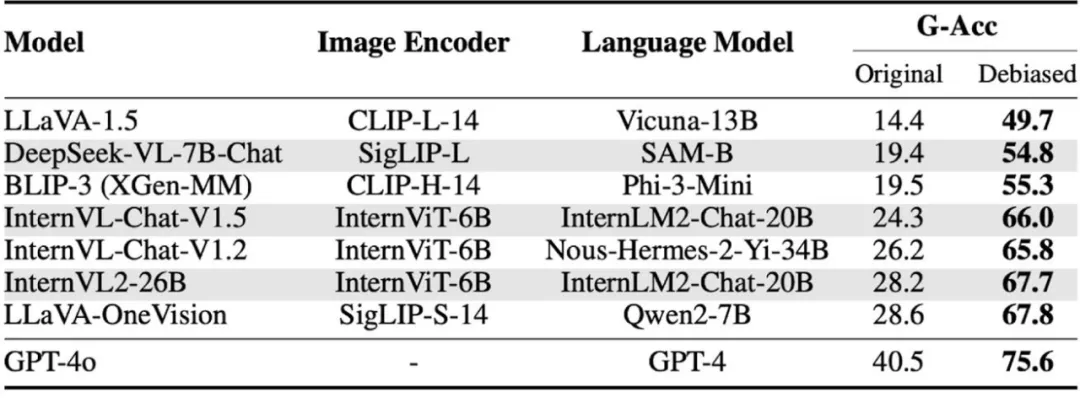
这意味着 NaturalBench 可以作为一个纠正模型偏见的基准,帮助减少模型的盲猜行为和幻觉问题。
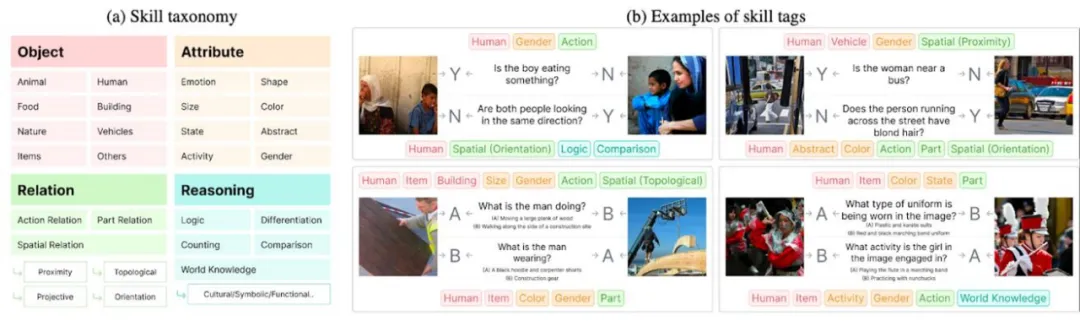
2、大模型仍需提升组合性思维(compositional reasoning)能力:NaturalBench 的大部分问题要求模型同时具备多种视觉技能(compositional reasoning),包括对象(object)、属性(attribute)、关系(relation)和逻辑(logic)等维度。
为此,研究团队为 NaturalBench 中的每个问题标注了 1 到 8 个技能标签,对组合推理能力进行了细致评估。结果表明,即便是 GPT-4o,在空间关系、逻辑推理等方面仍有显著的提升空间。
传统机器学习模型在静态基准上追平人类表现通常需要多年,例如 MNIST 用了 15 年,ImageNet 用了 7 年。然而,由于当前大模型大量使用互联网数据,数据集泄露使新基准在数月内就可能过时。因此,近期研究提倡动态评估(Dynamic Evaluation),常见的方法是通过人机协作(human-and-model-in-the-loop)收集对抗样本。
例如,Adversarial NLI 和 Dynabench 要求标注者不断设计难题使模型出错,而 Adversarial VQA 让标注者为图片反复生成问题,直到模型失败。
相比之下,NaturalBench 不针对特定 VQA 模型,且只需标注者一次性验证,大大提高了动态基准构建的效率。研究团队还使用先进的 LongCLIP 等模型,从 DOCCI 和 XM3600 数据集中收集了更复杂且多语种的 VQA 样本,证明了 NaturalBench 在未来大模型的动态评估中具有广泛的适用性。
最后,NaturalBench 数据集已经开源:https://huggingface.co/datasets/BaiqiL/NaturalBench/
期待未来更加强大的视觉语言模型问世!
文章来自于微信公众号“机器之心”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
